
ZeRO - memory optimizations toward training trillion parameter models
- Vertical Split: 竖切, PP
- Horizontal Split: 横切, TP
消耗显存的模块分类
| Part | Category | Included Items | Description |
|---|---|---|---|
| 1 | Model states | optimizer states, gradients, parameters | For large models, the majority of the memory is occupied by model states. |
| 2 | Residual states | activation, temporary buffers, unusable fragmented memory | The remaining memory is consumed by residual states. |
Model State 不足分析 + ZeRO-DP 性能
| Parallelism Method | Why Compute Efficiency Is High / Low | Why Memory Efficiency Is High / Low | Core Mechanism | Main Problem |
|---|---|---|---|---|
| Data Parallelism (DP) | High compute efficiency because each GPU runs the full model independently on its own mini-batch, so computation is large-grained and continuous, and communication is mainly limited to gradient synchronization. | Low memory efficiency because each GPU stores a full copy of all model states, including parameters, gradients, and optimizer states. | Replicate the full model on every GPU, split data across GPUs, then synchronize gradients. | Heavy memory redundancy across GPUs. |
| Model Parallelism (MP) | Low compute efficiency because one model computation is split across multiple GPUs, which introduces fine-grained coordination, frequent synchronization, and expensive communication on the critical path. | High memory efficiency because each GPU stores only a partition of the model states instead of the full model. | Partition the model itself across GPUs so each GPU holds only part of the parameters / states. | Communication overhead, synchronization cost, and reduced scalability. |
| ZeRO-DP | Tries to retain the high compute efficiency of DP by preserving DP-style computation granularity and communication pattern as much as possible. | Tries to achieve the high memory efficiency of MP by partitioning model states across data-parallel processes instead of fully replicating them. | Keep DP-style training flow, but partition optimizer states, gradients, and eventually parameters to remove redundancy. | More complex state management and dynamic communication scheduling. |
Residual State 不足分析 + ZeRO-R 性能
| 优化对象 | 问题 / 瓶颈 | ZeRO-R 的做法 | 目标 |
|---|---|---|---|
| 激活值(activations) | 大模型中, checkpointing 虽然有帮助, 但仍然不足; 现有 MP 方法中还存在 activation replication | 通过 activation partitioning 识别并消除激活值复制; 在合适的时候将 activations 卸载到 CPU | 降低 activation memory 占用 |
| 临时缓冲区(temporary buffers) | 临时缓冲区大小如果设置不当, 会影响内存与计算效率的平衡 | 为 temporary buffers 选择合适的大小 | 在内存占用和计算效率之间取得平衡 |
| 内存碎片(fragmented memory) | 不同 tensor 生命周期不同, 导致训练中出现内存碎片; 即使总空闲内存足够, 也可能因缺少连续内存而分配失败 | 根据不同 tensor 的生命周期主动管理内存, 防止 memory fragmentation | 减少碎片化, 避免内存分配失败 |
Mixed-Precision Training
在训练的时候,为了能有更加轻量级、快速、小内存的目标,工程界往往会引入压缩精度的方法,也就是用 FP16 来代替 float32 和 float64;
但是为了目标节点的计算精度保持,优化器可能会用高精度版本保存一定的关节参数, 这个过程就叫做混合精度训练
空间复杂度分析
定义 是模型参数总数,比如一个 7B 模型就表示参数总量是 B, 一般系统的内存总占用需要的是 精度位数 * 参数总量,比如我们统一用 FP16 的话,得到的内存总占用就是 bytes
Adam Optimizer 显存占用
根据论文的说法,adam 优化器的显存占用主要是如下内容:
fp16parameters: 用于 forward/backward 的低精度模型权重fp16gradients: 用于 step backward 传播后算出来的梯度fp32master weights: 同一个参数 (parameters) 的高精度主副本,拿来真正做参数更新的,低精度的更多只是用来算 forward 和 backward 的fp32momentum: 这是 adam 优化器的一阶矩,记录的是最近一段时间这个参数的梯度方向趋势fp32variance: 粗略理解就是梯度的平方的趋势,记录最近的梯度的尺度和波动强度
从上述列表可以看出,优化器的显存可以分为两类,一类是用来做运算传播的,另一类高精度是用来做模型参数更新的,如果从训练的角度来看,更新参数是最直观可以从训练运算过程中解耦的,也就是我们不影响数据流向,先考虑把模型参数这种重量级不动产先解耦出来去除冗余
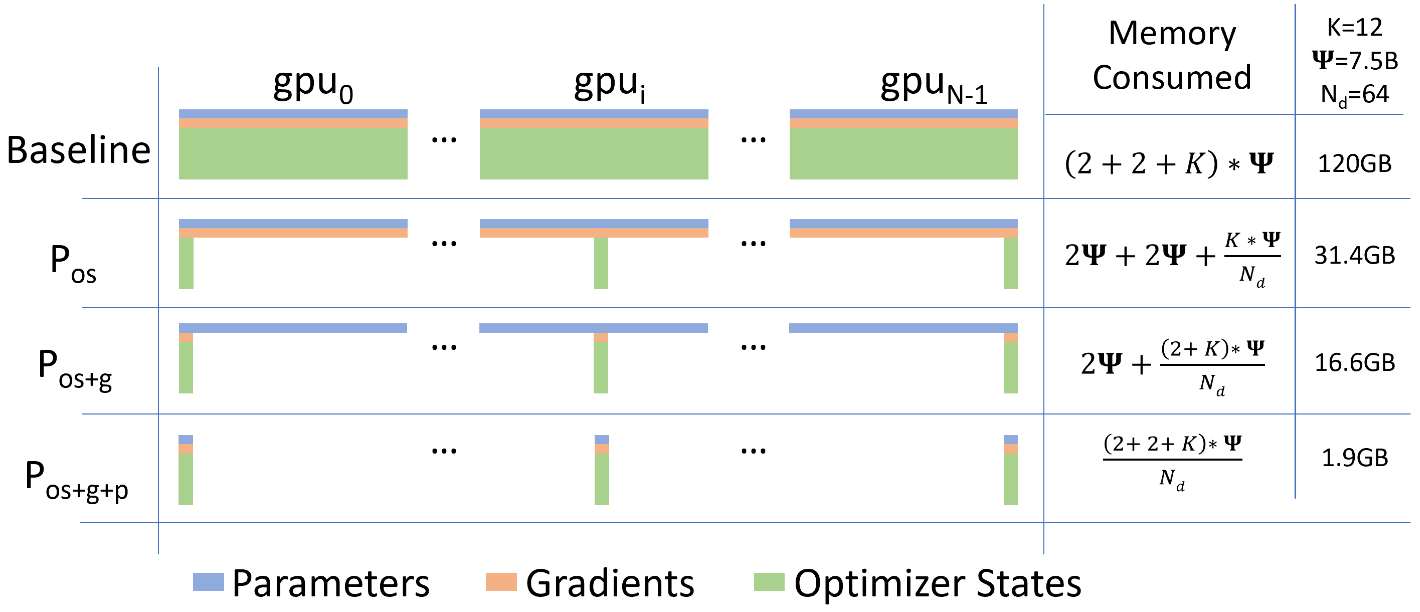
ZeRO-1: Optimizer State Partitioning
接上文逻辑,为了让每一组显卡不需要对所有高精度参数都做更新,这里就让局部参数可以更新,也就是将一个分布式训练系统分成 等分,每个 data-parallel rank 只负责 份参数区域的更新,最后做一组 all-scatter 就获得了全部的状态更新;
按照这个设计, 我们先假设这里 Optimizer 用到的额外字节数是 bytes (根据上面的 adam 案例就是 12 bytes) 参数,那么根据 ZeRO-1 的设计我们最终的压缩得到的参数尺寸就是 bytes
注意在这一步中,所有显卡仍然拿到完整的数据并且计算完整的梯度,然后按照经典的 DDP 协议通信来实现 all-reduce 得到全局统一梯度,只是在更新数据的时候有选择地更新自己 rank 负责的数据
ZeRO-2: Gradient Partitioning
在这一步已经将参数层面切分开了,但是优化器中的梯度分区是和参数分区一一对应的,所以这里就会有一个优化角度: 将每个 rank 分区的梯度也轻量化,或者说每个分区只负责一部分的梯度计算,也只需要接受相关梯度分区的传递数据,下面用一个例子来辅助说明:
对于一个二分区系统,我们有 rank0 和 rank1 来对数据做计算: rank0 负责分区 A rank1 负责分区 B;
按照这个设计,我们这里的 gradients 的内存占用就从 2 变成 bytes 了
这里每个 rank 只算本地的梯度了,算完之后对梯度做分区的 reduce
ZeRO-3: Parameter Partitioning
接下来就是顺理成章地轻量化 parameter 部分了,也就是只需要计算、传递和自己相关的部分的梯度吧