
Mem0 - Building Production-Ready AI Agents with Scalable Long-Term Memory
[!Mem0 记忆管线的黑话]
- extraction phase: 从新一轮对话里提炼候选事实, 写入路径的第一步
- update phase: 候选事实和已有记忆对账, 决定 ADD / UPDATE / DELETE / NOOP
- : extraction 吐出的候选记忆集合
- : 异步刷新的全局对话摘要, 提供"远景"
- tool call: LLM 自己选操作并执行的 function-calling 接口
- Mem0: 把记忆表示从自然语言换成知识图谱的变体
Mem0 在 memory 光谱里的位置
agent memory 这一堆框架, 区分它们最有用的是两个轴: 记忆的表示 (自然语言 / 向量 / 图 / 时序图) 和记忆的生命周期 (写入 检索 更新 遗忘);
Mem0 base 在表示这一轴上是最朴素的一档: 记忆就是一条条自然语言 fact, 存在一个普通向量库里, 检索走 RAG 式的 ANN; 论文原话是向量库 “employs dense embeddings to facilitate efficient similarity search”, 所以平时说的 “Mem0 dense” 并不是论文给的变体名 (论文只有 Mem0 和 Mem0 两个名字), 而是借 IR 里 dense retrieval 的说法指代它——用稠密向量 embedding 做语义检索, 区别于 BM25 那种 sparse retrieval; 它真正下功夫的地方在生命周期这一轴——怎么选择性地写, 怎么在矛盾时更新和删除;
这里要先把一个很容易混的东西拆开:
- 写入路径 (memory formation): 对话来了, 怎么把它变成记忆并维护好——也就是 extraction + update 这两个 phase
- 读取路径 (retrieval): 用户提问时, 怎么从库里捞出相关记忆塞进 prompt
本篇只讲写入路径, 因为这才是 Mem0 真正做"管理"的地方; query 时的检索注入是另一条独立的 RAG 链路, 不在这两个 phase 里;
论文定位
Mem0 不是一个新模型, 不是新的 attention 变种, 也不是一个新的存储引擎; 它是一个架在普通向量库之上的 memory management pipeline; 核心主张是:
- 与其每轮把整段对话历史塞回 context (full-context, 又贵又会超窗), 不如让 LLM 增量地把对话蒸馏成结构化 fact
- 让 LLM 自主维护这些 fact, 该加的加, 该改的改, 该删的删
- 整套维护尽量不拖慢主链路
顺手把一个常见误解先纠了: base Mem0 的创新不在"记忆的内部结构", 而在"记忆的数据流和操作策略" 加上一组很强的 empirical 结果; Mem0 只是把同一套流程的表示换成图, 不是"更高级的正确答案"; 这点后面专门展开;
论文解决的核心问题
现有方案的不足:
- full-context: 每轮把全部历史重喂, 吃 的 attention 成本, token 账单线性膨胀, 而且对话够长仍然会超窗
- 朴素 RAG 记忆 (无脑 append): 只增不删, 矛盾的事实共存, 冗余不断堆积, 检索质量随时间退化成垃圾场
- 固定摘要: 压是压下去了, 但丢细节, 而且不区分"该记 vs 不该记"
Mem0 试图回答:
- 怎么只把值得记的抽出来, 而不是整段塞进去?
- 新事实和旧记忆矛盾 / 重复时, 谁来裁决加改删?
- 这套维护怎么做到不拖慢主链路?
两阶段总览
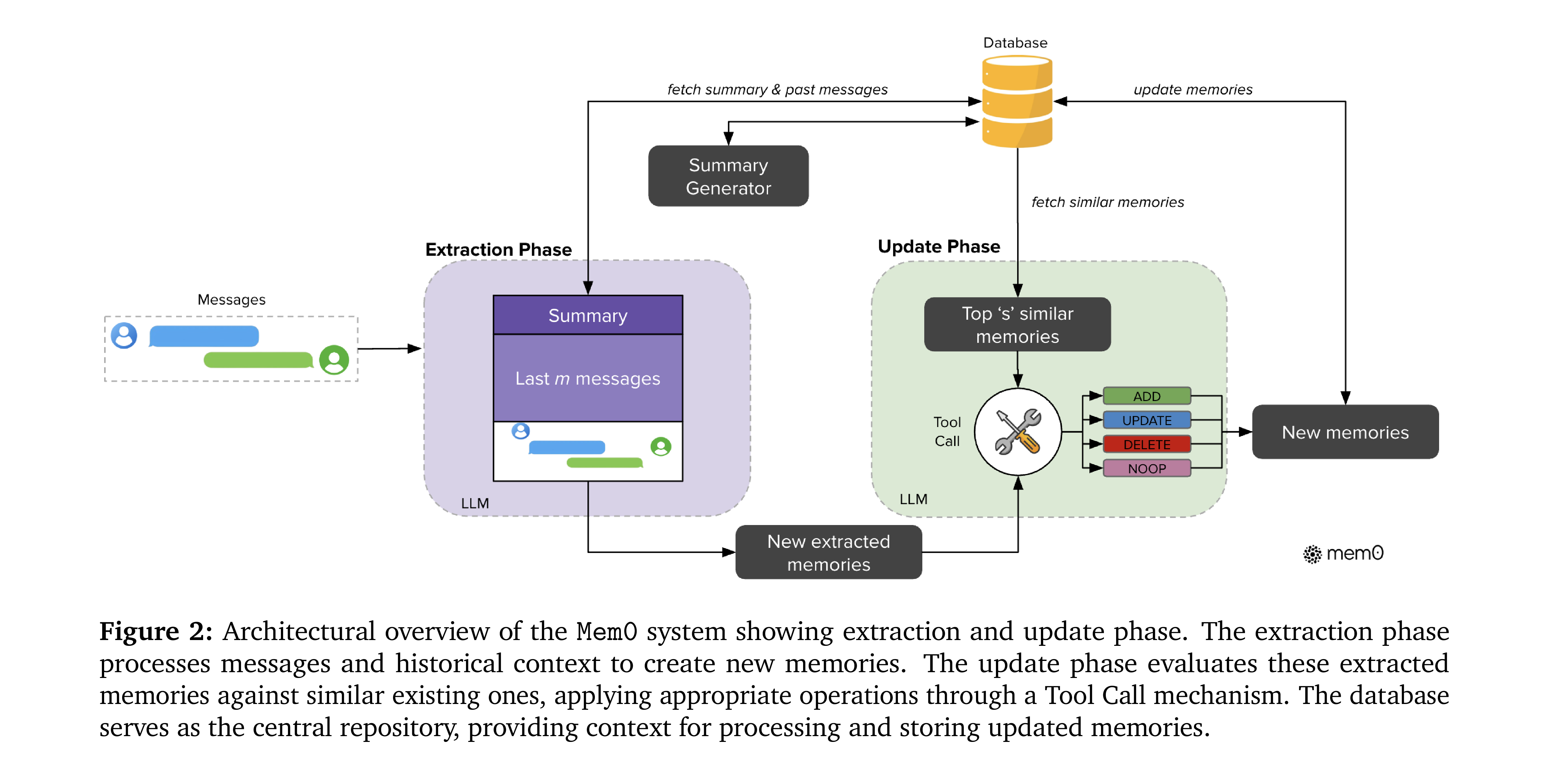
原论文 Figure 2: Mem0 写入路径的总览 — 左半 Extraction Phase 把 Messages 连同 Summary 和 Last messages 一起喂给 LLM, 吐出 new extracted memories; 右半 Update Phase 对每条候选去 Database 取 Top- similar memories, 再由 LLM 通过 Tool Call 选 ADD / UPDATE / DELETE / NOOP; 中间那个 Database 和异步的 Summary Generator 是两个 phase 共享的基础设施; 这张图是下面 extraction / update 两节的视觉总索引;
一句话读图: 写入路径 = Extraction (提炼候选) Update (对账落库), 中间隔着一个向量库, 旁边挂一个异步摘要器;
Extraction Phase: 在全局背景下只抽新一轮
直觉先行: 这一步像开会时做会议记录——你只记"刚才这一轮说了啥", 但记的时候脑子里得装着整场会的背景, 否则容易记歪, 把代词指错人, 把上下文丢掉;
所以抽取函数 吃的不是一条孤立消息, 而是三路上下文拼成的 prompt:
- 当前消息对 — 真正要抽取的焦点, 也就是最新这轮 user 和 assistant 的交换
- 对话摘要 — 浓缩整段对话历史语义的远景
- 最近消息窗口 — 提供近期局部的近景, 超参
设计意图很干净: 摘要给远景, 滑窗给近景, 消息对是焦点; 后两路只是给抽取提供背景, 它们本身不会被重新抽取——每轮只处理新增内容, 而不是把整段历史每次重抽一遍, 这是个增量设计;
产出一组候选记忆:
论文强调它们 “specifically from the new exchange”, 并且是 candidate facts——注意是候选, 不是直接入库;
这里有两个容易看走眼的点:
- 摘要 是异步生成的: 由一个独立于主链路的模块周期性刷新, 抽取时直接读一份"够新但不保证最新"的缓存摘要, 而不是同步等一次 summarization; 这是典型的用一点 staleness 换 latency
- 近期窗口不是"筛"出来的: 就是按时间卡最近 10 条, 纯机械滑窗, 没有 LLM 参与; 真正的 LLM 自主判断只发生在 决定"哪些 salient"这一步
extraction 只负责产候选, 不去重不消解, 脏活全部留给 update;
Update Phase: 让 LLM 自己当记忆管理员
候选 不能直接灌库, 得先和库里已有的记忆对账; 这一步是 Mem0 真正"管理"记忆的地方;
机制上, 对 里每一条 , 先用 vector embedding 检索 top- 条语义最相似的旧记忆 (); 注意是逐候选做的, 不是把整个 一把去比;
拿到"候选 + 它的 10 个邻居"之后, LLM 在四个操作里选一个:
| 操作 | 触发条件 (论文原话) | 直觉 |
|---|---|---|
| ADD | no semantically equivalent memory exists | 没匹配 新建 |
| UPDATE | augmentation of existing memories with complementary information | 匹配且互补 把新信息补进去 |
| DELETE | removal of memories contradicted by new information | 新信息和旧记忆矛盾 删掉旧的 |
| NOOP | candidate fact requires no modification | 不需要动 什么都不做 |
最关键的是 DELETE: 很多人会把它和 UPDATE 揉在一起, 但两者语义不同——UPDATE 是互补 (旧记忆没错只是不全), DELETE 是矛盾 (新信息推翻旧记忆); 这俩是不同的语义关系;
实现上还有两个要点:
- 没有独立分类器: 论文明说 “rather than using a separate classifier, we leverage the LLM’s reasoning capabilities to directly select the appropriate operation”; 也就是 LLM 在 context 里直接推理语义关系来选操作
- 裁决和执行一气呵成: 选哪个操作是通过 function-calling (tool call) 暴露的, LLM 选完, 系统紧接着执行并改写向量库以 “maintain knowledge base coherence”; 这就是 LLM-as-memory-manager——LLM 既当裁判又当执行者
正是 DELETE 加 NOOP 让 Mem0 区别于"只增不删的朴素 RAG 记忆"——它真正在做 consolidate (合并) 和 forget (遗忘), 这才是"管理"区别于"堆积"的地方;
Mem0: 同一套骨架, 把表示换成知识图谱
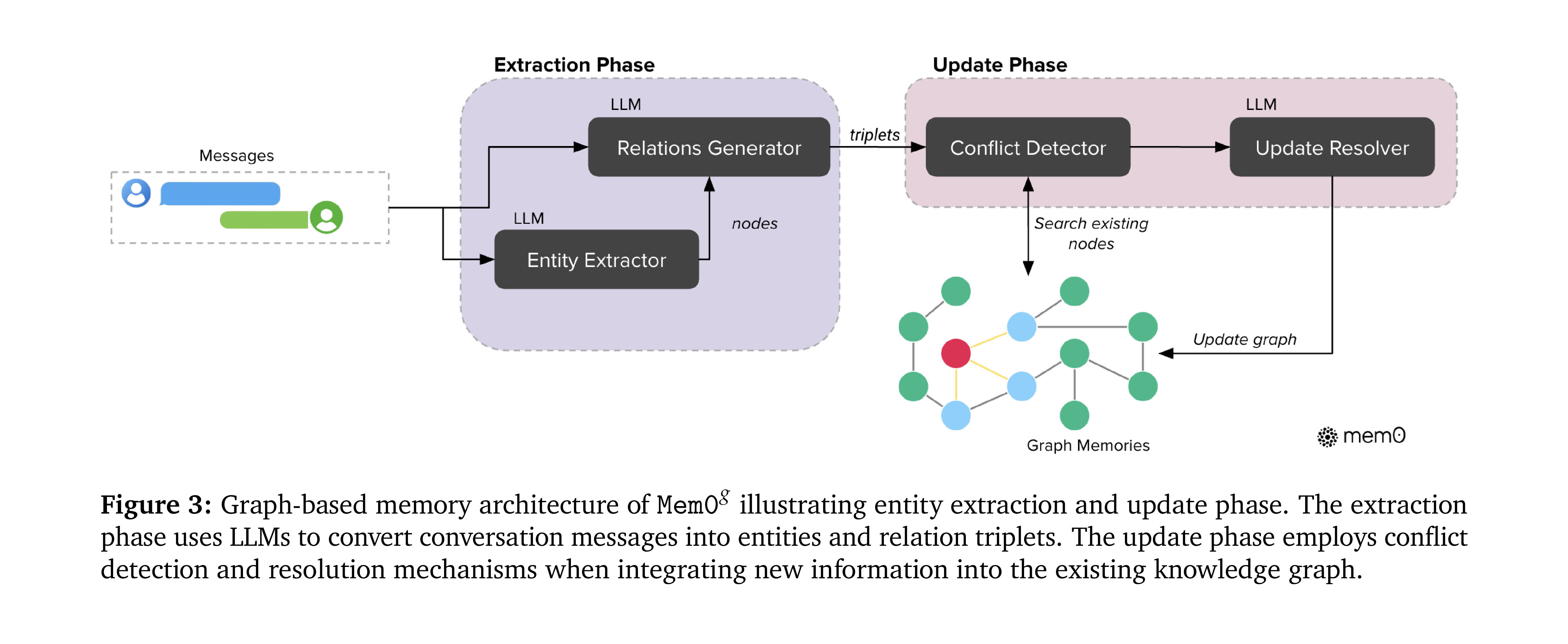
原论文 Figure 3: Mem0 的图记忆架构 — Extraction Phase 拆成两段, Entity Extractor 先从消息里识别实体 (nodes), Relations Generator 再生成关系 triplets; Update Phase 用 Conflict Detector 对着已有 graph nodes 查矛盾, 再由 Update Resolver 合并进图; 对比 Figure 2 看, 抽取→对账的骨架没变, 变的只是记忆的表示;
Mem0 不是另起炉灶, 而是把同一套"抽取 对账"骨架整体换成图原生实现; 注意一个常见误解: 它不再用 base 那套 ADD / UPDATE / DELETE / NOOP 的 tool call, 而是两边机制都被换掉了;
节点 (node) 由四部分构成: 实体名, 实体类型 (Person / Location / Event 之类), 语义 embedding , 以及 metadata (创建时间戳 ); 其中类型是 LLM 分类出来的, 而 embedding 是算出来的, 时间戳是系统盖的——不是都靠 LLM “认”, 所以"node 的 type/metadata 认识"这句只有 type 那一半归 LLM;
抽取变成两段式: Entity Extractor 先识别实体加类型 (产 nodes), Relations Generator 再用 LLM 从实体和上下文里生成关系三元组 (产 edges); 两段都是 prompt 驱动的 LLM stage, 是"先抽实体再抽关系", 不是对边做什么强化;
写入侧 (add) 靠相似度阈值解析节点: 对每条新 triplet, 给源实体和目标实体各算 embedding, 在已有节点里搜语义相似度超过阈值 的; 按节点是否已存在, 系统或建两个新节点, 或建一个, 或复用已有节点, 然后再连边——这一步替代了 base 的 top- 检索加四操作;
更新侧靠冲突检测 + 软失效: 新信息进来时 Conflict Detector 找出可能冲突的旧关系, 再由一个 LLM-based update resolver 判断哪些该作废; 关键在于它只把旧关系标记为 invalid, 不物理删除 (“marking them as invalid rather than physically removing them to enable temporal reasoning”);
[!base 硬删 vs Mem0g 软失效]
- base Mem0 的 DELETE 是硬删: 矛盾就把旧 fact 抹掉
- Mem0 是软失效: 旧关系打 invalid 标记后保留, 配合时间戳就能做时序推理 (用户"以前在 A 公司, 现在在 B 公司", 两条都留, 旧的标 invalid)
- 这正是 Mem0 开始向 Zep / Graphiti 那种时序知识图谱靠拢的地方; base Mem0 没有这个能力
对应回 memory 的"表示"轴, 这是从 vector 挪到 graph 的一步; 而软失效加时间戳, 又在"生命周期"轴上多点亮了 temporal reasoning;
但图不是免费的: 论文自己的数据显示, graph 版在多数任务上性价比并不划算 (检索约慢 3x, token 约贵 2x), 主要在关系 / 多跳 / 时序查询上才显出优势; 所以别把 Mem0 当成"更高级的正确答案", 它是一个用更高成本换关系推理能力的 trade-off 变体;
base vs Mem0
| 维度 | Mem0 (base) | Mem0 |
|---|---|---|
| 记忆表示 | 自然语言 fact | 实体 + 关系三元组 |
| 存储后端 | 向量库 (dense embedding) | 图库 (节点带 embedding) |
| extraction 产物 | (NL facts) | nodes (实体+类型) + relation triplets |
| 写入/更新机制 | top- 检索 + 四操作 tool call (ADD/UPDATE/DELETE/NOOP) | 阈值 节点解析 (建/复用) + Conflict Detector |
| 删除语义 | 硬删 (物理移除) | 软失效 (mark invalid, 留作时序推理) |
| 强项 | 通用 QA, 低延迟低成本 | 关系 / 多跳 / 时序推理 |
| 代价 | 关系推理偏弱 | 更慢更贵 |
Mem0 vs MemGPT: 管理知识 vs 管理上下文
两篇都顶着"给 LLM 加记忆"的帽子, 但解决的根本不是一回事; 一句话区分: MemGPT 管的是"上下文" (raw content 放在哪), Mem0 管的是"知识" (该记哪些 fact, 怎么对账);
| 维度 | MemGPT | Mem0 |
|---|---|---|
| 记忆是什么 | 原始内容本身 (messages / 文档 / 自写笔记), 分层放在 main / external context | 从对话蒸馏出的结构化 fact (NL 或图) |
| 核心动作 | 分页 (paging): 在 RAM (窗口) 和 disk (外部库) 之间搬运 raw content | 抽取 + 对账: 提炼候选 再 ADD / UPDATE / DELETE / NOOP |
| 谁来管, 何时管 | LLM 自己在推理回合里用 function call 主动触发 (interrupt / heartbeat 驱动), 模型即 kernel | 一条独立的后台 pipeline, LLM 只是其中的工具 (抽取器 / 裁决器) |
| 目标 | 把有限窗口撑成看起来无限, 服务单 session / 长文档 | 跨 session 的持久, 去重, 无冲突长期记忆, 抠成本和延迟 |
| 对待冗余 / 矛盾 | 不主动去重, 旧内容 FIFO 归档后可召回 | 显式 DELETE / NOOP 做 consolidate 和 forget |
你的直觉基本对, 但要拧准两处:
- ✅ “MemGPT 提出怎么管理近乎无限的上下文, 靠 compact” —— 对; 它本质是虚拟内存式的 context paging, 外加 LLM 自己做 summarize 和归档
- ✅ “内存管理依靠 LLM 主动 summarize” —— 对; MemGPT 的 compaction 是模型自发的 (working context 自编辑, FIFO 满了递归摘要), 这正是它的 agentic 特征
- ⚠️ “MemGPT 没有 Mem0 那种全局 S 加近期记忆的择优思路” —— 半对; MemGPT 其实也有"摘要 + 近期 + 检索"三件套 (working context = 自维护摘要, FIFO = 近期消息, archival = 按需检索), 但它把这三样组织成模型在其间分页的存储层级, 而不是 Mem0 那种"在三路上下文背景下, 把新一轮择优蒸馏成 fact"的抽取配方; 一句话: MemGPT 搬运 raw content, Mem0 把 content 提炼成去重的 fact
所以更准的对照是: MemGPT = 给单个 agent 一块"看起来无限的工作记忆", 模型自己当内存管理员, 管理动作内联在推理回合里; Mem0 = 给系统一个"可扩展的长期知识库", 用一条离线 pipeline 把对话沉淀成干净 fact, 管理动作和推理解耦; 一个偏 OS 的 virtual memory, 一个偏数据工程的 ETL 加去重;
题外话: 图记忆底下的图数据库 (Neo4j)
Mem0 这种图记忆落到工程上需要一个图数据库来存节点和关系边, Neo4j 是最主流的选择 (Graphiti / Zep 也支持它, 以及更轻的 FalkorDB);
Neo4j 是 property graph 模型: 节点带 label 和 properties, 关系有向, 有类型, 还能带属性, 用声明式查询语言 Cypher (MATCH (a:Person)-[:KNOWS]->(b) 字面就是把要找的模式画出来); 分类上它属于 NoSQL 的图家族 (key-value / document / column-family / graph 四大家族之一), 但和早期 NoSQL 不同, 它是完整 ACID 事务;
它最关键的优点是 index-free adjacency (免索引邻接): 每个节点直接存着指向邻居的指针, 多跳遍历就是顺着指针一步步走, 而不是关系库 (MySQL / PostgreSQL 这类) 里那种一层套一层的 JOIN;
| 关系型 JOIN | 图遍历 (Neo4j) | |
|---|---|---|
| 跟一条关系 | 索引查找 , = 表大小 | 跟指针 |
| k 跳查询 | k 次自连接, 中间结果组合爆炸 | 代价 实际走过的节点 / 边数 |
| 代价随什么涨 | 整个数据集大小 | 只随局部邻域大小 |
| 变长路径 | 要写递归 CTE, 笨且慢 | 原生 -[:KNOWS*1..5]-> |
一句话: 关系型 JOIN 的代价随数据总量涨, 图遍历只随你实际访问的那一小片涨; 数据越大, 跳数越深, 图库优势越明显——这正是"多跳关系推理"型图记忆 (Mem0 / Zep) 选它的底层原因; 但要诚实, 浅 JOIN (1~2 跳) 且索引建好时关系库并不慢, 图库真正的胜场是深度 / 递归 / 变长遍历;
几个值得留意的设计点
- 异步摘要 = 把 summarization 成本从关键路径摘出去, 一个很 systems 的 latency-staleness 取舍
- extraction 和 update 关注点分离: 一个只"看新内容提炼", 一个只"对账旧库裁决", 边界干净
- 写入路径 读取路径: 这两个 phase 全在写入侧 (记忆形成); query 时还有一条独立的 RAG 检索注入路径, 别混
- LLM-as-memory-manager 的隐性成本: 每条候选都要一次"检索 + LLM tool call", 写入不再便宜——这反过来解释了为什么异步摘要和选择性抽取这么关键
- 它本质是 policy 创新而非 mechanism 创新: 向量库, embedding, function calling 全是现成件, Mem0 的价值在于怎么把它们编排成一条写入管线, 并证明这套编排在 LOCOMO 上打赢 full-context 和其他记忆系统
如果按论文主线浓缩, Mem0 的主流观点可以总结为:
- agent 长期记忆的瓶颈不是"存不下", 而是"怎么选择性地记 + 持续地维护"
- full-context 不可持续 (成本和窗口), 朴素 RAG append 会越长越脏, 两条都不是答案
- 把记忆形成拆成 extraction (提炼候选) 和 update (LLM 对账) 两段, 是一条干净且可扩展的写入管线
- 让 LLM 自己用 tool call 做 ADD / UPDATE / DELETE / NOOP, 一次推理同时完成裁决和执行, 比独立分类器更灵活
- DELETE 和 NOOP 是关键: 它们带来 consolidate 和 forget, 这才是"管理"区别于"堆积"的地方
- Mem0 不是 base 的升级版, 而是把表示换成图的 trade-off 变体, 用更高成本换关系 / 时序推理能力
- 整篇的贡献是 systems / design 加 empirical, 而不是新的记忆"机制"或"架构"——这恰恰是它 production-ready 定位的由来