0. 基本 GPU 架构
Data-Level Parallelism (DLP)
在前面的工作中我们主要学习的 并行架构 就是 pipelining
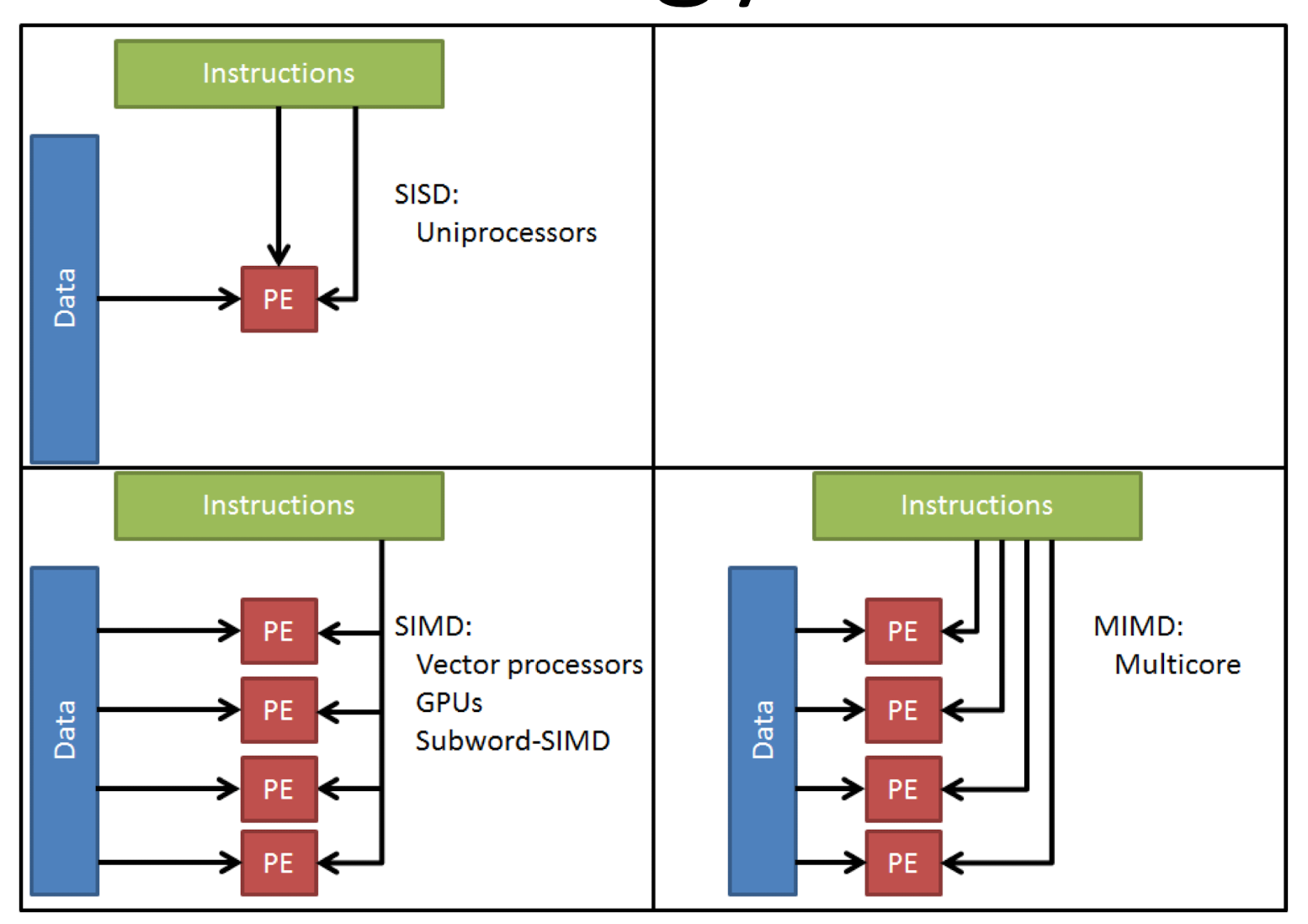
简单的做法就是并行使用多个 核 core 或者使用多个硬件结构实现并行, 但是这里要讨论的是 数据层面的并行
在固有的处理器中, 我们计算如下公式
1 | for(i = 0; i < 100; i++) |
很显然这一步可以用矩阵和向量等式进行优化
即表达式
那么接下来的问题就是如何用硬件快速计算向量
SIMD 方法论
基础方法称为 single insturction single data 处理, 即每个指令获取一个对应的 data 部分, 但是事实上我们可以从一个指令调用多个 变量(来自一个 vector 的多个相关变量) 这就是 simd (可以在单核处理器上面有出色表现)
当然也可以 多个指令调用多个变量, 这个取决于多核同时工作
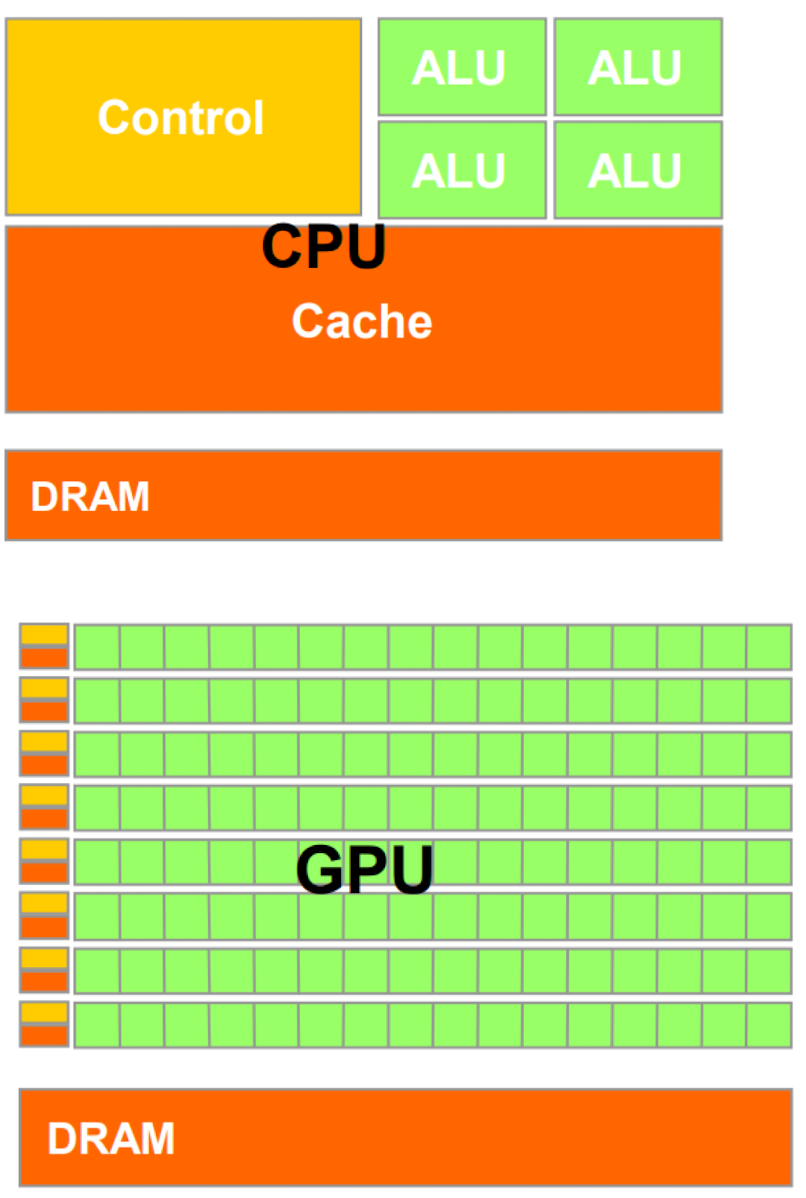
对比 cpu 和 gpu, 我们会发现当我们要处理大量相同类型的数据的时候 (例如图片的像素处理) gpu 会使用小 control 元件和小 cache 来实现同时 load 大量的数据 (这里不大会有 hazard 因为只是同时处理一个向量, 其之间的相关关系非常少)
在 gpu 中会存在一个叫做 threadBlock 的结构, 每个结构代表多个线程的集合
__global__ 关键字用于定义一个内核函数(kernel function), 该函数将在 GPU 上执行, 返回类型必须是 void
调用 global 函数时需要使用 CUDA 特有的语法, 即在函数名后面使用三重尖括号 <<<...>>> 指定线程的布局
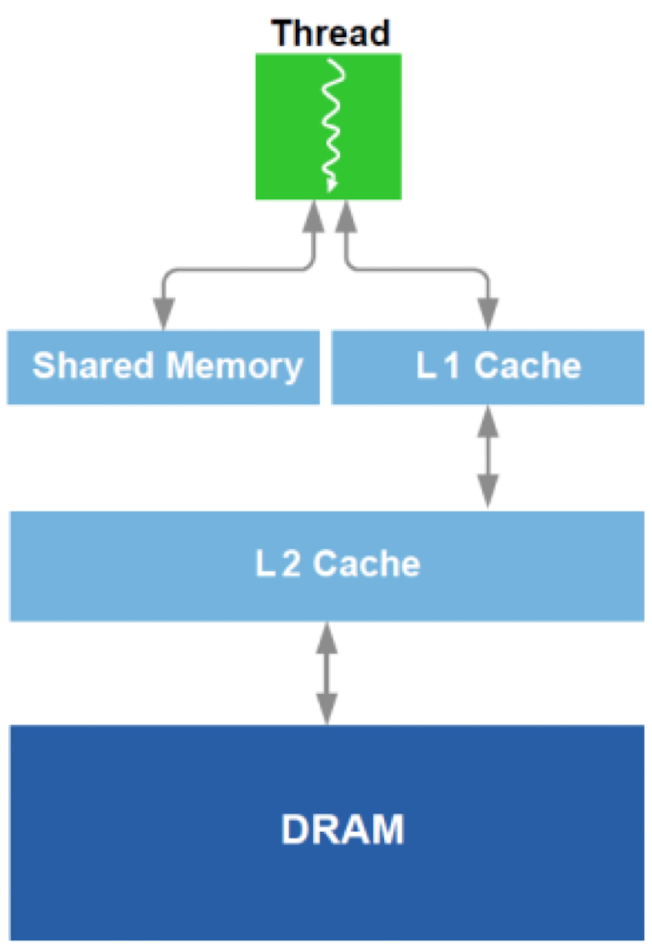
每个线程有各自的 private therad local memory, 每个 thread block 有各自的 block share memory , 总的 app 也会有一整个 global memory
cuda: Compute Unified Device Architecture
SIMT Model
single instruction multiple thread
assumption: 有超大量的元素在一个 vector 中需要执行类似的操作
认为每个 element 是一个 thread, 每个指令一次处理 10 - 100 个elements (类似 simd) 同时利用 pipline 的特点在下一个cycle 直接处理下一个 instruction. 这里读取指令可能会来自于其他的 thread (这样 cache miss 不会stall program, 因为 anyway 下一个指令已经开始执行了;当某个线程组 (warp) 在访问内存时遇到缓存未命中时, 该 warp 不会停下来等待数据加载, 而是会被搁置(suspended), 并由调度器选择另一个准备好执行的 warp 来继续进行计算)
大概拥有 100 个 simd 内核来执行不同的 tread block
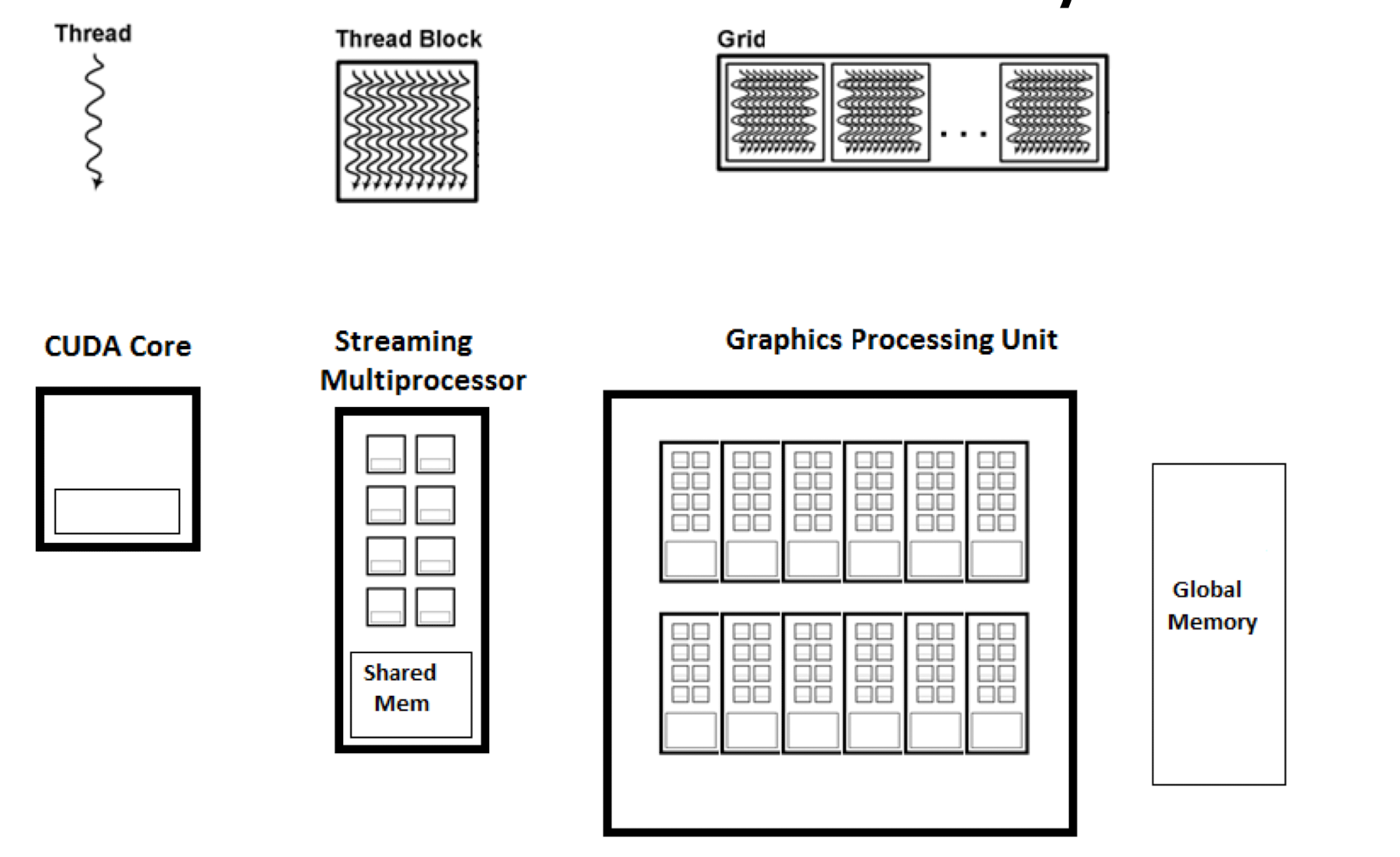
如图为 cuda 的基本架构, 其中每个 core 可以处理一个线程, 然后多个 core 组成了一个 streaming multiprocessor, 在这个内部的 share 内存的交换速度非常快, 可以在 1 cycle 内进行数据的互换, 因此遇到 miss 的时候可以快速换到另一个线程的指令进行执行而不是等待当前的解决
SM(Streaming Multiprocessor): GPU 的"车间"与并行基本单位
SM(Streaming Multiprocessor)是 GPU 上真实存在的硬件计算单元;你可以把它理解成一个"车间/工厂": GPU 里有很多个 SM, 整体吞吐能力很大程度上随 SM 数量扩展;
一个 SM 通常包含(概念层面):
- 执行单元: 负责整数/浮点运算(以及专门的矩阵乘单元如 Tensor Cores, 具体名字随架构变化)
- Warp Scheduler: 选择哪个 warp 在这一拍发射指令(GPU 用"切换到别的 warp"来隐藏内存延迟)
- 寄存器文件(Register File): thread 私有寄存器的物理存放地(容量有限, 会影响能同时驻留多少线程/warps)
- Shared Memory / L1(片上 SRAM 资源): 在 SM 内部的低延迟存储与缓存资源(shared 用于 block 内显式共享; L1 用于缓存部分访存)
- (通常还有)指令缓存, load/store 单元等
SM 和 Block 的关系(关键映射)
- Block 是执行抽象: 一组 threads 的"协作单元"
- SM 是硬件: 真正执行 blocks 的地方
- GPU 运行时会把每个 block 调度到某一个 SM 上运行; 一个 SM 可以同时驻留多个 blocks(取决于资源够不够: 寄存器/共享内存/最大线程数等)
直觉: SM 像车间, block 像工单;车间可以同时接多个工单, 但每个工单会占用车间的资源预算;
SM 和 Warp 的关系(为什么 warp 很重要)
- SM 的调度与执行通常以 warp 为粒度: 同一时刻有很多 warps 驻留在 SM 上
- 当某个 warp 因为访问 HBM/global memory 而 stall 时, SM 可以快速切换到其他 ready warp 继续执行, 从而"隐藏内存延迟"
- 因此: 让 SM 上同时有足够多的活跃 warps(occupancy), 常常是性能的关键之一
CUDA 执行模型与 GPU 内部结构对照 (Thread / Warp / Block / Grid vs SM)
这几个概念是编程抽象, 但与硬件强绑定;理解它们的关键是:
- SM 是硬件实体(物理"车间")
- Grid/Block/Warp/Thread 是执行与编程抽象(逻辑"任务切分方式")
- 其中 Block 会被调度到某一个 SM 上运行, 所以 block 又是"最贴近硬件"的抽象;
1) Thread(线程): 最小执行实例
- 你在 kernel 里写的最小执行流;
- 每个 thread 有自己的寄存器与局部变量(thread-private), 互不共享;
2) Warp: 硬件真正的执行/调度粒度(NVIDIA=32 threads)
- Warp = 32 个线程(连续 threadIdx)组成的"锁步小队";
- 硬件以 warp 为单位发射指令: 一个 warp 内的线程通常同时执行同一条指令(SIMT);
- 两个直接的性能后果:
- Divergence(分支分歧): 同一 warp 内走不同 if/else, 会被迫"分段串行执行", 吞吐下降;
- Memory Coalescing(访存合并): 同一 warp 的 32 线程若访问连续/对齐地址可合并成更少内存事务, 带宽利用更高;
3) Block(线程块): 协作边界 + 资源分配边界
- Block 是一组 threads(可 1D/2D/3D);
- Block 的意义是让线程高效协作:
- block 内线程可通过 shared memory 共享数据(低延迟)
- block 内可用
__syncthreads()做 barrier 同步
- 硬件映射: 运行时会把一个 block 分配给某一个 SM 执行; 一个 SM 可同时驻留多个 blocks(取决于资源: 寄存器数, shared memory 用量, 最大线程/warp 上限等);
- 直觉: 把"需要频繁共享/同步"的工作尽量放在同一个 block; 跨 block 协作更慢更重;
4) Grid: 一次 kernel launch 的所有 blocks 的集合
- Grid = 你一次
my_kernel<<<gridDim, blockDim>>>(...)启动产生的全部 blocks; - Grid 是"逻辑抽象", 不是硬件结构; blocks 的执行顺序一般不保证(由调度决定);
- Grid 维度由
gridDim决定, block 内线程数由blockDim决定;
5) 层级关系(从大到小)
Kernel launch
Grid(所有 blocks)
Block(协作单位: shared + 同步)
Warp(执行单位: 32 线程锁步)
Thread(编程最小实例)
内存层级与"共享范围"(Thread / Block / SM / Device)
从"谁能看到谁的数据"的角度看:
- Registers: thread 私有(不共享)
- Shared memory: block 内共享(语义上按 block 分配/隔离)
- L1 cache: SM 内共享 cache(同一 SM 上驻留的多个 blocks/warps 共享容量与带宽, 可能互相干扰; 不要把 L1 当作可靠通信介质)
- L2 cache: 芯片级共享(通常全 GPU 共享)
- HBM/DRAM(global memory): 设备级共享(跨 block/跨 SM 通信一般通过它 + 同步原语完成)
一个实用结论:
- block 内通信: 用 shared memory +
__syncthreads()(便宜, 明确) - 跨 block 通信: 通常走 global memory(慢), 最好用 kernel 边界作为大同步点; 更复杂场景才用 atomic/fence 等手段;
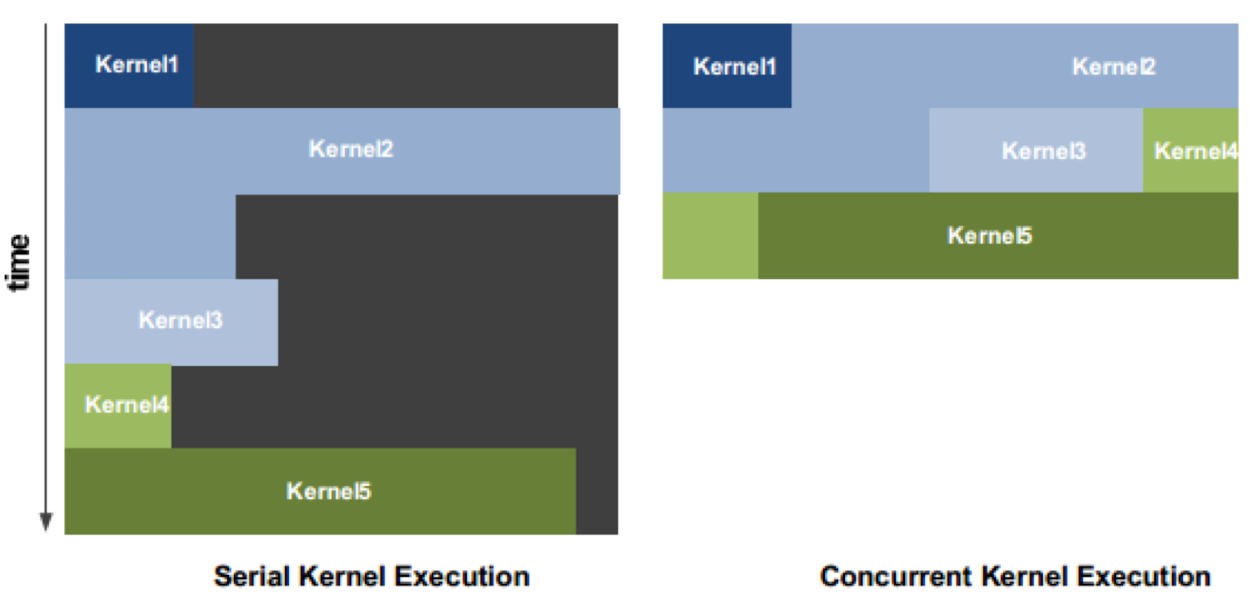
giga thread scheduler
不同于单核的调度器执行依赖于短板效应的 周期 = 最长指令用时, gpu 允许一个 cycle 内将多个 kernel 分别处理各自的内容或者处理存在依赖性的内容
双层 cache 结构
gpu 会使用两层 cache 结构 L1 和 L2 并且