
5. Consensus: Paxos Made Simple (not to me)
Introduction
上回书我们说到, PB 复制存储的设计对比 Replicated State Machine (RSM) 有 Fault Tolerant 方向的极大优点, 也就是 RSM 在某个节点卡住的时候会导致整个系统卡顿, 因为 RSM 利用了 Lamport Clock 逻辑顺序的 握手机制来达到实际上的全局一致顺序, 如果局部卡死我们这里的握手就无法达成, 逻辑链就断掉了
但是 PB 肯定也有其缺点 不然为什么还要特意讲讲 RSM, 在我们实现了 PB 设计的原理基础上, 让我们来看看 PB 设计的缺点:
- PB 同步链路失效: 这样其实就卡死了, 因为 priamry 一定要同步给 backup 但是由于 link 挂了, 整个同步就无法成立
- Primary Push 过程失效: 如果 primary 在 push 的时候挂了, 那么 backup 永远收不到更新, 也就永远无法同步
因此我们折中派就要考虑如何优化 RSM 来修复 PB 的这两个问题了, 而且 RSM 在带宽上肯定是更有优势的 (每个 RSM node 都可以接收外来请求)
设计目标 (从整个 RSM cluster granularity 来看)
- 如何决定 RSM 的下一个 update 操作听谁的
- 在 RSM 中所有 node 没有主次之分
- 要 允许部分 node 挂了
- 既然没有不同 (都是人民), 那么就要允许从人民中选出 人民代表 -> vote (投票) -> consensus (一致)
- 节点的故障模型是 fail-stop:
- 节点要么正常工作, 要么停止(crash), 但不会表现出错误或恶意行为(如 Byzantine 错误);
- 节点需要持久化存储状态(record state persistently), 这样在重启后能恢复上次的状态;
- 所有副本的目标是一致的: 帮助系统达成一个共同决定;
- 它们不执着于自己的提案(not invested in “their” updates), 也就是说每个节点不是为自己"赢"而战;
- 回忆我们前几章提到过的银行例子, 分布式系统设计者并不关心谁获得了钱, 而关心能否保证一致性;
- 它们只关心系统能成功达成共识(they want an update to succeed), 无论具体选的是谁的提案;
- 它们不执着于自己的提案(not invested in “their” updates), 也就是说每个节点不是为自己"赢"而战;
由于并不能要求每个 node 都要回应, 那么如何判断一个 node 提出的概念是否应该被接收而且不能出现歧义呢? 为了达到全局共识, 我们应该确保选择的提案要在 2n+1 的分布式系统中至少有 n+1 个同意的 (如果是偶数 2n, 也要 n+1 个同意的, 否则就可以出现两个可能的提案)
上面的这句话同时也提出了一个 最大容错效果: 这时候如果有 n 个节点挂了, 也不会影响全局一致性的达成, 因为剩下的 n+1 个节点已经足够达成共识了
所以我们可以看出, 这个共识算法的阈值是 最大容错效果 vs 确保一致性的一个折中, 不过我们其实发现只要确保提案唯一, 多几个同意的节点没啥用, 所以就干脆默认 n+1 个节点就好了
经常玩狼人杀(阿瓦隆? )的同学应该知道, 不是每一轮都会投票给一个人的, 这样的设计会导致 converge 很难发生, 所以当我们希望设计一个能自己收敛的算法的时候, 就一定要禁止跳票 (flipping back and forth), 当然也禁止自爆这种逆天操作, 因为 node 永远都是一致的; 这句话的意思是, 在这里的投票系统中, 一个 node 一旦选择了一个选项, 就尽量不要换自己的选择, 直到确认全局一致之后再弃暗投明
Paxos 算法
Paxos 算法也是 Leslie Lamport 老爷子提出的, 不过其雏形算法复杂度太高了 (33页原稿全是离散证明, 你兰爷还是给你证出来了), 后来 Lamport 为了大众理解, 就出了一个简化版的 Paxos 算法, 也就是我们现在要讲的 Paxos Made Simple (类似的故事可以参考 Practical Byzantine Fault Tolerance, LCS MIT, OSDI 1999)
设计目标:
- Safety: no bad things can ever happen, 也就是系统不会到达一个错误的状态: 也就是 Consistency
- Liveness: good things must eventually happen: 也就是 Convergence
为了更好的确保共识, 对于单个 proposal, 首先应该要尽量让 majority 来知道这个存在 除了知道之外, 我们还要在节点处思考, 如果这个节点一下子收到了几个 proposal, 应该怎么处理已有的和新来的?
- 假设这个节点对当前问题已经接收了前一个 proposal (直接切开思考, 只有接收和没接受两种), 那么前文说过跳票不利于团结, 所以这里应该 支持前面统一过的 proposal
- 假设这个节点没有接收过任何 proposal, 那么这里就在确保当前 proposal 被多数 node 接收的情况下 接受新的 proposal, 这样才能保证 liveness
假设现在有一个登山小组 4 人, 正在讨论去哪里爬山, 但是没有一个群组, 成员之间只可以通过 1-1 私信交流
- safety 要求: 最终大家只能去一个山, 不能分头行动, 也就是一定要被 大多数(Majority) 所认同, 并且一旦共识达成就轻易不发生变化
- liveness 要求: 只要 proposal 存在 (无论几个), 最终大家一定会达成共识, 也就是 不能无限期拖延
Alice 提议去爬保俶山, 但是 Bob 建议去爬北高峰, 并且他们的共同目的不是坚持己见而是尽快定下来;
- 假设两人特别同步, Alice -> Cindy 和 Bob -> David 同时说了自己的想法, 这样再通知另一个人的时候就会发现没有达到 majority, 因此两边都会 fail;
- 两人存在先后: 先入咸阳者为王, 假设 Alice (保俶山) -> Cindy, David, 达到了 majority, 那么 Cindy, David 会支持 Alice 的提议, 然后 Bob 通知 David 的时候, 发现已经被同意了, 于是自己只好闭嘴
- 这里赌的是两个人不可能永远同步, 早晚会收敛到第二种情况
注意这里 Alice 和 Bob 的身份比较特殊, 我们称为 Proposer
Proposer 的几个共识阶段
- Be the Winner: 确保有至少 n+1 个节点知道了你的 proposal
- Known Winner: 对某个节点而言, 知道了这个 proposer 已经被 majority 所接受
- Globally Known Winner: 所有 replica 知道了 majority 已经接受了这个 proposer
其他角色
- Acceptor: 接受 proposal 的节点, 也就是上面的 Cindy 和 David
- Learner: 学习最终结果的节点, 也就是所有人
由于所有 node 都是平等的, 所有 node 都可以是 Proposer, Acceptor, Learner (不同 round, 即不可兼职)
Acceptor 实现
n_p: 当前 承诺接收的 最高的 proposal idn_a: 当前 接收过的 最高的 proposal valuev_a: 当前接收的值
但是这里 n_p 和 n_a 的概念理解起来不是很直观, 这是因为整个 accept 过程分成两步:
- Prepare
- Propose
Phase1: Prepare
- Proposer side: 提出一个 uniq proposal id
n然后发送<PREPARE, n>给 所有 Acceptor (不然怎么知道谁是 majority 呢, 对于 proposer 而言, Attention is all you need)id的选择可以基于 lamport clock 时间戳, 为了避免 tie 所以再 appendnode_id, 也就是(update/slot id, proposal id)
- Acceptor side:
- 如果
n >= n_p, 那么就更新n_p = n- 如果前面 已经接收 (accept) 过 proposal, 那么就回复
<PROMISE, n, (n_a, v_a)>给 Proposer- 这是为了让 proposer 知难而退, 或者说让 proposer 同意前面的 proposal
- 如果前面 还没有接受 proposal 然后回复
<PROMISE, n, EMPTY>给 Proposer- 告诉 proposer 你是第一个, 就听你了
- 注意这里的
n_p是收到的最大 proposal id 虽然没有接收但是也会更新这里的n_p
- 如果前面 已经接收 (accept) 过 proposal, 那么就回复
- 否则就忽略这个 prepare 请求, 返回
<PREP_FAIL>给 Proposer- 也就是忽略落后版本的请求
- 不过优化这里可以直接返回
<PROMISE, n_p>给 Proposer, 这样 Proposer 就知道最新的 proposal id 了, 这其实是 lamport clock 的握手思路, 放在这里没有坏处
- 如果
Phase2: Propose/Accept
- Proposer side:
- 如果收到的消息中有
n_a != EMPTY, 那么就选择v_a中n_a最大的那个值作为自己的 proposal valuev- 也就是 尊重前人的选择, 这样才能确保 safety (如果不同 node 返回了不同版本的 proposal, 那么就选择版本号最大的那个)
- 否则就选择自己原本的 proposal value
v
- 然后发送
<PROPOSE, n, v>给 所有 Acceptor
- 如果收到的消息中有
- Acceptor side:
- 如果新的下发的 proposal id
n >= n_p, 那么就接受这个 proposal, 更新n_a = n和v_a = v, 然后回复<ACCEPTED, n>给 Proposer- 所以 acceptor 的选择也不是一成不变的, 否则也不利于一致性 (团结), 要批判地团结
- 如果新的下发的 proposal id
有没有可能出现 minority 的 proposal 被共识了?
还是有可能的, 原因如下:
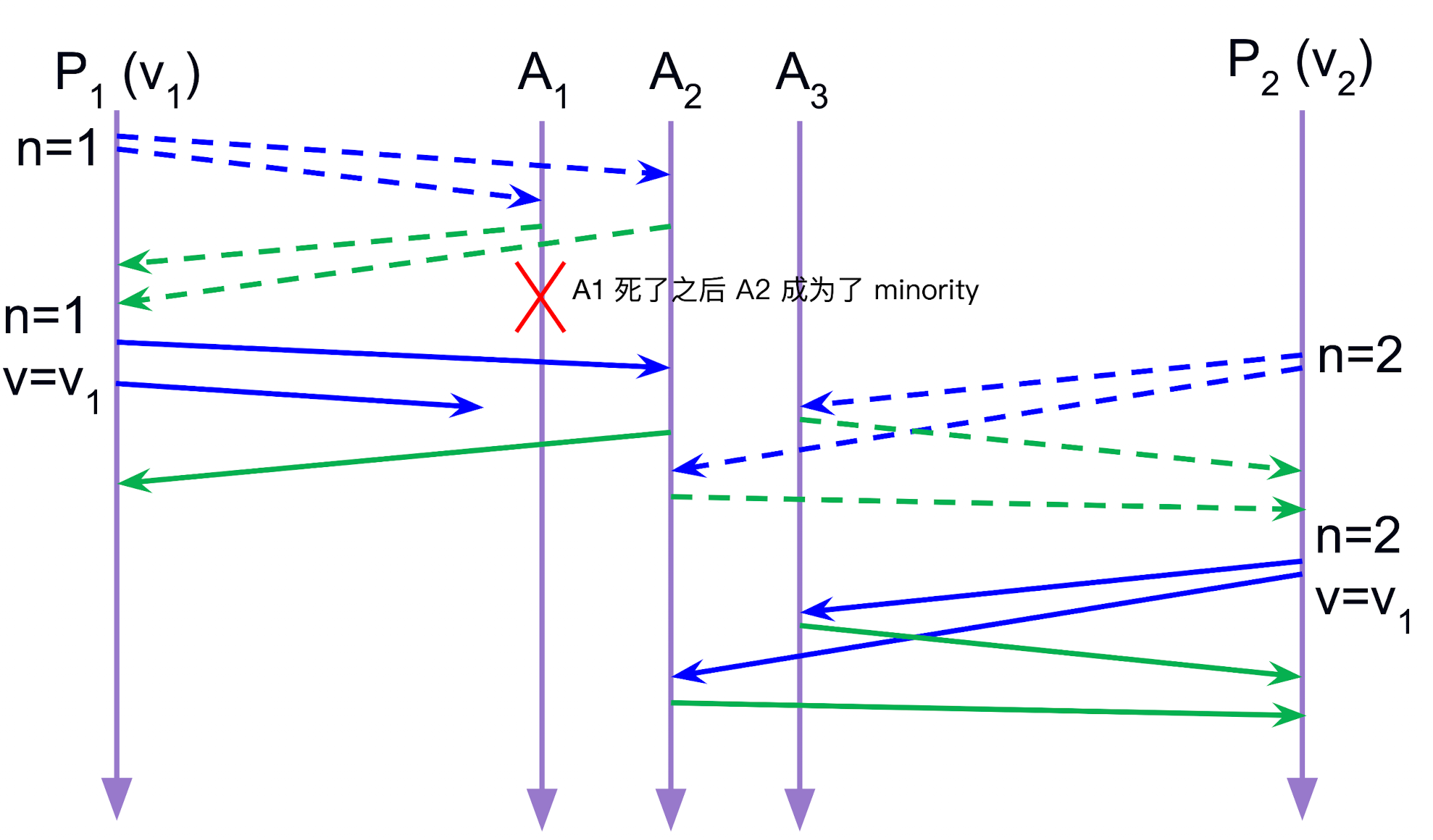
注意 propose phase 的开启是由 Proposer 收到超过半数的回复的时候才会开启的, 其他都不会
Phase3: Learning
- 其他所有节点都要学习最终的结果
这里一共由三种实现方法 (也就是任一角色来广播):
- proposer 成功之后主动发送同步
- acceptor 广播自己的 state update
- acceptor 发送给一个 learner, 让 learner 来广播
这里 Paxos 采用的思路是延续了前面 prepare 阶段的思路, 也就是从 learner 自己发出请求给所有节点, 并且发现有超过半数的节点都接受了某个 proposal, 那么就认为这个 proposal 是最终的结果
Probablistic Liveness
- 一旦 proposal 确认了, 所有活着的节点最终都会知道这个 proposal 并且接受它
- 但是形成 proposal 并不一定是 liveness, 因为就像我们说的只要两个 proposer 一直在交替着提出更高的 proposal id, 系统就可能永远无法收敛
这种同步就叫做 Probablistic Liveness, 也就是概率收敛, 但是我们可以通过一些手段来提高收敛的概率, 也就是让两个错开的时间长一点, 这样就不容易交替了
- random backoff (随机退避): 每个 proposer 在提出 proposal 之前等待一个随机的时间间隔, 这样就不容易交替了
- priority nodes: 根据 proposer ID 来调整重试等待时间, ID 较小的 proposer 优先重试(或等待更短), 这样可以减少随机性带来的延迟, 让系统更快收敛
RSM 实现 Paxos
其实回顾一下我们在 Lamport Clock 的章节就已经提及过: 如果两个节点要握手就要先尝试交换时间戳, 然后根据最早的来执行
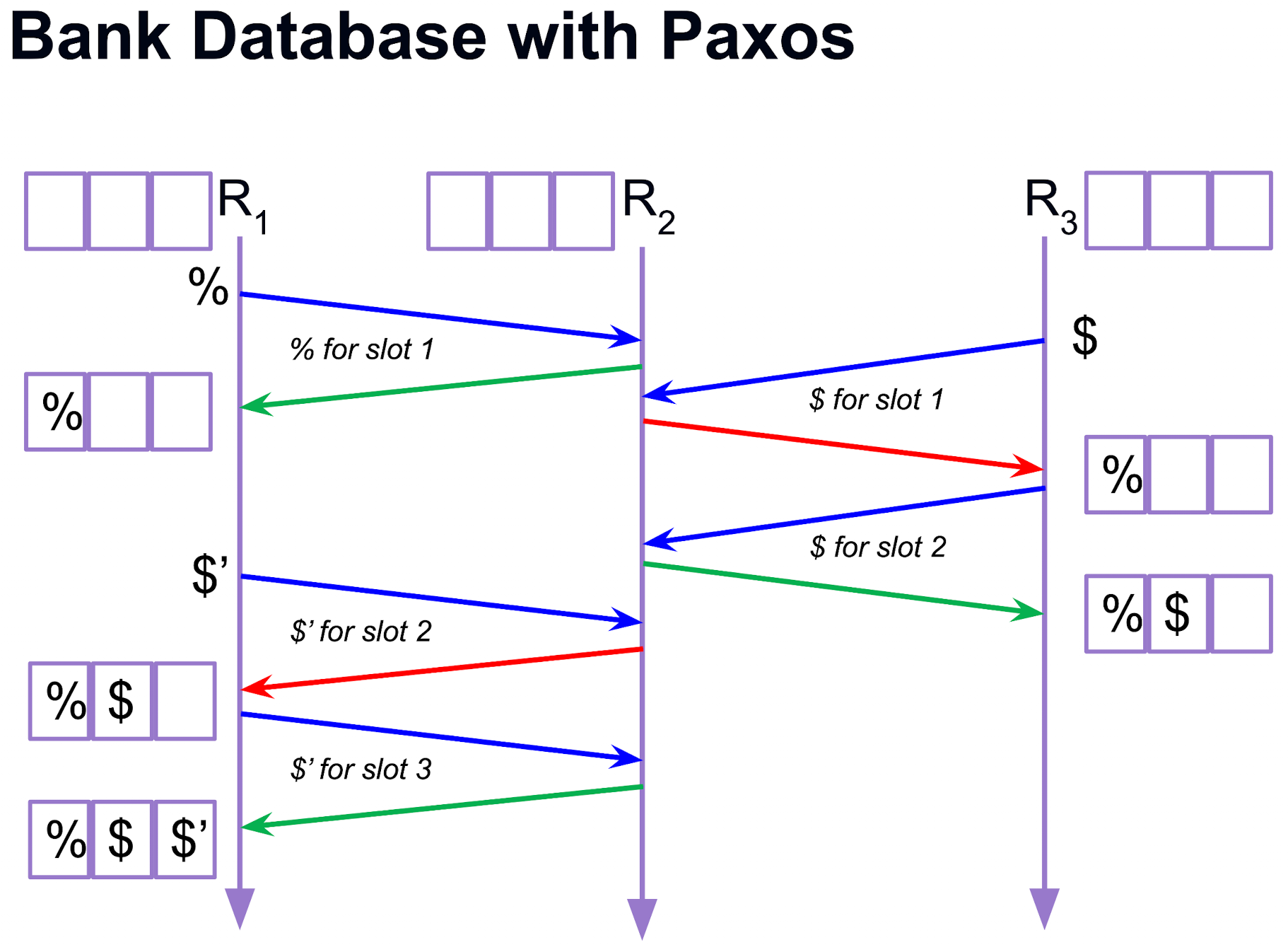
RSM-Paxos 具有两个很重要的时间点:
- t1: 当某个 operation 被选作 i-th slot in the log
- t2: 当所有 replica 都知道这个 operation 被选作 i-th slot in the log
- 二者之间存在任意的时间差, 但是 t2 一定要在 t1 之后
时间差如何见效? (Reduction of Lag)
这里需要分类讨论, 即有 failure 的情况和没有 failure 的情况
Failure-Free Case
1 | R1 发送 Prepare(N) -> R2, R3 |
只有当 R1 收到了 R2, R3 的 Accepted 回复之后, 才能认为 choice 发生了, 也就是 operation 被选作 i-th slot in the log
这时候 R1 会向外广播这个决定 decided(N, op), 这样 R2, R3 就能学习到这个决定了
Failure Case
从这里看出其实最依赖的是最后一步, 如果前三步失败了, 那么其实第四部成功与否都无所谓, 因为本来也成功不了
但是如果第四部失败了, 那么就属于是白费功夫, 前三步被浪费了, 且没有 node 知道这个决定发生了
线性一致性在 Paxos 协议下的表述
- 根据线性一致性的表述, 每个 READ 都要读取到所有之前的 WRITE
- WRITE 用 Paxos 的协议来说就是获取 Majority 的同意
- 但是 WRITE 只获得了 Maj 的同意, 如果 READ 只读到少数节点, 那么就可能读不到最新的 WRITE
- 所以 READ 也要有一个 SeqNo 来作为自己的 proposal id, 然后也要获取 Majority 的同意
- 这样就能确保 READ 一定能读到最新的 WRITE 了
什么时候认为一个 operation externalized?: 首先一个 operation 被执行 (不是 externalized) 的条件是
- chosen as slot
- learned by majority
- all prior slots learned by majority (executed)
单个节点状态
- 每个 node 都会有自己接收的一个 proposal 及其数值;
- 每个 node 都无法知道其他 node 的 proposal 状态;
node 如果想要获取其他 node 的接收状态, 就要发送 prepare 请求, 并且看到多数节点的回复才能知道自己支持的 proposal 是否被接受了; 回忆上文说过的 prepare 流程:
- Proposer 发送
<PREPARE, n>给所有 Acceptor - 如果 Acceptor 收到的
n >= n_p, 那么就更新n_p = n并且回复<PROMISE, n, (n_a, v_a)>给 Proposer - Proposer 从而知道当前多数节点的 proposal 状态
这个时候新 Proposer 就可以发出 decided(v) 指令来通知所有节点了
Garbage Collection
对于 log 的前一部分 (prefix) 很多时候不再需要保存这一块记录, 因此要考虑什么时候可以删除这一块信息: 保存这块 prefix 的目的是让落后的节点可以查看然后复现从而追上进度, 因此只有当所有 replica 都已经执行到某一步骤之后, 才能真正删除这个 log 来减轻内存负担
但是即使根据 paxos 协议的要求, 在新的 proposer 发起 prepare 之后发现了共识达成, 也不能删除 log 因为单个节点永远无法知道其他节点的状态, 唯一知道别人知道的方法是: 让别人告诉我; 有两种新的机制来实现这个目标:
- Piggy-back(捎带)机制: 不需要单独发一轮消息, 而是把这种确认附带在下一次 Paxos 操作里;
比如下一个提案时, 顺便告诉大家 “上一次的值我已经学到了”; - 延迟回收(lazy GC): 垃圾数据(旧 ballot, 旧 value)只有在新操作发生时才被逐步清理;
Burst Optimization
在现实系统使用中, 往往会发现单个 client 的请求会集中在一小段时间段内, 而不同 client 往往会错开时间段集中发送请求; 这个现象称为 client locality.
并且根据网络系统的特征, 往往会向地理最近的节点发送请求, 也就是说一个 client 在连续多次请求的时候其实是会向同几个 replica 发送请求的, 那么如果每次都要进行完整的两步走, 其实就没什么必要, 因为这里的 replica 会持续作为 proposer 来参与

但是这样的直接优化一定 safe 吗? 就比如如图的例子, 假设 R2 和 R3 都是 proposer, 在两个 n=5 的时候就已经把 slot1 给执行了, 然后如果这时候 R2 执行一个新的 proposal 那如果直接跳过 prepare 阶段直接 propose 肯定可以提升 performance; 但是问题是, 如果在 slot1 解决到 R2 提出新 proposal 期间如果 R1 做了一个请求并且完成了 prepare-accept 的流程, 那么 R2 跳过 prepare 请求就会导致问题: 它直接发送自己想要的结果到已经填充过的 slot2, 破坏了 consensus;
这里优化的目标其实是:
- 让 R1 这种中间插入的 proposal 尽量被拒绝 (在 prepare 阶段就要拒绝防止多干活), 那么如果要在 prepare 阶段发生 拒绝, 就只能在 propose
n< 已有的n_p; - 而且要让 R2 的请求能被顺利放过, 当然如果这时候有 R1 给了个更高的 n 还是能接收的 (因为这里其实不会导致 consensus 的一致性理念出问题), 所以我们只能让阈值
== n来实现;
PB 思路优化: Raft
另一种优化思路是采取 PB 的角度来优化, 因为 Primary 只需要做一次 prepare 就可以了, 然后后续的 propose 都可以直接发给 Backup 就行了, 这样就减少了大量的消息往返次数, 从而提升性能;
不过这里选举 Primary/Leader 就需要用 Paxos 的机制来实现 consensus 这里的 Proposer + Acceptor 称为 Quorum
不过这里的 READ/GET 机制其实和我们以前设计的 PB 不大一样: 在 p2 的设计中, 我们会发现这里的请求是确保成功的, 也就是说 GET 一定要读取到上一个 Operation 执行完成之后的结果, 否则就要阻塞等待, 但是这里 Paxos 设计并不要求如此, 当一个请求到达了 primary 之后, primary 要审视当前的所有节点, 是否 majority nodes 都实现了 learn 这一步, 如果看到这里还没有被 learn 的话, primary 应该返回的是 old value, 因为根据 Linearizability 的要求, 这里整个系统的请求还没有被 externalized. 不过这里也就是我们前面说的,一个节点很难知道别人 learn 了没有,所以这里多半是一个落后的状态,直到超过半数的人实现了这更新之后又 propose 新的数值了