
3.PB-Replication & Linearizability
Visibility 可见性
这是分布式设计的一个核心概念, 也就是只有让用户看到的结果才是重要的, 无所谓系统内部在某一个时刻某一个进程/node 的状态是什么样的
这篇笔记在讨论主备复制的情况的时候, 我们的目标是在拥有 2 台主机(不一定都可用)的单位分布式系统中维持 one fault-tolerant, 也就是说允许一个节点失败, 但是系统整体不宕机
主备复制 (Primary/Backup Replication)
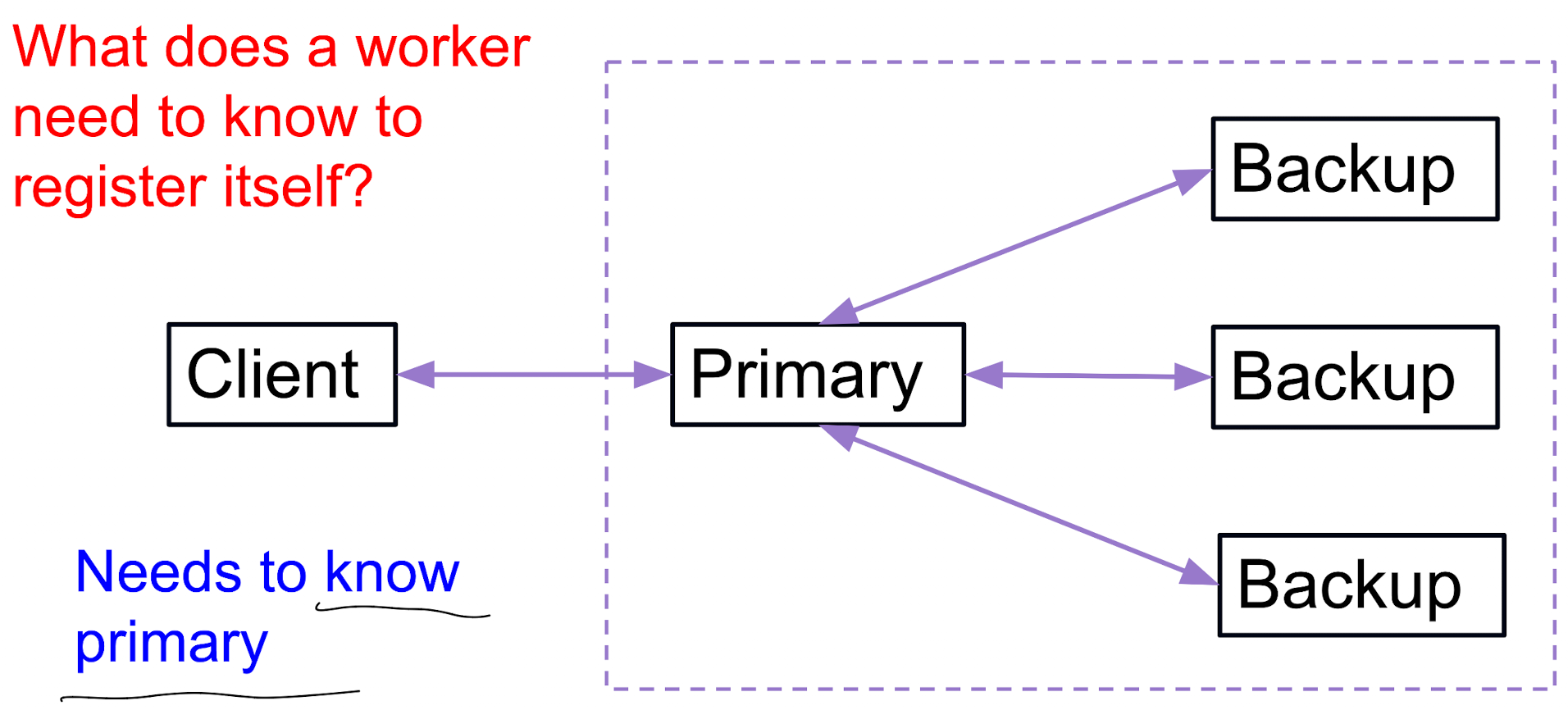
基本机制 (Mechanism)
- 客户端请求先到主节点 (primary)
- client 只需要知道, 也只能知道主节点
- visibility/external consistency: 外部用户能看到的集群整体的状态, 集群内部的信息同步和交互以及 failure 不需要暴露给用户
- 这里还有一层意思就是允许 primary-backup inconsistency.
- 主节点更新后, 同步给备份 (backup)
- 如果要确保高度的一致性, 那么就要在 client 提交请求之后完全完成 client -> primary -> backup -> ack to primary -> ack to client, 整个系统当且只当在 primary 即将发出 ack 到 client 的节点上才真正完成了一致
- 数据要知道存储在两个地方:
- 这个必须发生在用户能知道 update 成功 之前
- 这个也只有在 primary 完成 ack from backup 之后且经过内部判断逻辑真才能实现
同步的机制 Synchronization
- 原则: 只要可能对客户端可见 (visible!) 的更新, 就必须在主备都存储
两个选择:
-
同步 primary snapshot: 即将 primary 的整个内存状态同步到 backup
-
同步 primary 上面的一个或者多个执行流 (sequence of operations to apply)
- 这里有一个理论背景, 就是整个 ds 实际上是一个 deterministic fsm 的设计,
因此在一个确定的初始状态下, 只要执行同样的 sequence of operations, 那么最终的状态一定是相同的 (deterministic)
- 这里有一个理论背景, 就是整个 ds 实际上是一个 deterministic fsm 的设计,
-
一般情况下, 同步执行流简洁, 内容少, 传输快, 且易于实现;
- 不过这里的 sequence of operations 方案有一个要求, 就是每个指令必须被执行 exactly-once, 注意联系上学期 482 说到过的 at-least-once 和 at-most-once 的区别
-
但是仍然保留了 snapshot 方案的可行性: 当我们初始化一个新的 backup 的时候, 我们可以直接从 primary 上面 copy 一份 snapshot 过来, 然后再通过同步执行流的方式来追赶最新的状态, 这样相当于压缩了所有的 后续修改操作, 反而会比 sequence of operations 更高效
View Service
由于 client 永远只能知道有一个 primary 是一定拥有最新的数据的, 无论 ds 内部发生了什么同步情况或者 failure, 我们这里设计一个独立于 ds 的 view service, 其职责是:
- 对 cluster 维护 内部 的 primary/backup 的 view;
- 对 client 提供一个查询接口, 让 client 永远能知道当前的 primary 是谁
由于我们这里的目标是 one-fault-tolerant, 因此在任何时间点, 分布式系统具有如下特征:
- 1 primary
- 0 or 1 backup
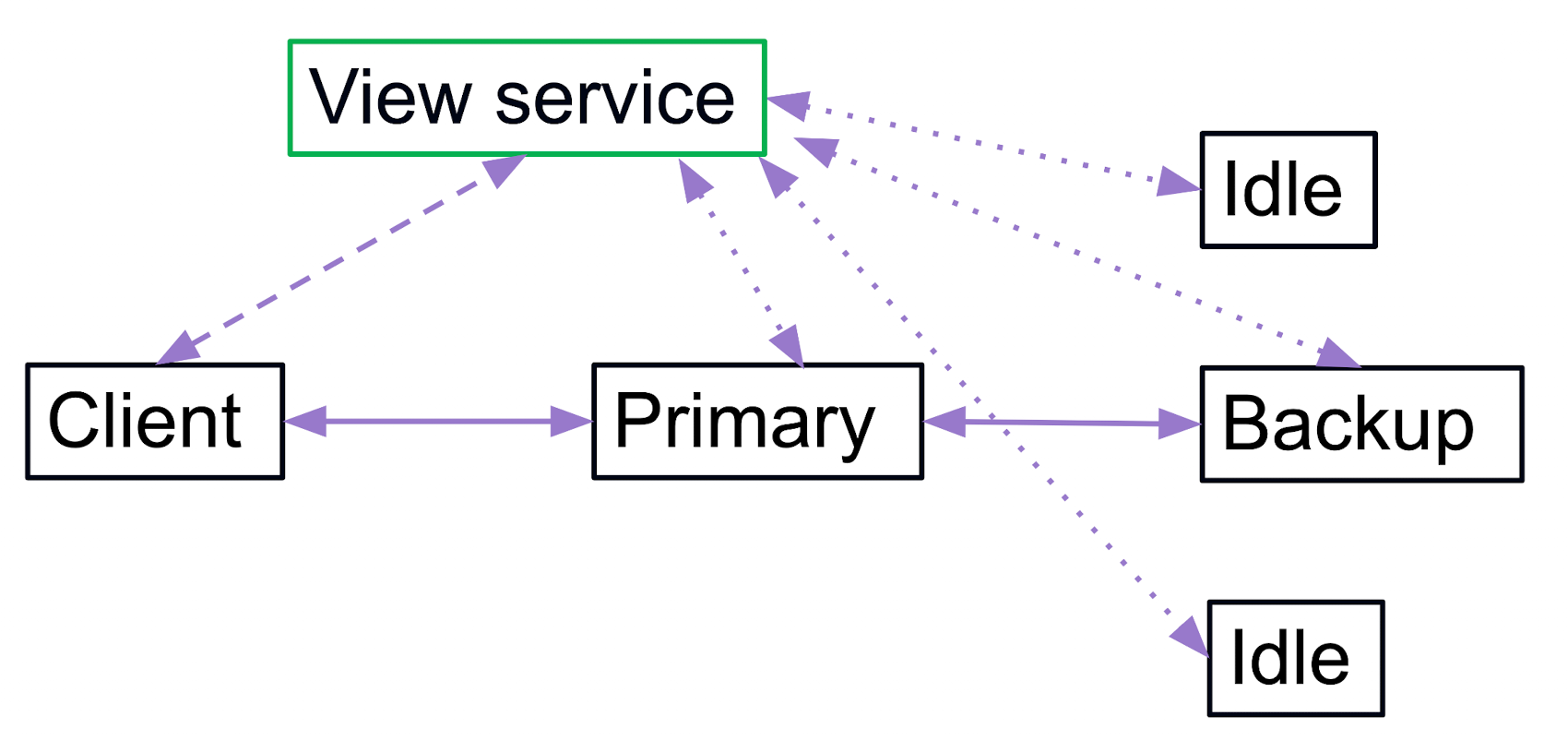
形式化 FSM 方法理解
用形式化来理解 view service 的含义, 就是 Instaneous state of the distributed sys
对于 view state 的形式化定义就是 , 也就是一个非对称 tuple, 其中 primary 和 backup 都是 node 的 id, 如果没有对应的 node, 那么就用 null/下划线 表示
由于 view 会随着 sequence of operation 而对 view 发生变化, 这里的动词参考了 fsm 设计的逻辑, 即 view transition
但是真正导致 view change 的原因只有两种:
- backup 增加: 如果没有 backup 且一个 idle node 加入了分布式集群
- cluster 部来了个年轻 node
- node 减少: 一个在运行的 primary/backup fail (众生平等, 这里 primary 也会 fail)
- 这里的减少的判定通过 heartbeat 机制实现, 即 view service 定期向 primary/backup 发送 heartbeat, 如果在一段时间内没有收到 heartbeat ack, 那么就认为这个 node fail 了
- 所谓 “没来的请举手” 场景
- 一般会设置一个窗口期, 比如 5 个 heartbeat 周期内没有收到 ack 但是就有一个问题了, 如果用户一定要在这个窗口期内发起请求怎么办?
由于这里 view service 作为一个 fsm 的中心管理者, 而分布式的 node 也应该知道自己处于什么样的 view 情况下, 因为作为 primary 是需要:
- 监听 client requests
- 同步更新给 backup
简单说就是这里 primary 和 backup 的责任不对等, 所以每个 node 要知道自己是谁, 也就是要知道当前的 view 的情况, 但是由于 view 经常会变, 但是分布式集群由于对内存的不统一会进一步导致 view 不统一,t就比如网络问题导致不同 node 处理速度不同, 速度快的和慢的 view 版本差异很大, 所以如果不对齐内部处理规则就无法得知了
例子
考虑如下的形式化 cluster 状态转变:
用自然语言描述, 就是:
view1. 初始状态只有一个 primary S1, 没有 backup
view2. 这时候一个新的 idle node S2 加入了集群, 成为了 backup
view3. 这时候 primary S1 fail 了, 于是 backup S2 成为了新的 primary, 并且没有 backup
- 那么这里什么时候可以从 view1 变到 view2 呢?
- 首先要知道 可用, 也就是 S2 需要向 view service 注册
- 什么时候可以从 view2 变到 view3 呢?
- 必须要知道 S2 已经得到 S1 所有最新的数据 (faithful copy of primary)
这里由于是 one-fault-tolerant 设计, 这里不需要考虑在 view1-3 之间发生 primary fail 的情况
Split Brain 脑分裂问题 (View Inconsistency)
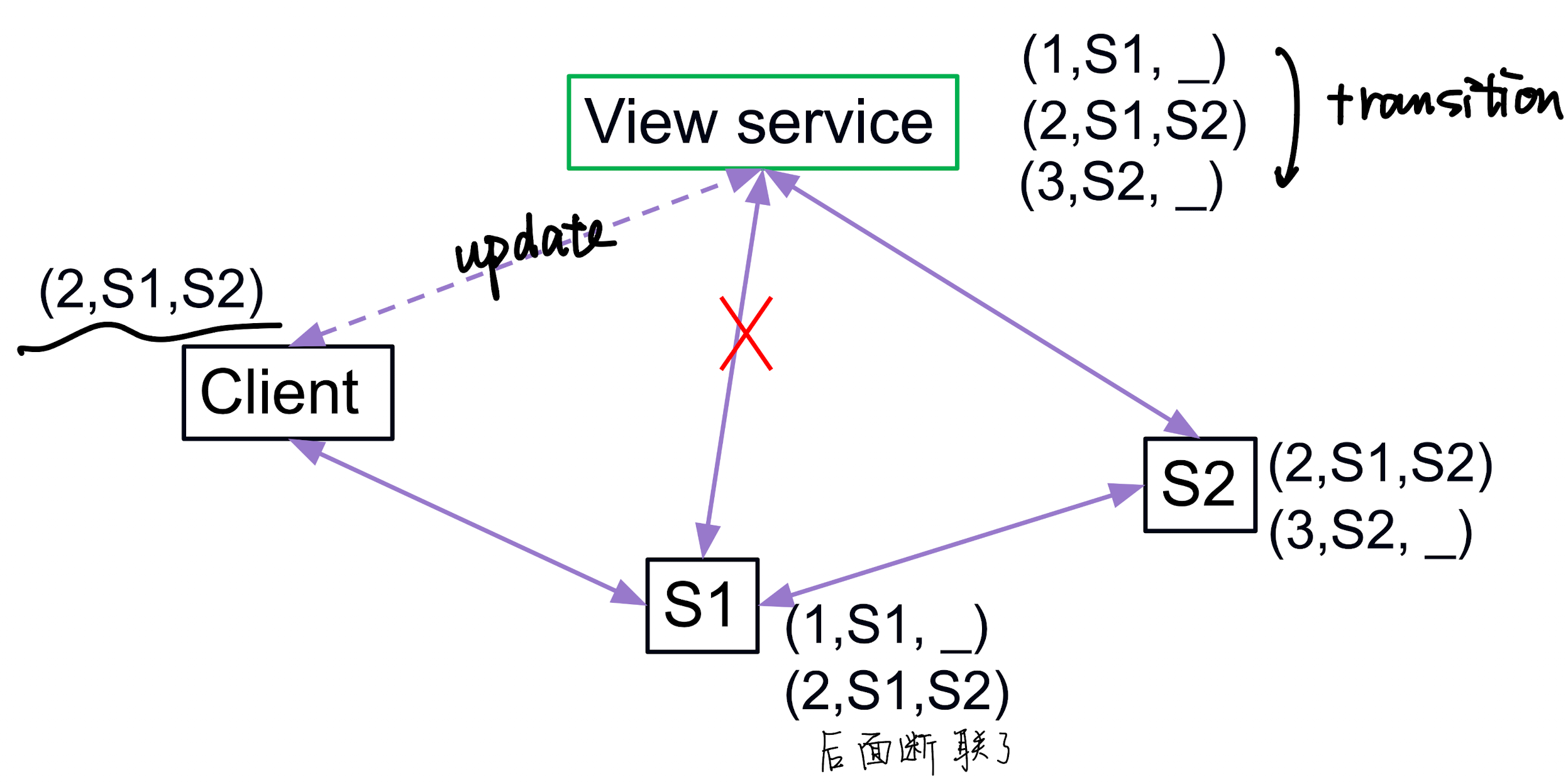
- View service 宣布 (1: S1, _), 所以 S1 是 primary, Client 也会把请求发给 S1;
- 出现网络延迟/分区, View service 觉得 S1 掉线了, 于是把 primary 切换成了 S2(新的 view: (2: S2, _));
- 但与此同时, S1 自己 没收到这个更新, 它仍然认为自己是 primary, 于是现在系统里出现了两个"主":
- View service 认为 primary = S2
- S1 自己认为 primary = S1
如何避免 split brain?
其实仔细想如果一切都理想, 比如 client 在发起请求的时候一定会参考当前的 view service 存储的状态, 那么其实 client 是能知道这里的 primary 已经变成了 S2 从而后续继续向 S2 交互, 且 S2 自己知道自己是 primary, 也就是监听, 接受 client 请求并且同步更新到 backup (当然这里 backup 是空的所以不用同步)
不过在实际世界中这样还是存在一定的现实问题的, 因为网络分区会导致部分用户仍然访问 S1 作为 primary
而且从避免角度来说, 这里主要强调的是 tolerant 这类问题, 也就是让 backup 一定要及时同步来自 primary 的最新数据从而确保数据不会丢失
- 外部一致性 (External consistency)
- 客户端可见的更新必须保证主备一致
- 内部的不一致允许存在, 但不能泄露给客户端
线性一致性 (Linearizability)
线性一致性是分布式系统中一种 强一致性 模型, 确保所有操作看起来像是按某个全局顺序执行的, 并且每个操作都在其调用完成之前完成;
往往是通过 primary 让多个并发的指令来 serialize 串行实现;
强一致性: 系统在任何时间点对所有用户都表现出相同的状态, 无论他们连接到哪个节点; 也就是写入之后的值对所有节点的后续的读取操作都是可见的, 这种强要求往往应用于银行、金融等领域
弱一致性: 系统允许在某些时间点对不同用户表现出不同的状态, 也就是写入之后的值可能不会立即对所有节点的后续读取操作可见, 但是也要满足最终一致性, 即经过足够的时间,分布式集群能够最终收敛到这样的结果; 这种模型通常应用于社交媒体、CDN 等
- Primary 负责序列化 (serialize) 请求:
- Primary 接收到客户端请求后, 不是立刻执行, 而是先决定该请求在全局顺序中的位置(比如 log index);
- Replica 跟随 Primary 的顺序:
- Primary 把请求和它的序号广播给所有 Replica, Replica 必须按这个顺序应用日志;
- 这样无论网络乱序, 并发交错, 最终大家执行的顺序都一致;