
7. 分布式事务系统与 Spanner
分布式事务系统 Distributed Transaction
根据分布式数据库系统的类似要求, 我们设计的分布式系统要支持 ACID 准则:
- Atomicity (原子性): 事务要么全部完成, 要么全部不做;
- Consistency (一致性): 事务执行前后, 数据库必须处于一致状态;
- Isolation (隔离性): 并发执行的事务彼此隔离, 互不干扰;
- Durability (持久性): 一旦事务提交, 其结果是永久性的, 即使系统崩溃也不会丢失;
如何区分 Linearizability 和 Serializability?
- Linearizability (线性一致性):
- 每个操作看起来像是瞬间发生的, 并且所有的 read 都会反映已经发生的所有 write 的结果
- Serializability (可串行化):
- 并发执行的事务的结果与某个串行执行的顺序相同
- Strict Serializability:
- 结合了线性一致性和可串行化的概念
- 也就是外界看到的顺序和实际执行的顺序是一致的
Isolation 问题与二相锁 (2PL)
一个常见的 isolation 冲突问题: 两个 client 处理线程同时尝试修改一个 entry, 可能会互相影响, 在传统 OS 思路上, 应该用 mutex 来保护这个 entry; 但是这个和我们的 OS 设计有很大不同:
回忆 482 p4 的文件系统中锁的使用: 用了读写锁来保护每个 block, 并不需要担心太多, 这是因为我们的文件系统实际上是一个 tree 结构, 而 tree 其天然就是一个 acyclic graph 结构, 也就是有向无环图, 所以其不容易产生死锁; 而如果一个数据库系统中, tuple 本身的存放并不符合一个 tree 结构, 那么就很容易产生死锁问题; 所以在分布式存储系统中, 为了解决这个 “无序上锁导致死锁” 的问题, 工程界引入了 二相锁 (Two-Phase Locking, 2PL) 的概念:
- Growing Phase (增长阶段): 事务可以获取锁, 但不能释放锁;
- Shrinking Phase (收缩阶段): 事务可以释放锁, 但不能获取锁;
通过这种方式, 可以确保事务在执行过程中 不容易 (不是不可能) 因为等待锁而导致死锁问题, 因为这里的锁的顺序是严格有序的, 在 growing 阶段只能获得锁/升级锁 (r->w) 但是不能解开, 直到有节点拒绝上锁或者事务完成; 这样一旦有失败的上锁就会把所有已经上的锁都解开, 让整体变得更安全;
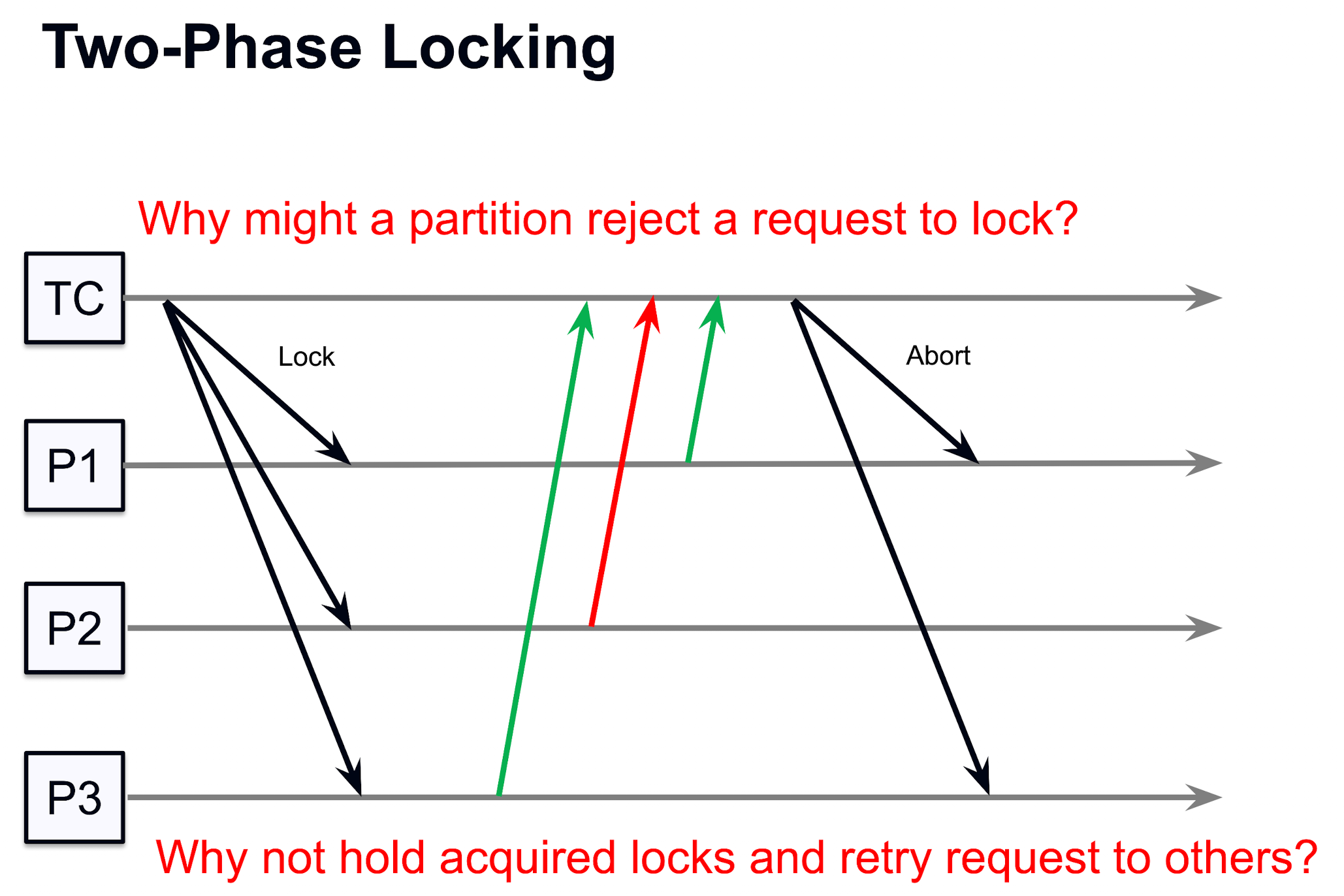
至于为什么数学上这样可以保证少死锁, 或者说为什么两层的锁机制会比一层的好, 我们可以直接类比一个严格 paxos 系统 (容错=0), paxos 也是通过加一层 prepare 层来做测试可用, 我们可以认为第一阶段利用 growing phase 进行预测, 只有大家都同意更改才会真正上锁, 否则不上锁, 这样确保了每次给大家上锁的都是 临时 leader, 从而确保系统的一致性 -> 正确性 (一个比较粗糙的类比, 具体证明可能还得看一下 paxos 原来的数学原理证明)
不过这个分布式锁机制其本身有一个无法克服的非原子性缺点: leader 给所有节点上锁的过程不是 atomic 的, 也就是对多个 follower 上锁的过程中并不是所有 follower 都会立刻上锁, 中间有 undeterministic waiting time, 如果在两个成功上锁的节点的上锁时间戳之间有一个其他事务, 那么二者就可能存在不一致的问题, 当然这主要说明了 read-only 的请求也要上锁, 而不能自由使用
持久存储上锁日志
由于上锁了, 我们就要担心万一发起上锁的系统忘记了解锁怎么办? (主要考虑系统 crash 的情况) 这就需要我们把上锁的日志持久化存储下来, 一般来说我们会把上锁日志存储在 本地磁盘 上 (因为分布式存储系统的网络存储一般都不可靠), 这样即使系统 crash 了, 我们也可以通过读取本地磁盘上的日志来恢复上锁状态, 从而确保系统的一致性;) 并且, 作为被锁的节点, 我们也要有自己恢复的机制 (万一这个上锁的系统崩溃了并且短时间都没有恢复, 那么自己也要能尝试解开)
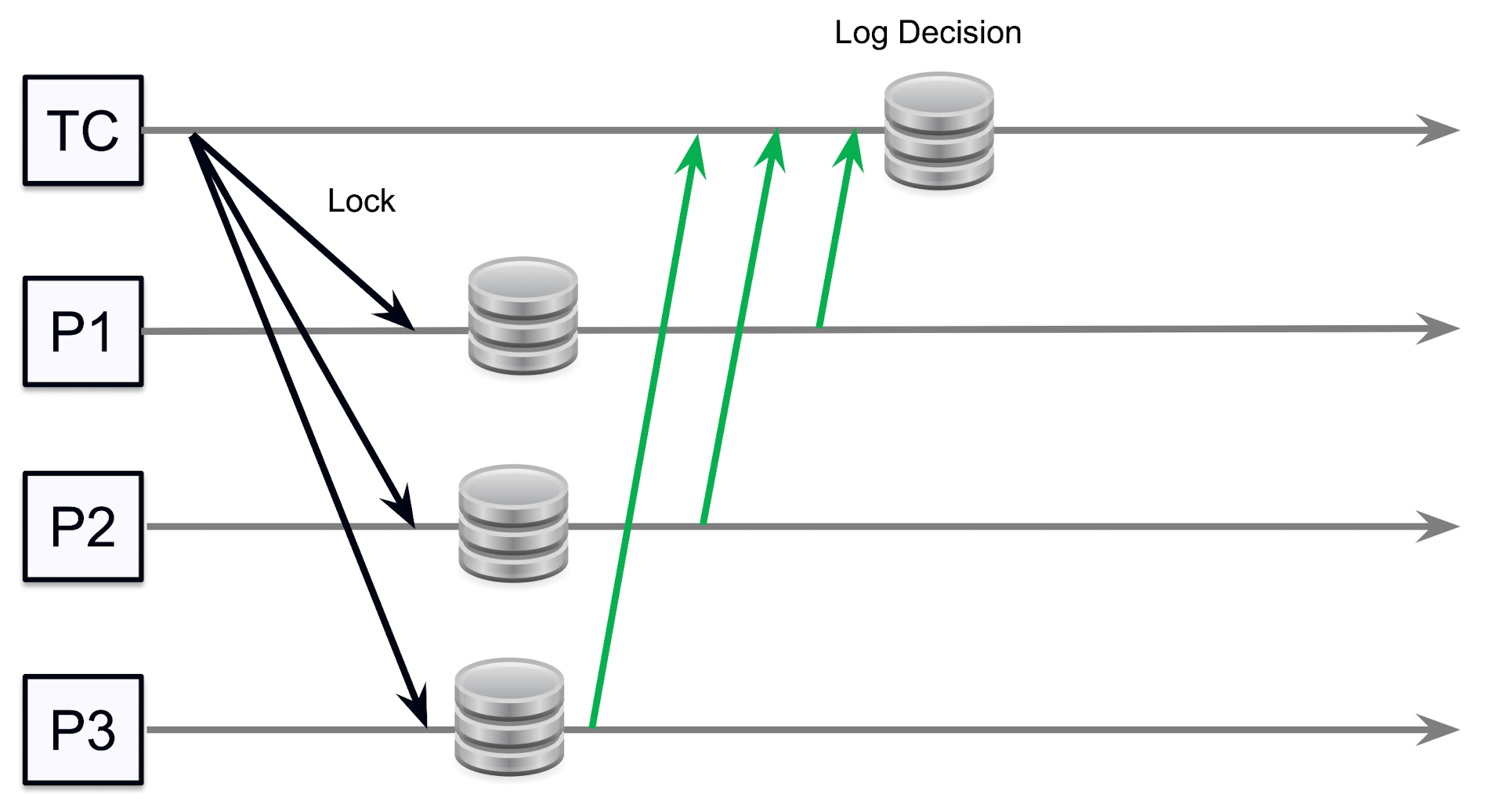
这里就需要借助 log 来记录哪些节点已经被 lock 了, 现在的问题就是, 哪些时间点一定要进行标记?
- 在开始 txn 之前: 如果发生在这个写入之前的 failure 不会对这个 txn 造成任何影响
- 在 收到所有 lock 之后: 如果发生在这个 lock 获取之后, 如果系统崩溃重启可以直接继续后续操作, 因为锁已经到手了, 剩下就是下一段 commit 的事了
- 在上述二者之间的时间节点: 必须重做一次这个 acquire lock 的请求给所有节点, 只有这样才会向所有节点获取响应成功, 接下来要么收到拒绝, 要么给没通信成功的节点上锁, 要么就是得知已经上过锁了
Google Spanner
TrueTime API
由于我们在 Lamport Clock 的时候就已经讨论过了不同 pc 内存在的 clock drift 问题, 也就是局部电脑的内部时间并不是真实时间, 所以不能用一个统一的时间来全局定义顺序, 但是 Spanner 提出了一个比较松散容错的时间同步机制: TrueTime API:
- TrueTime.now(): 返回一个时间区间 [earliest, latest], 其中 earliest 是当前时间的下界, latest 是当前时间的上界
- 这个通过每个节点不断地和 GPS 卫星和原子钟同步来实现, 这样可以确保时间的准确性
- 也就是我们无法从时间戳的角度来认为某个操作发生在一个点上, 但是我们可以定义一个狭窄的区间, 来确保操作发生在这个区间内
在有了这个 TrueTime API 之后, spanner 就可以用 2PL + Paxos 机制来实现分布式事务系统:
- Lock 被看作是一个 Lease, 也就是有一个过期时间的锁, 这个时间间是通过 TrueTime API 来定义的
- 每个 shard 存储的内部是一组 Paxos Group 来确保容错性, 每个 Paxos Group 负责一部分数据的存储和一致性维护;
Lease Time 语义
首先从 CAP 理论来分析, 这里的设计不可能存在 两个 leader -> CP, 因为可能会存在无 leader 的情况, 不满足 Availability 的要求

Spanner 的设计逻辑可以用一句话概括, 就是 Waiting Out Uncertainty;
Leader 视角
作为一个 Leader, 其如果获取了信任想要上锁, 并且一个 lock 的 lease time 长度是 t, 我们要确保其自身的最大时间长度不会超过 t (比较保守), 所以我们要保证如下不等式:
Follower 视角
作为 Follower, 其要确保的应该是提供的 lease time 区间内一定有效, 也就是要保证在为来的 t 最长可能时间内, 坚决不可以接受新的锁请求 (否则可能会造成死锁).
那么, 我们要保证如下不等式: 才能接受新的锁请求
Lock-Free Read-Only Transactions
对于仅阅读的事务, spanner 应该允许其不需要上锁就能快速读取数据, 这样可以大大提高系统的吞吐量和响应速度; 但是既然我们要确保读的进程不会被写的进程影响, 那么我们就需要确保读的进程读取的数据版本是一个 稳定的版本, 也就是在读的过程中不会被写的进程修改;
所以我们这里采取 versioned snapshot 设计逻辑
利用 Spanner 系统对时间的特殊控制设计, 对于不同版本的 snapshot, 我们应该通过 TrueTime API 来确保其版本的稳定性.
不过在给出具体定律之前, 我们还得先想一下, 读的事务和写的事务之间的时间关系: 我们在决定全局执行顺序的时候采用的是 paxos consensus 算法, 这个算法带来的最直接后果就是我们写入 log 的时间 (也就是定下来执行顺序) 和我们真正 apply op 的时间之间的时间差是完全不确定的, 所以我们不能用 log 时间戳来判断其是否被执行之类的;
所以为了让任何一个 rsm 节点能追上 log 的进度, 我们最直接的做法就是把一个 READ 请求也写入到 log 中, 这样就确保了所有节点都能看到这个 READ 请求, 这个 read 也能反应前面写在 log 中的所有 WRITE 信息; 但是我们并不需要完全让 read 追上 now (简单想一下,我们不能对每个请求都做一个 snapshot, 所以应该是有一个周期的,那么对于这个周期就应该有一个对应的 ) 或者说再通过 TrueTime API 约束,要定义一个支持安全读取的时间戳 .
Safe Time: