
Megatron-LM - Training Multi-Billion Parameter Language Models Using Model Parallelism
Attention 计算的线性代数问题
attention 和 FFN 的关系
如果记某层输入为 x, 那么可以粗略理解成:
- attention 输出: 给 x 补充上下文信息, 像"开会听别人说话"
- FFN 输出: 给 x 补充局部计算后的新特征, - 像"你自己在脑子里消化, 归纳, 形成判断"
如果我们尝试把一个 FFN 层变成一个 attention 层, 结果就是可能会更加适合长距离语义传输但是缺少本地语义特征变换器
多层 attention-FFN 结构
可以理解为不断重复"交换信息 消化信息 再交换 再消化"
也就是说各自对本 token 处于上下文的含义理解之后再次进行交换分享,让整体的文意理解更加深刻
Transformer 架构的训练计算
假设训练句子是:The capital of France is Paris.
训练时,decoder-only 模型会把它转成一种“前缀预测后一个 token”的形式, 比如模型看到:
- The,目标是预测 capital
- The capital,目标是预测 of
- The capital of,目标是预测 France
- …
- The capital of France is,目标是预测 Paris
如果模型想正确预测 Paris,它会发现: - 光看 “is” 不够
- 更该关注 “France”
- 还要结合 “capital of”
那么训练多了以后,某些 attention head 就会学出一种模式: - 当遇到 “capital of X is” 这种上下文
- 应该把更多权重给国家/地区名 token 和相关提示词
于是 attention 权重和 Q/K/V 的参数就逐渐往这个方向调整。
这里的实现我们应该会放到 CS336 Assignment1 的实现里面去讨论;
注意力矩阵和计算
现在我们有一个 attention 的输入 :=[hello, world] 然后我们计算这里的 QKV 矩阵分别的公式就是: , …, 所以如果我们拆分这里的计算来看, X 要保证输出的 Q 中最好要有与其输入 token 一一对应的行或者列, 也就是 要么按照行区分要么按照列区分, 但是根据这个公式来看 X 是放在左边的(这个更像是一个工程习惯, 因为工程上比较习惯把 batch 维度, 也就是输入向量的个数放到 的前一个维度来看, 因此是左参数右权重), 所以我们有:
也就是说在 QKV 矩阵中的数值都是按照 行 进行存储的
那么接下来如果要计算 , 需要转置一个来让两个能计算 查询与关键词的匹配度, 也就是 cos 相似度/向量的数量积, 也就是 ; 下一步就是对这个匹配度进行归一化, dropout 等操作, 表达式就是
最后再接着求 V 和这里的匹配度 (权重)
接下来我们就开始讨论 Tensor Parallelism 的计算公式了
MLP 并行设计
对于一般的 MLP/FFN 设计, 形式大概写作 , 这里 A 是权重矩阵, 所以我们的并行其实就是尝试对 A 进行不同类型的切割, 从而让整个训练数据流跟随 sub(A) 进行流动
当然还有一个原因是按照 A 切割, 就是 A 是一个非常大数据量的矩阵, X 只是训练数据, 流动量没有 A 那么大所以根据 A 来进行分类切割更合理
按 col 切割
那么对于原来的计算 , 因此这里可以直接把计算分裂到两个 GPU 上去并行计算因为其实二者互不影响, 只需要在后续什么时候需要用到 综合 数据的时候再进行合并就行, 注意 其实甚至不需要在这里的非线性层合并
按 row 切割
根据这里来说, 我们的并行计算其实需要同时拆分 X 参数矩阵, 而且这里有一个问题: 如果我们要计算下一步的 , 这时候必须要等待两个部分的计算结果, 因为我们的非线性激活函数 , 所以这里需要集体算好然后全局同步最后合并 (all-reduce), 所以我们要加一个 sync point, 这种设计可能会让全局效率降低
但是这个设计不是没用的, 因为我们前面按照 col 分割的时候相当于是会把模型拆分开, 后续需要合并的时候可能是需要额外的计算的, 但是如果我们这里利用 row 分割自然合并;
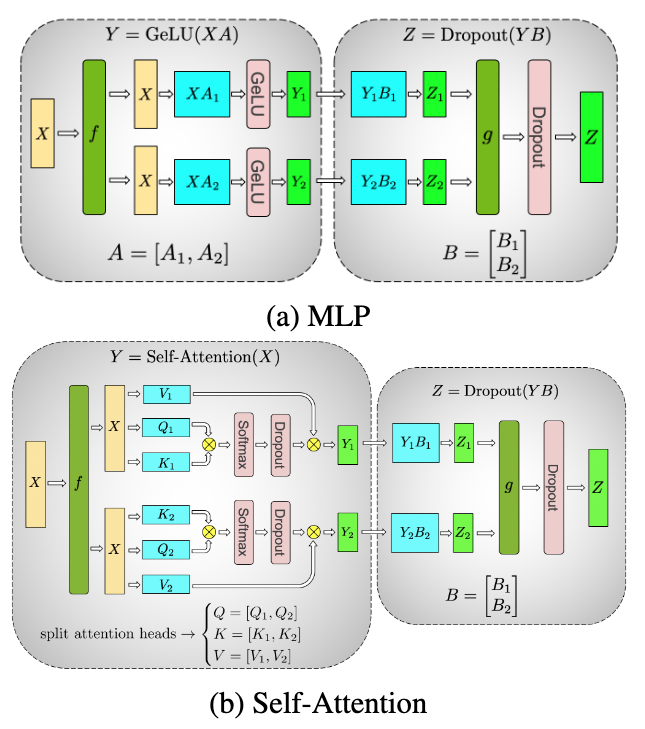
比如我们现在有一个多层 MLP: dense1 -> relu1 -> dense2 -> relu2 -> output
这时候第一个 dense1 输出是 XA, 然后经过 relu1 得到 Relu() Relu() 两个部分, 数学形式上表述为 矩阵 (假设这里逻辑上合并成一个完整的矩阵), 然后再经过 dense2 的参数矩阵 , 接下来得到 所以按照这里计算结果来看我们只需要在已经分裂的 Relu() 和 Relu() 分别和 B 的两部分相乘, 仍然可以分别处理; 只有最后经过 relu2 的时候需要把两个结果 all-reduce 到一起, 但是本来也需要这一步, 所以并行可以进一步进行;
Attention 设计
根据计算公式 Attention:= 那么这里的 GEMM 主要指的是 的计算过程, 也就是如何拆分 Q, K 矩阵; 因为从数据上来说三个矩阵的向量都是横着放的, 所以有效拆分也尽量是采用按 row 进行切割, 但是这里仍然会存在一个问题: 计算 attention 的时候是强调要对任意 token 对之间都要计算关联度的, 所以这种切割方法会导致不同 gpu 之间会存在多个通信要求, 非常复杂, 不适合训练角度实现
所以接下来研究 按照 col 进行分割的设计: 列表示的其实是不同 head 的块