
Megatron-LM - Training Multi-Billion Parameter Language Models Using Model Parallelism
Attention 计算的线性代数问题
现在我们有一个 attention 的输入 :=[hello, world] 然后我们计算这里的 QKV 矩阵分别的公式就是: , …, 所以如果我们拆分这里的计算来看,X 要保证输出的 Q 中最好要有与其输入 token 一一对应的行或者列,也就是 要么按照行区分要么按照列区分,但是根据这个公式来看 X 是放在左边的(这个更像是一个工程习惯, 因为工程上比较习惯把 batch 维度,也就是输入向量的个数放到 的前一个维度来看, 因此是左参数右权重), 所以我们有:
也就是说在 QKV 矩阵中的数值都是按照 行 进行存储的
那么接下来如果要计算 , 需要转置一个来让两个能计算 查询与关键词的匹配度,也就是 cos 相似度/向量的数量积, 也就是 ; 下一步就是对这个匹配度进行归一化、dropout 等操作, 表达式就是
最后再接着求 V 和这里的匹配度 (权重)
接下来我们就开始讨论 Tensor Parallelism 的计算公式了
MLP 并行设计
对于一般的 MLP/FFN 设计,形式大概写作 , 这里 A 是权重矩阵,所以我们的并行其实就是尝试对 A 进行不同类型的切割,从而让整个训练数据流跟随 sub(A) 进行流动
当然还有一个原因是按照 A 切割,就是 A 是一个非常大数据量的矩阵,X 只是训练数据,流动量没有 A 那么大所以根据 A 来进行分类切割更合理
按 col 切割
那么对于原来的计算 , 因此这里可以直接把计算分裂到两个 GPU 上去并行计算因为其实二者互不影响,只需要在后续什么时候需要用到 综合 数据的时候再进行合并就行,注意 其实甚至不需要在这里的非线性层合并
按 row 切割
根据这里来说,我们的并行计算其实需要同时拆分 X 参数矩阵,而且这里有一个问题: 如果我们要计算下一步的 , 这时候必须要等待两个部分的计算结果,因为我们的非线性激活函数 , 所以这里需要集体算好然后全局同步最后合并 (all-reduce), 所以我们要加一个 sync point, 这种设计可能会让全局效率降低
但是这个设计不是没用的,因为我们前面按照 col 分割的时候相当于是会把模型拆分开,后续需要合并的时候可能是需要额外的计算的,但是如果我们这里利用 row 分割自然合并;
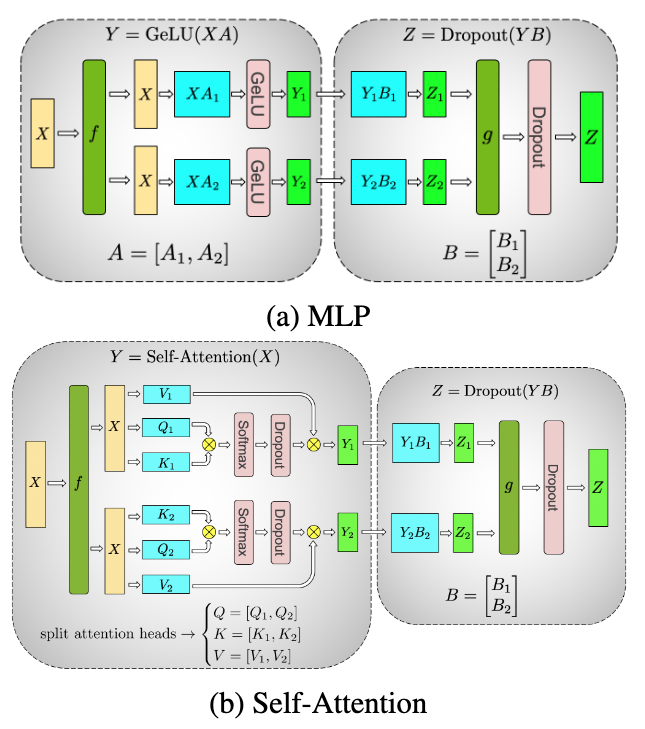
比如我们现在有一个多层 MLP: dense1 -> relu1 -> dense2 -> relu2 -> output
这时候第一个 dense1 输出是 XA, 然后经过 relu1 得到 Relu() Relu() 两个部分, 数学形式上表述为 矩阵 (假设这里逻辑上合并成一个完整的矩阵),然后再经过 dense2 的参数矩阵 , 接下来得到 所以按照这里计算结果来看我们只需要在已经分裂的 Relu() 和 Relu() 分别和 B 的两部分相乘,仍然可以分别处理; 只有最后经过 relu2 的时候需要把两个结果 all-reduce 到一起,但是本来也需要这一步,所以并行可以进一步进行;