
Xen 与 KVM 的 hyprvisor 讲解
虚拟机主要包括四个方面的模拟, cpu, 内存, 中断, io
虚拟机模拟的原理最重要的就是陷入 (trapping) 模拟, 也就是当虚拟机执行一些敏感指令时会陷入kvm, 由kvm负责模拟, 完成后返回客户机
当前主流 (2025) 的虚拟化发展趋势是 Xen -> KVM
Xen 虚拟化基本原理
是一个直接运行在计算机硬件之上的用以替代操作系统的软件层, 它能够在计算机硬件上并发的运行多个客户操作系统(Guest OS)
Xen对虚拟机的虚拟化分为两大类, 半虚拟化 (Para virtualization, PV) 和完全虚拟化 (Hardware VirtualMachine, HV);
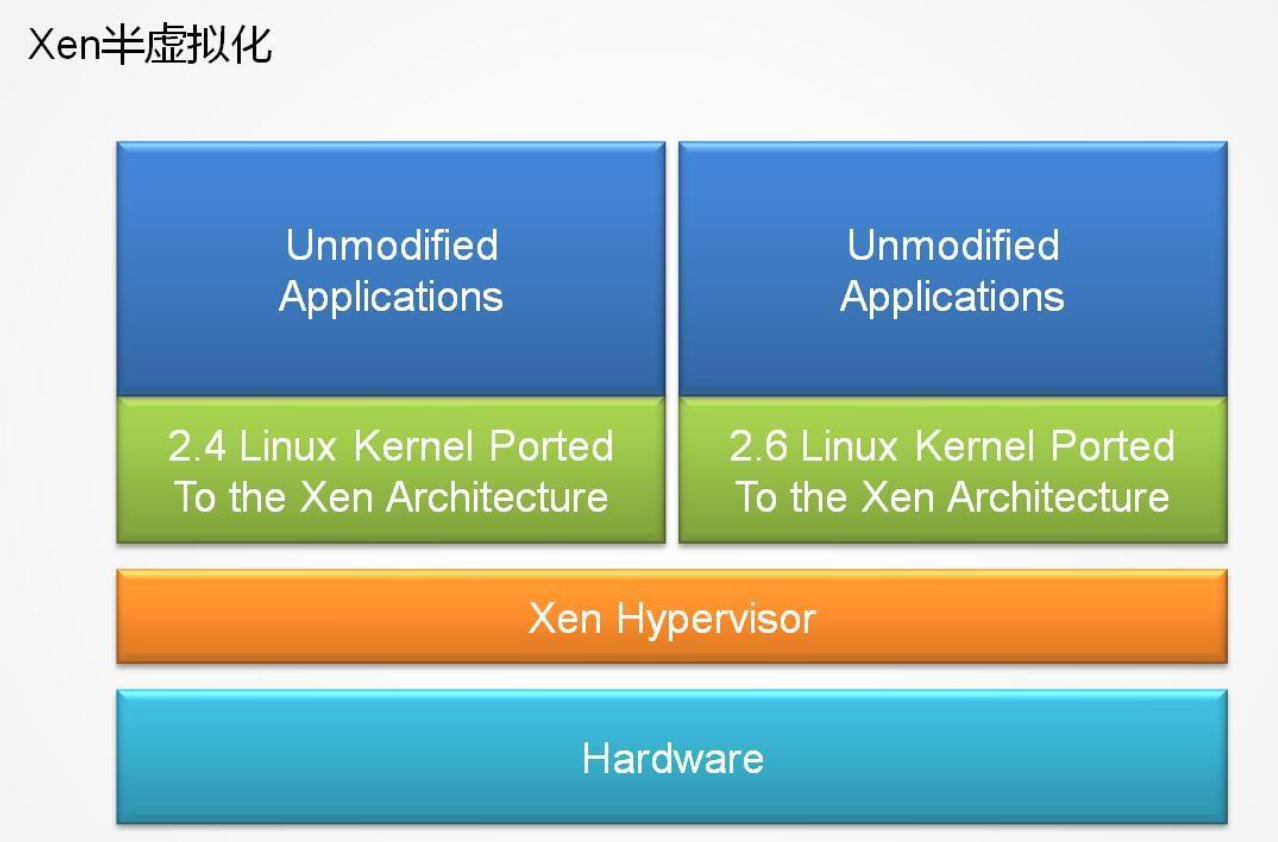
半虚拟化 PV
允许虚拟机操作系统感知到 自己运行在Xen Hypervisor上而不是直接运行在硬件上, 同时也可以识别出其他运行在相同环境中的客户虚拟机
为了调用系统管理程序(Xen Hypervisor), 要有选择地修改操作系统, 然而却不需要修改操作系统上运行的应用程序
完全虚拟化 HV
又称"硬件虚拟化", 简称HVM, 是指运行在虚拟环境上的虚拟机在运行过程中始终感觉自己是直接运行在硬件之上的, 并且感知不到在相同硬件环境下运行着其他虚拟机的虚拟技术
无需任何修改的操作系统版本;同时也需要提供特殊的硬件设备
Dom0 主控域
Xen在初期引入的一个特权Dom, Xen Hypervisor在收到IO请求后, 需要先把请求投递到Domain0, 完成调度处理后, 通过grant copy或者grant map转发到对应的虚拟机, 相比KVM, 整个IO处理路径几乎被拉长了一倍
KVM 虚拟化基本原理
是一种基于linux内核的采用硬件辅助虚拟化技术的全虚拟化解决方案;它最初由以色列的初创公司Qumranet开发, 并在linux-2.6.20中开始被纳入在linux内核, 成为内核源码的一部分
基于硬件辅助的虚拟化来提供全虚拟化的支持, 其以内核模块的形式被加载, 加载KVM模块的linux内核相当于变成了一个Hypervisor, 同时依赖linux内核提供的各种功能来实现硬件管理, 拥有极高的兼容性及可扩展性
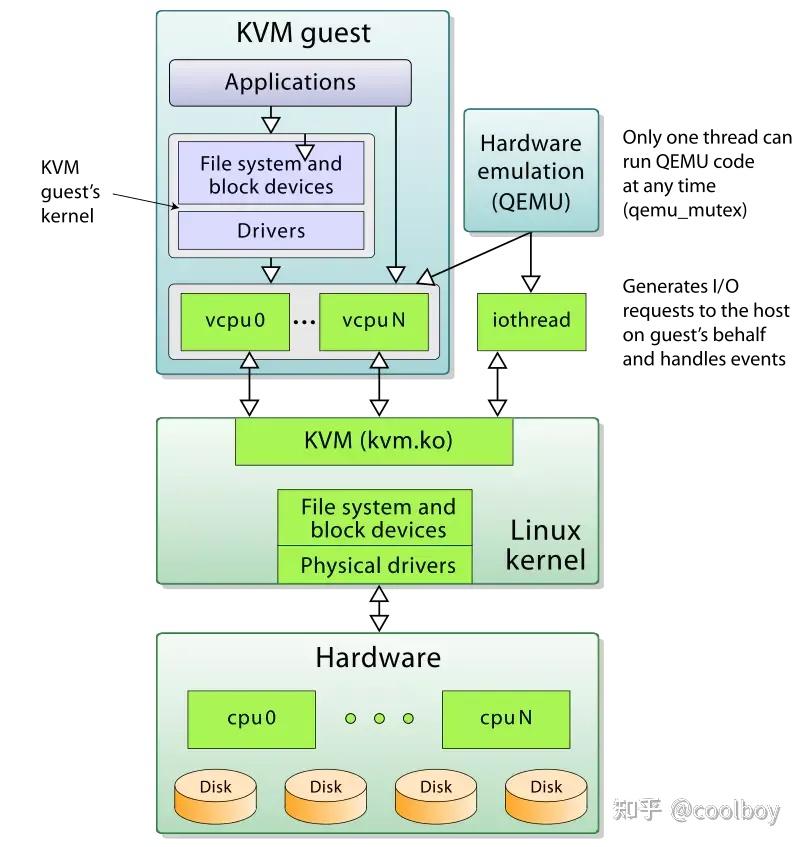
KVM是作为一个内核模块出现的, 所以它还得借助用户空间的程序来和用户进行交互, 这就不得不提到大名鼎鼎的QEMU了
QEMU
QEMU是一套由法布里斯-贝拉(Fabrice Bellard)所编写的以GPL许可证分发源码的模拟处理器, 在GNU/Linux平台上使用广泛
本身是一个纯软件的支持CPU虚拟化, 内存虚拟化及I/O虚拟化等功能的用户空间程序
借助KVM提供的虚拟化支持可以将CPU, 内存等虚拟化工作交由KVM处理, 自己则处理大多数I/O虚拟化的功能, 可以实现极高的虚拟化效率
CPU 虚拟化
在没有CPU硬件虚拟化技术之前都是使用二进制指令动态翻译技术来实现对客户机操作系统中执行的执行(例如qemu的软件虚拟化), 其不仅实现复杂而且效率非常低下
Hypervisor 需要模拟一些操作, 例如VM里运行的软件试图配置处理器的一些属性, 如电源管理或是缓存一致性时;通常你不会允许VM直接配置这些属性, 因为这会打破隔离性, 从而影响其他VMs; 这就需要通过以陷入 (trapping) 的方式产生异常, 在异常处理程序中做相应的模拟
内存虚拟化
给虚拟客户机操作系统提供一个从0开始的连续的地址空间, 同时在多个客户机之间实现隔离与调度
IO 虚拟化
I/O设备作为一种外部设备, 其虚拟化的实现相较于前面的CPU虚拟化及内存虚拟化有些不同, 其目前主要有以下四种虚拟化方案;
1, 设备模拟:
在虚拟机监控器中模拟具体的I/O设备的特性, 例如qemu;在KVM和qemu的组合中通过Hypervisor捕获Guest OS的I/O 请求交给用户空间的 qemu 进行模拟, 然后将结果再通过 Hypervisor 传递给 Guest OS;这种方式能够提供非常好的兼容性但是性能太差, 同时模拟设备的功能特性支持不够多
2, 前后端驱动接口
在 Hypervisor 和 Guest OS 之间定义一种权限的适用于虚拟机的交互接口, 比如 virtio 技术;这个方案相较于设备模拟在性能上有所提高, 但是兼容性较差, 而且在高 I/O 负载场景, 后端驱动的 CPU 占用较高;
3, 设备直接分配
将一个物理设备直接分配给Guest OS使用;此方式的性能显而易见, 要比上面两种好很多, 但是需要硬件设备支持, 且无法共享和动态迁移;
4, 设备共享分配
此方式是设备直接分配的一个扩展, 其主要就是让一个物理设备可以支持多个虚拟机功能接口, 将不同的接口地址独立分配给不同的Guest OS使用;如SR-IOV协议