
18.vmware_esx_mem
Introduction
VMware ESX Server is a thin software layer designed to multiplex hardware resources efficiently among virtual machines. The current system virtualizes the Intel IA-32 architecture
In contrast, ESX Server manages system hardware directly, providing significantly higher I/O performance and complete control over resource management.
- machine addr: real hardware address
- physical addr: guest OS’s address
pmap: data structure for each VM that maps physical addr to machine addr (ppn -> mpn)- 注意这就是 EPT 的功能, 只是 2002 年 Intel 还没有 EPT 技术
Reclamation Mechanisms
- 每个虚拟机都会有一个 constant max size (Virtual Mem), 也就是一旦启动之后就不会变了
Overcommit: 过量使用后收回页替换机制
- 如果出现 ESX 宿主机承诺了过量的内存页使用量, 就会出现问题: 如何回收? 如果使用基于 pmap 的额外页表机制, 就还要改一下接口, 也就是撤回的页必须以 (VM, Vaddr) 这样的 tuple 形式才能让 ESX 实现页的撤回, 也就是 Meta-level Page Replacement
- 但是 ESX/VMM 层并不能知道哪个页更适合 evict, 这只有 guest OS 才知道
- Double Paging Problem: 这样设计也会导致 double paging 的问题, VMM 撤回了某个特定的 (VM, page), 但是该 VM 在同时也在对应 page 写入了新的内容, 这样就会出现 inconsistency
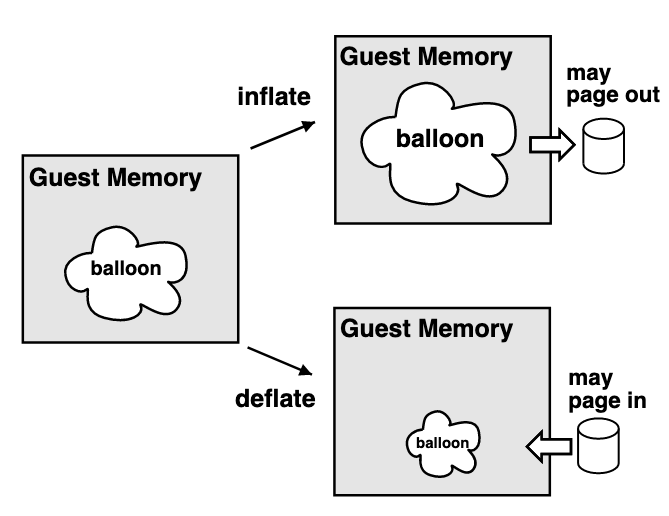
Balloon 机制
-
从上文 VMM 实现 page replacement 的问题可以看出, VMM 并不适合直接回收某个 VM 的某个 page, 只能让 guest OS 自己来决定
-
ESX 通过 ballooning 机制来实现这个设计, 也就是满足 被回收的 VM 照常工作, 只是会认为自己被 configure 了更少的内存
- ESX 向 OS 注入一个 pseudo-device driver/kernel service 到 guest OS 里面, 并且这个设备不会有别的 external interface, 只会和 ESX private communicate
- Inflate 膨胀: 在 guestOS 中申请一定量的
pinned page - Deflate 收缩: 释放掉这些
pinned page
-
如果 guestOS 本身内存空闲, 就直接把 free list 交给这个 balloon driver
-
如果 guestOS 本身内存不够, 就会触发 guestOS 自己的 page replacement 机制, 把一些页换出到 virtual disk, 然后再把这些页交给 balloon driver
-
这些 pinned page 不能让 guestOS 接触, 但是 ESX 是通过 pmap 机制来实现, 也就是把对应 pmap[VM,PPN] 的值变为空 (deallocates the associated MPN), 这样所有后续对这个 PPN 的访问都会 fault 然后交给 ESX 来处理, 这里 VMM 会 pop balloon (戳破气球), 也就是把气球挤占的空间还给 guest OS, 在 pmap 中的 (VM, PPN) entry 添加其新的 MPN 地址
- 为什么要 “pop balloon”?
- 如果 ESX 在 guest 访问时直接报错(比如 kill VM), 这会导致 guest 完全挂掉, 体验很差;
- 更重要的是, 从抽象模型上讲, VMM 并没有正式告诉 guest: 这些页已经"被永久拿走"; Ballooning 的语义是 “暂时 把机器内存挤给别的 VM”, 而不是"让 VM 的物理内存减少, 永久废弃这部分 PPN"; 所以一旦 guest 访问这些 PPN, VMM 的正确行为是:
- 重新给这个 PPN 分配一个新的 MPN(不是之前那块, 之前那块可能早就给别的 VM 了),
- guest 看到的就是"这个页第一次被写入";
- 为什么要 “pop balloon”?
简单地说可以理解为内存的回收类似于一个 page eviction, 就像是 page table 中给被 evict 的页添加一个 resident = false flag 从而标记其被回收了, 在下次调用的时候执行 page fault
Ballooning Overhead Evaluation
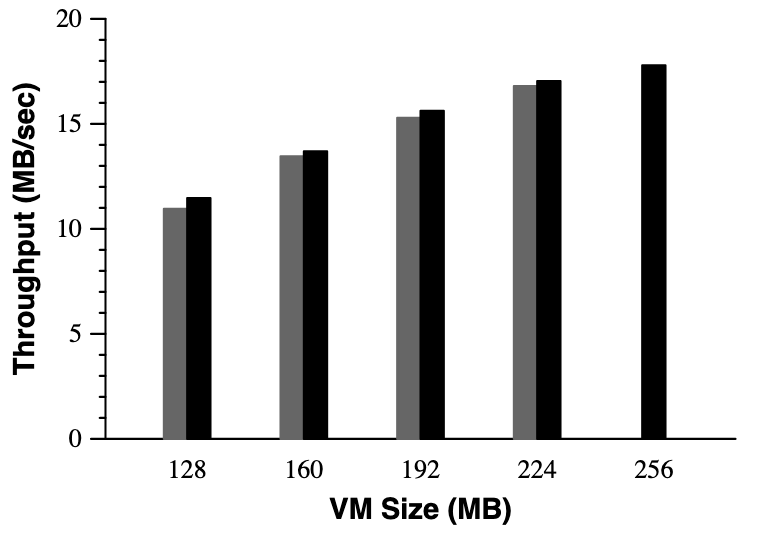
首先说明一下 2002 OSDI 疑似对作图没有什么要求, 这里 legend 都没标注, 很难受
- 黑色的是 baseline, 也就是没有 ballooning 的对应 mem size 的 throughput 量
- 灰色的是 ballooning 的 throughput, 初始 mem size 是 256MB, 但是 柱子对应标记的 memsize 是经过 balloon 挤占之后的实际 mem size
Demanded Paging
如果在某些架构上 传统的 ballooing 失效了, 就会退回最先提到的 VMM/ESX 主导的 paging 机制, 并将 page out的 页放到 host Disk SWAP 分区并且由 VMM 进行维护, 并且为了避免 double paging 的问题, VMM 会用随机算法来获得 page eviction, 这个过程对 guest OS 完全透明
Content-Based Sharing Memory
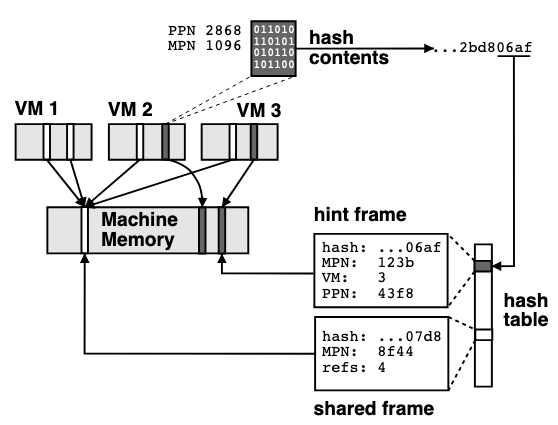
ESX server 设计中, 会基于内容是否一致来共享内存页, 从而节省内存使用;并且通过 hash 来简化比较过程; 也就是如下流程
- 检查是否有相同的 page hash, 如果没有就是独立的新 page, 分配并标记 COW
- 如果有对应的 page 就直接共享
- COW 页如果被某个 VM 写入就会重新分配一个新的 page
但是这里机制过于 ambitious, 也就是默认每个 page 都会在未来被共享, 但是这对大多数 page 的情况都不是这样, 所以应该默认对一个 page 执行 hint tag, 也就是简单标记这里可能会共享, 在未来遇到相同的 hash 的时候额外 rehash 一次, 如果仍然一致 (本身 page 没有修改) 那么就实现共享, 否则就移除之类的 hint (因为改变了)
不过这里为了避免 collision 在 hash 匹配之后仍然会进行一次完整的 page 内容比较
不过从原理上说扫描并且计算 hash 是一个非常消耗 CPU 的事情, 有很多算法可以落地来优化 CPU 消耗并且仍然提供不错的内存节省率
实现细节
- 16B hint/shared frame
- 不超过 0.5% 的 overhead
- 使用 reference count 来标记 page 是否被共享
- 64b hash 函数避免 collision, 真的 collision 情况下直接禁止该页共享
- ESX 通过定期随机扫描 guest OS 的内存页来计算 hash, 这里的扫描是随机的, 也就是不需要扫描所有页, 从而解决了上面说的 CPU 消耗问题, 并且从实际上看共享效果很好
- 在 page out 的时候一定会尝试给 page 共享来尝试提速
上图:
- VM Memory 表示的是一般情况下的 内存使用量, 作为 baseline/upper bound
- Shared (COW) 表示的是经过 ESX 优化之后的内存使用量, 二者差值表示了节省的内存
- Reclaimed 表示共享机制下回收的内存大小, 也就是通过共享节省的内存大小
- Zero Pages 表示的是 Shared 机制中经过 Zero page 共享节省的内存大小
说明了: 回收的内存主要来自 代码和只读数据, 而不是零页, 回收机制性能很好
下图:
- Y 轴表示占整个 VM 内存的百分比
- Shared - Reclaimed: 表示共享中剩下的唯一 copy 的内存占比
说明了: 在多台 VM 下有接近 2/3 的内存是共享的, 其中节省的量页逐步增大, 但是 Shared - Reclaimed 类型的内存占比不会增大, 因为单一备份仍然要固定存在并且随着 VM 数量增多而整体 VM 占比下降了
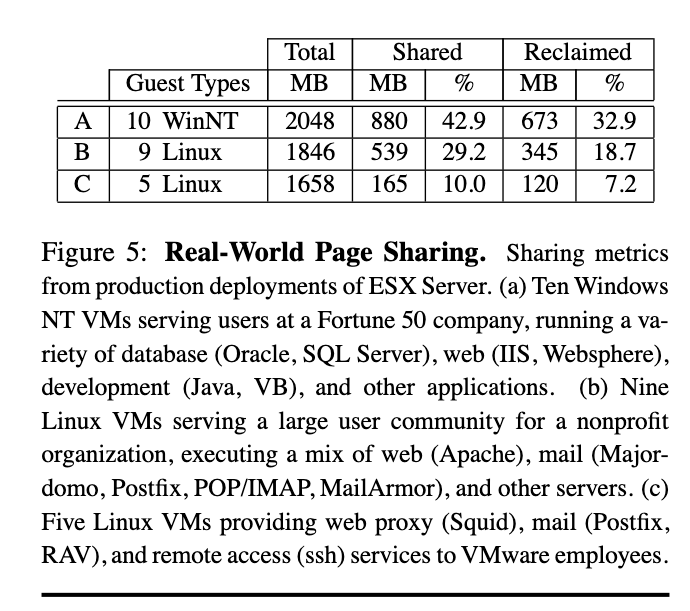
- 工作负载越同质化, TPS 效果越好: WinNT VM 部署高度类似, 重复度大 回收率高; Linux VM 跑的服务越多样化 重复度下降, 回收率低;
- 即使在异构 workload 下, 也能节省一部分内存
- 共享 vs 回收: 总是存在一部分"Shared – Reclaimed", 也就是必须保留的基准 copy;
Sharing v.s. Working Set
- Share = 分配给某个 VM 的 资源权重 (weight), 你可以把它理解为 股票份额;
- 每个 VM 的可用内存 = 它的 share 在所有 VM 总 share 里的比例 可分配的总内存
- minimum fraction: 每个 VM 最少能分配到的内存比例, 也就是 share / total share 的下限
- 当一些 VM 没用完内存时, 空余部分会按 share 比例分给其他 VM
- Min-Funding Revocation: 当需要收回内存时, 从 shares-per-page 最低 的 VM 那里回收
现在的问题是, 如果只看 share 的话, 可能会导致某些 VM 分配到的内存远大于它的实际工作集, 也就是浪费内存; 活跃 VM 被挤压: 另一些 VM 虽然 shares 少, 但 workload 很忙, 就可能缺内存, 性能受损;
所以: 只看 shares, 隔离性有了, 但效率差;
Idle Memory Tax
- 给"闲置页"收更高的"税";
- 活跃页: 每页成本低;
- 闲置页: 每页成本高(相当于"占用要交税");
- 当系统内存紧张时, 优先从"持有很多闲置页"的 VM 手里回收内存;
- 税率 (tax rate, ) = 最多 能收回的闲置页比例;
形式化公式
- 原来的 shares(S)-per-page§ = (shares / allocated pages) = ; Active 比例 f, adjusted shares-per-page
- 加入 idle tax 后, 改成:
其中 ;
- idle pages 的权重被降低(打折处理);
- 越大, idle 页越"便宜", 越容易被收走;
参数调节
- = 0% 纯 share-based 隔离(不动 idle 页);
- = 100% 所有 idle 页都能被收走(完全追求利用率);
- ESX 默认 = 75%:
- 大部分闲置页都可以被回收(提高效率);
- 但还是给 VM 留下一点 buffer, 避免 workload 突然升温时需要重新分配 掩盖 ballooning/swapping 的延迟;
公式意义
- 解决性能隔离 vs 利用率冲突:
- 重要 VM 仍然有 shares 保证 下限,
- 但不会囤着太多闲置内存;
- 更合理的动态适应:
- 内存紧时 回收闲置页;
- VM workload 突然活跃 它能快速拿回 idle 页, 恢复到 full share;
Measure Idle Memory
难点:
-
不需要精确知道"哪一页是 idle", 只需要整体比例;
-
如果依赖 guest OS 接口(比如 Windows/Linux 提供的统计), 问题很多:
- 不同 OS 提供的指标不一致;
- OS 接口一般按进程统计, 不适合 VM 粒度;
- 硬件 page table access bits 在 DMA 时不会更新, 导致不准;
-
所以 不能依赖 guest, 需要 VMM 自己估计;
-
采样方式:
- 每个 VM 独立采样, 采样周期按 VM 的执行时间来算(不是 wall-clock 时间);
- 在每个周期开始时, 随机选择一小部分 guest PPN(均匀分布);
- 把这些页的映射 临时作废(比如清 TLB, 无效化 MMU 状态);
- 下一次 guest 访问这些页时, 就会触发一次缺页异常(minor fault), VMM 截获并记录"这个页被 touched 过";
-
统计估计:
- 周期结束时, 统计有多少采样页被访问过;
- 用这个比例推算整个 VM 的活跃内存比例;
-
估计结果可能抖动, 因此需要 平滑处理:
- Slow EWMA(平滑均值): 稳定, 避免频繁波动;
- Fast EWMA: 对突发 workload 增长 敏感, 快速响应;
- "Fast+current"版本: 周期内实时更新, 响应最快;
-
ESX 最终取这三者的 最大值:
- 内存需求增加 立刻放大(快速响应);
- 内存需求减少 缓慢下降(避免过早回收);
- 结果: active VM 能 及时 拿到更多内存, 而 idle VM 的内存 逐渐 被收税;
- 为什么 要快速上涨?
- 当 VM 突然活跃起来, 需要更多内存时:
- 如果 ESX 估计值上升太慢, 它就不会及时分配额外内存给这个 VM; 结果就是 VM
会马上遭遇更多缺页, swap, 性能骤降; 所以 检测到 workload 增加时, 要立刻把 “活跃页数” 估算提高, 这样 ESX 能快速给 VM 补足份额; 保证 VM 性能和响应性;
- 为什么 要缓慢下降?
- 当 VM 的 workload 下降, 活跃内存减少时:
- 如果 ESX 立刻降低估计值并回收内存, 可能出现 “虚惊一场”: workload 只是短暂 idle, 马上又会活跃; 如果内存被收回, VM 会遭遇 reclaim latency(比如 ballooning, swap), 反而增加 overhead; 缓慢下降可以 确认 idle 状态是持续的, 避免频繁的"抢–还"内存抖动; 保证系统稳定性, 降低回收带来的抖动和延迟成本;
- 和 Idle Memory Tax 的关系
- Idle memory tax 会把 idle 内存拿去给其他 VM;
- 如果下降过快: 会"过度征税", VM 立刻失去很多页 性能波动大;
- 如果下降慢: 即使 VM 一时 idle, 还是保留一部分 buffer, 以防 workload 突然反弹;
- 默认 = 75% + 平滑下降 = 既能提高整体利用率, 又避免伤害单个 VM 的瞬时性能;
