
Kernel Bypass 与 eBPF 框架
Kernel-Bypass 内核旁路技术
主要是为了解决超大并发下内核态与用户态之间的性能问题, 技术代表有 DPDK, eBPF等
随着移动互联网的发展, 云架构中复杂的服务治理已经将C10K的问题发展到C10M(单机并发 1000 万);一个大规模集群内, 面对东西向规模性的Gbp/s数据流量, 关键节点的挑战是用户态协议栈和多核并发问题
这个时候Linux 网络协议栈进行的各种优化策略, 基本都没有太大效果;网络协议栈的冗长流程才是最主要的性能负担
内核瓶颈限制
基于系统内核的数据传输会面临如 中断处理, 内存拷贝, 上下文切换, 局部性失效, CPU亲和性, 内存管理等等影响, 在高并发的场景下这些机制是非常大的瓶颈所在;
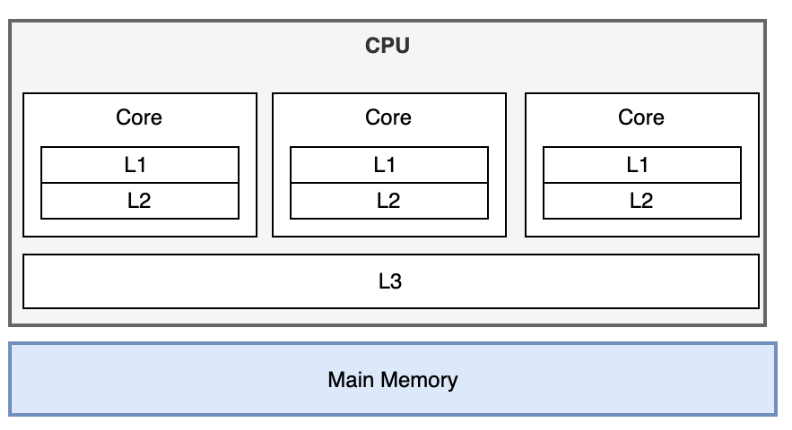
如图所示, 可以知道 L1, L2 层级的 cache 并不会在不同的 core 之间共享, 但是, L3
层级是允许不同 core 之间共享的, 也就是说在进行 switch context 操作的时候, L1 L2 层级的 cache 会发生 cache miss, 这无法避免, 并且在 超高并发的背景下, 上下文切换是非常频繁的, 因此 缓存 miss 的情形常常发生
为了避免这个内核瓶颈遏制了高性能发展, 采用内核绕过技术 (KB)
eBPF
eBPF (extended Berkeley Packet Filter) 是一种在 Linux 内核中运行的虚拟机技术, 允许用户在内核空间中运行自定义的程序, 这些程序可以用来处理网络数据包, 监控系统性能, 安全审计等任务
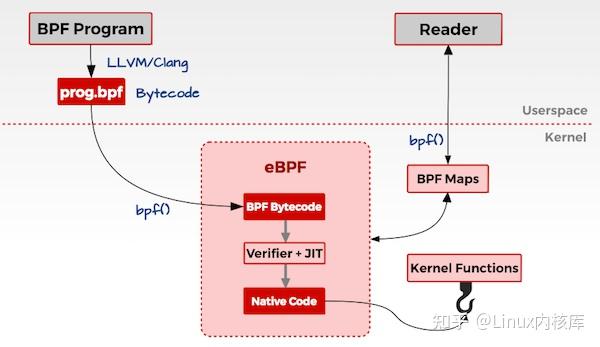
用户态
用户编写 eBPF 程序, 这些程序通常用 C 语言编写, 然后使用 LLVM(clang) 编译器将其编译为 eBPF 字节码
调用 bpf() 系统调用把编译后的 eBPF 字节码加载到内核中
内核态
- 当用户调用 bpf() 系统调用把 eBPF 字节码加载到内核时, 内核先会对 eBPF 字节码进行安全验证;
- 使用 JIT(Just In Time)技术将 eBPF 字节编译成本地机器码(Native Code);
- 然后根据 eBPF 程序的功能, 将 eBPF 机器码挂载到内核的不同运行路径上(如用于跟踪内核运行状态的 eBPF 程序将会挂载在 kprobes 的运行路径上);当内核运行到这些路径时, 就会触发执行相应路径上的 eBPF 机器码;
AOP (Aspect Oriented Programming 面向切面编程)
对于系统层面的一些需求比如系统日志, 性能统计等, 分散在软件的各个角落, 维护起来很是不爽, 这种问题的解决确是oop力所不能及的, 于是AOP横空出世: 就是单独创建一个类,专门捕捉对应类 (包括继承多态等关系, AOP 中称为 拦截器) 的对应活动 (AOP 中称为 切点) 之后执行自定义的类似操作