
1. Kubernetes 核心概念
本篇文章参考了知乎笔记, 只做格式整理
如何区分 apiVersion
- v1: Pod, Service, ConfigMap, Secret, Namespace, PersistentVolumeClaim
- apps/v1: Deployment, StatefulSet, DaemonSet, ReplicaSet
accessMode 访问模式
ReadWriteOnce(RWO): 只能被单个节点挂载读写ReadOnlyMany(ROX): 可以被多个节点挂载为只读ReadWriteMany(RWX): 可以被多个节点挂载读写ReadWriteOncePod(RWOP): 只能被单个 Pod 挂载读写, 是在 Kubernetes 1.22+ 和一些 CSI 驱动下才支持的模式, 保证同一卷只能被同一个 Pod 读写, 即使 Pod 在不同节点重调度也不允许与其他 Pod 并发访问
Service 服务
- 内部服务: 通过统一的接口来访问一组 Pod, 使得 Pod 的 IP 地址可以动态变化, 而不影响访问者的使用 (对访问者透明)
- 外部服务: 通过统一的接口放接受外部的访问输入
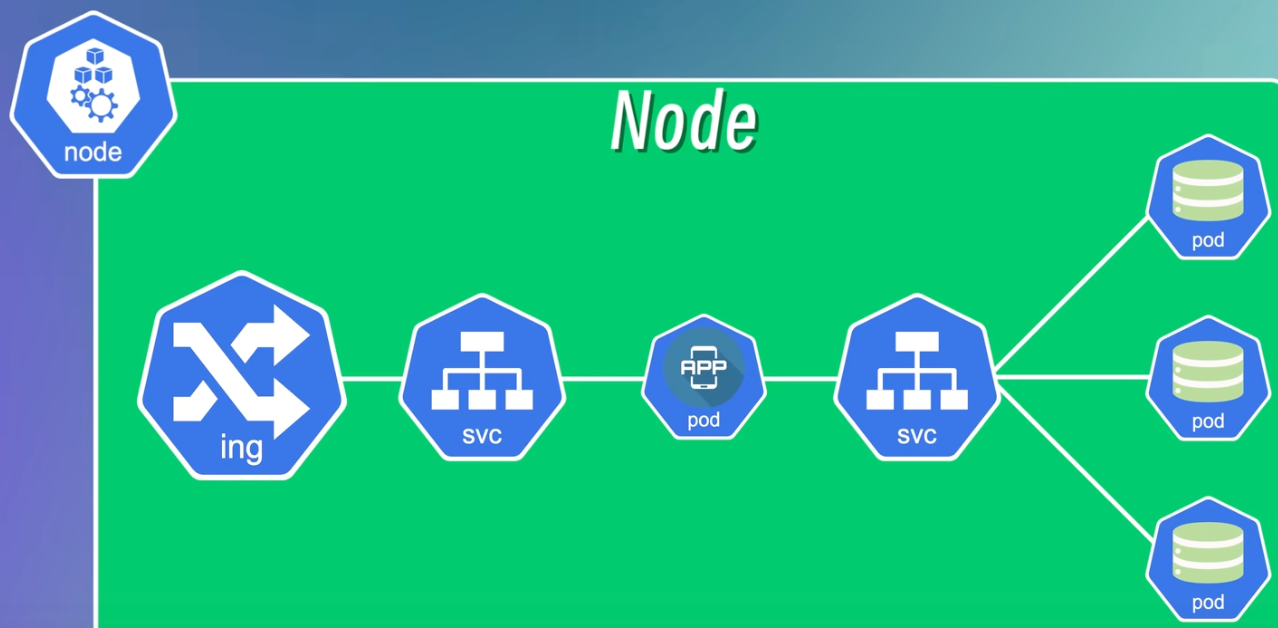
Headless Service 无头服务
- 在 Kubernetes 中定义一个 Service 时, 如果我们将
clusterIP: None设置在 Service 中, 就创建了一个 Headless Service; - 这意味着 Kubernetes 不会为这个 Service 分配一个虚拟 IP, 也不会自动做负载均衡, 而是会将 DNS 查询解析为后端每一个 Pod 的 IP 地址;
- 默认的 pod 会为了负载均衡来隐藏 pod 名称和 ip 地址, 而 Headless Service 则会暴露 pod 名称和 ip 地址;
- 通过暴露这些信息来允许直接访问, 独立持久化存储
Config Map 配置映射
- 使用k8s部署应用, 当你将应用配置写进代码中, 就会存在一个问题, 更新配置时也需要打包镜像, configmap可以将配置信息和docker镜像解耦;
- 使用微服务架构的话, 存在多个服务共用配置的情况, 如果每个服务中单独一份配置的话, 那么更新配置就很麻烦, 使用configmap可以友好的进行配置共享;
使用ConfigMap有以下几个限制条件:
- ConfigMap必须在pod之前创建
- Configmap受namespace的限制, 只能相同namespace的pod才可以引用
最简单的例子就是, 部署 hdfs-kubernetes 环境的时候, 使用一个 configmap.yaml
来专门存储 hdfs 的配置文件 (即 core.xml 和 hdfs-site.xml) 即可
Stateful Set 状态集合
Deployment 只适合于编排"无状态应用", 它会假设一个应用的所有 Pod 是完全一样的, 互相之间也没有顺序依赖, 也无所谓运行在哪台宿主机上;
正因为每个Pod都一样, 在需要的时候可以水平扩/缩, 增加和删除 Pod
但是并不是所有应用都是无状态的, 尤其是每个实例之间有主从关系的应用和数据存储类应用, 针对这类应用使用Deployment控制器无法实现正确调度, 所以Kubernetes里采用了另外一个控制器StatefulSet负责调度有状态应用的Pod, 保持应用的当前状态始终等于应用定义的所需状态
什么是StatefulSet
当你需要关心Pod的部署顺序, 对应的持久化存储或者要求 Pod 拥有固定的网络标识(即使重启或者重新调度后也不会变)时, StatefulSet控制器会帮助你, 完成调度目标
每个由StatefulSet创建出来的Pod都拥有一个序号(从0开始)和一个固定的网络标识;你还可以在YAML定义中添加 VolumeClaimTemplate 来声明Pod存储使用的PVC
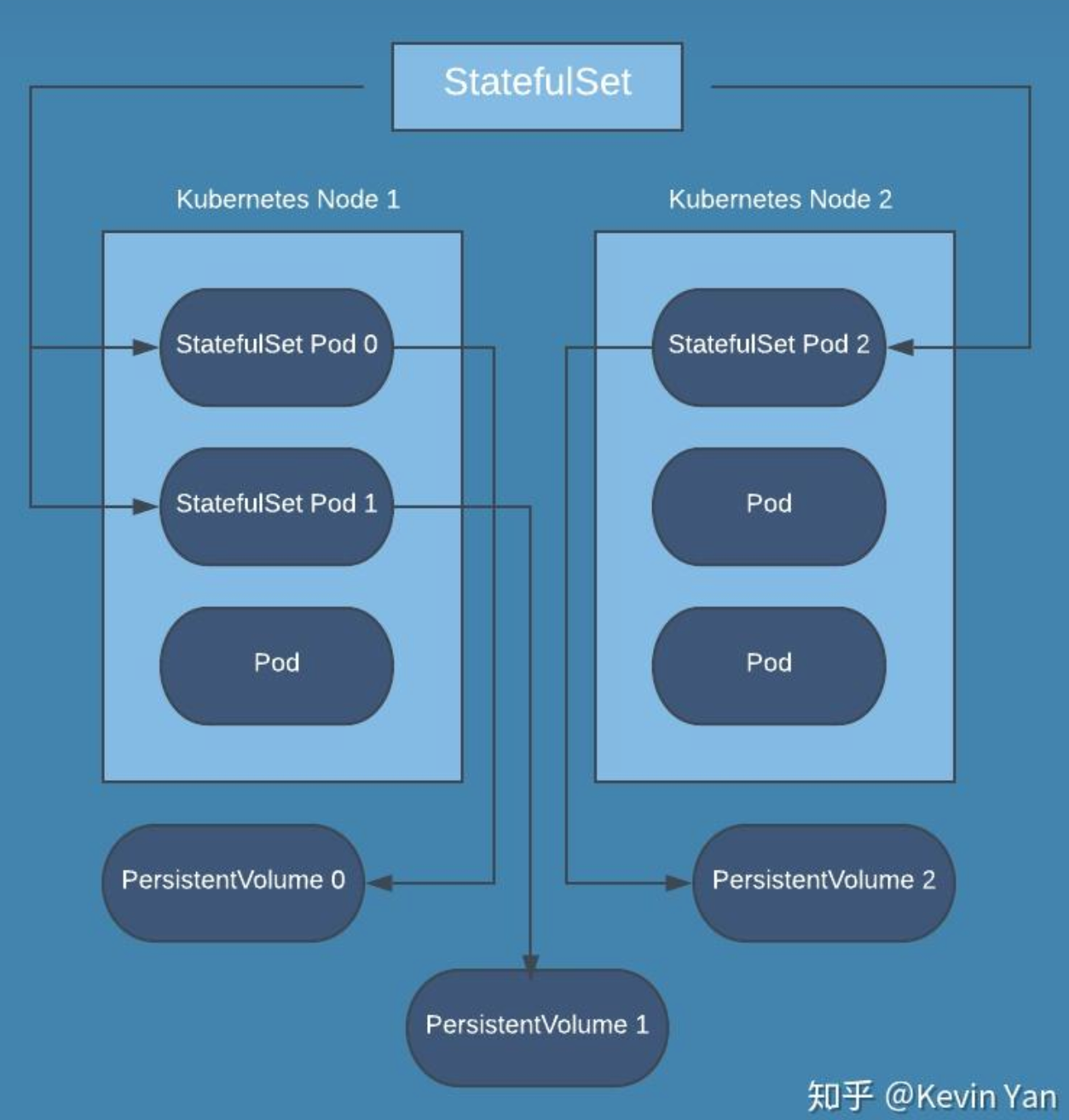
StatefulSet 把有状态应用需要保持的状态抽象分为了两种情况:
- 拓扑状态; 这种情况意味着, 应用的多个实例之间不是完全对等的关系;这些应用实例, 必须按照某些顺序启动
- 比如应用的主节点 A 要先于从节点 B 启动;而如果你把 A 和 B 两个 Pod 删除掉, 它们再次被创建出来时也必须严格按照这个顺序才行;
- 并且, 新创建出来的 Pod, 必须和原来 Pod 的网络标识一样, 这样原先的访问者才能使用同样的方法, 访问到这个新 Pod
- 存储状态; 这种情况意味着, 应用的多个实例分别绑定了不同的存储数据;
- 对于这些应用实例来说, Pod A 第一次读取到的数据, 和Pod A 被重新创建后再次读取到的数据, 应该是同一份 ;
- 这种情况最典型的例子, 就是一个数据库应用的多个存储实例;
所以, StatefulSet 的核心功能, 就是通过某种方式记录这些状态, 然后在 Pod 被重新创建时, 能够为新 Pod 恢复这些状态
保持应用的拓扑状态
Headless Service
想要维护应用的拓扑状态, 必须保证能用固定的网络标识访问到固定的Pod实例, Kubernetes是通过Headless Service 给每个Endpoint(Pod)添加固定网络标识的, 所以接下来我们花些时间了解下Headless Service
Service: Service 是在逻辑抽象层上定义了一组Pod, 为他们提供一个统一的固定IP和访问这组Pod的负载均衡策略;
对于 ClusterIP 模式的 Service 来说, 它的 A 记录的格式是: serviceName.namespace.svc.cluster.local, 当你访问这条 A 记录的时候, 它解析到的就是该 Service 的 VirtualIP 地址;
对于指定了 clusterIP=None 的 Headless Service来说, 它的 A 记录的格式跟上面一样, 但是访问记录后返回的是Pod的IP地址集合;Pod 也会被分配对应的 DNS A 记录, 格式为: podName.serviceName.namesapce.svc.cluster.local
普通的Service都有ClusterIP, 它其实就是一个虚拟IP, 会把请求转发到该Service所代理的某一个Pod上