
2. Predictive and Adaptive Failure Mitigation to Avert Production Cloud VM Interruptions
When a failure occurs in production systems, the highest priority is to quickly mitigate(缓解) it.
Failure Mitigation (FM) is done in a reactive and ad-hoc way, namely taking some fixed actions only after a severe symptom is observed.
Propose a preventive and adaptive failure mitigation service, NARYA, that is integraed in a production cloud, Microsoft Azure’s compute platform
- Narya predicts imminent(迫在眉睫的) host failures based on multi-layer system signals
- then decides smart mitigation actions
- goal: avert(避免) VM failures
- Narya’s decision engine takes a novel online experimentation approach to continually explore the best mitigation action.
- enhances the adaptive decision capability through reinforcement learning.
Introduction
key question
once a failure occurs, how to quickly detect and mitigate it so the system can continue running?
Mitigating a failure here means attempting to make the failure symptom disappear without necessarily diagnosing and fixing the underlying bugs first.
Problem: for large cloud infrastructure (like Ali-Cloud), only employing post-failure(失败后的) detection and mitigation techniques is insufficient.
Cloud systems should also design techniques to address the question of, whether a failure may be imminent, and if so, what preventive actions should be taken to avert this failure?
Current Work and Limits
Several recent works tackle the failure prediction problem in the context of disk failures. But they focus on prediction alone, with the goal of alerting operators or providing allocation hints
Narya
An end-to-end service with predictive and smart failure mitigation fully integrated in the Azure compute platform for its Virtual Machine (VM) host environment.
Goal of Narya: prevent VM failures ahead of time and enhance the self-managing capability of the Azure compute platform for providing smooth VM experience to customers
Challenge:
- (背景原因:)With multi-tenancy, heterogeneous infrastructure components, and diverse customer workloads, it is difficult to(操作难度) comprehensively categorize different failure scenarios in a large cloud system beforehand and determine good mitigation actions (or their parameters), especially without trying it
- the cloud system is constantly changing (software/hardware updates, customer workload changes), some mitigation action that worked well in the past may no longer be optimal.
Nothing is accessable or assessable before we try it: explorations with production workload is indispensable(必不可少的) to determine the (near-)optimal failure mitigation action.
should ensure that the actions taken maximize the expected effectiveness (minimize the potential customer impact) over time
A/B Testing
Narya predicts whether host nodes in the production fleet will likely fail and then leverages A/B testing to continually experiment with different mitigation actions, measure the benefits, and discover optimal actions.
Background and Motivation
Traditional System
A traditional system’s operation cycle is as follows: a failure is detected; developers diagnose the failure and find out the root cause; a patch is written; the system is re-deployed.
Cloud System
operating in this exact sequence is problematic
because the time it takes to identify the root cause and develop a fix is usually long and exceeds the downtime budget.
Instead, once a failure is detected, some mitigation action like restart (重启解决 90% 的问题, 重启两次解决 99% 的问题) will be applied first without necessarily knowing the bug.
Target System and Goal
Our specific target system is the VM host environment, a node
The node is backed by locally attached disks and remote virtual disks. Each node is connected to various compute services, together referred to as controller, that is responsible for provisioning resources and performing management actions such as creating and destroying VMs.
Currently Azure already has monitor (real-time detect the failure), but we want to predict
The end goal is to avoid future VM failure events.
Are Failures Predictable
2 Basic Requirements:
- the imminent failure is not abrupt
- there is telemetry recorded to indicate the degradation
Hardware Wear Out: predict the failure by the age of the hardware, combined with other system signals such as workload patterns
Software Resource Leak: including memory/file handle/network ports leak, is a common type of predictable software failure. Predict them using the resource usage trend. If failures are correlated with certain hidden factors such as timeout settings, bugs related to timers, and release schedule, they may also occur on a predictable basis.
Why Static Mitigation is Insufficient
If we use fixed plan for VM failures, then we follow these steps
- block allocation on the node;
- problem here: Blocking allocation results in capacity pressure while for some predicted failures, avoiding allocation may be better.
- try to live migrate VMs;
- Some failures may be too severe to do live migration (e.g., broken disks). Forced migration causes unnecessary customer impact if nodes are still healthy after 7 days.
- wait for 7 days for short-lived VMs to be destroyed by customers;
- force migration of remaining VMs;
- mark the node offline and send it for repair;
- Marking nodes offline is also suboptimal when capacity is low
Overview
Narya advances the current practice of failure mitigation in two ways:
- replacing existing static and ad-hoc mitigation assignment to adaptive and systematic decision algorithms;
- transforming the traditionally reactive, post-failure mitigation activity to proactive failure avoidance mechanisms.
Workflow
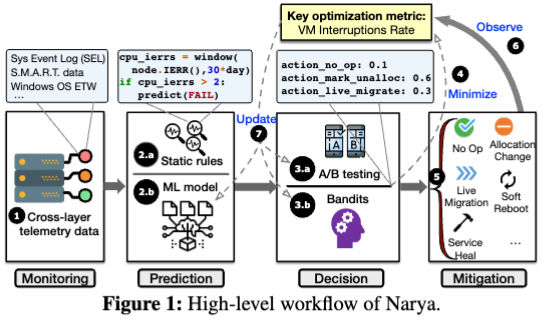
Optimization Metric
objective is to reduce and minimize the overall customer impact caused by node failures on the fleet
- is any given measured interval duration in days
- VM interruption in this paper mainly refers to reboots or loss of heartbeats
Optimization Background in Azure
First, long-duration incidents are now rare in Azure. VM interruptions become more common that require addressing
Second, short VM interruptions can significantly disrupt user experiences, e.g., for gaming type applications.
Third, for VMs that run applications like databases, even if the VM only experiences a short interruption, the applications take time to recover, which translates into a longer user-perceived interruption.
Fourth, based on communications with customers, customers can be more annoyed if their VMs get frequently interrupted when compared to a single longer-time interruption.
Challenges
First, failure mitigation has to act with incomplete information since the underlying root cause is not known.
Second, due to the massive scale of a cloud system, there are many factors to consider in the decision logic.
Third, our experience suggests that when incorporating failure prediction into a production cloud system, false positives are unavoidable due to the complex system environment, large number of noisy signals, unexpected customer workloads, etco
Lastly, failure mitigation is a mission critical procedure. If not designed well, a decision engine may do more harm than good. Ensuring safety should be a top priority for Narya.
Predicting Node Failures
describe two prediction methods Narya uses:
(1) static threshold rules written by domain experts;
(2) machine learning model-based prediction
Input Signals
Narya consumes telemetry signals from the entire stack of the host environment to make informed prediction.
Hardware/Firmware: the monitoring agents collect low-level logs from disk SMART attributes, memory (e.g., uncorrectable errors), CPU (e.g., machine check error), motherboard (e.g., bus error), etc.
A higher-level source of signals comes from device drivers, e.g., timeout events
Repetition of such events is often an indicator of an imminent failure
Control-Plane Operations: For example, repetitive VM creation operation errors could indicate serious host issues even if the host still appears to be running. Such signals help reduce the observability gap
Rule-based Prediction
Analyze the common failure patterns and the available telemetry signals to predict failures that have significant customer impact.
rules are manually written in json/py/cpp, they are simple and easy to understand
works best for definitive signals that indicate some severe issue with high confidence
Drawbacks/Limitations
Since many failure signals are not definitive, rule-based prediction cannot cover a wide range of imminent failures. In addition, the prediction may come late and do not provide enough lead time for the mitigation engine.
Learning-based Prediction
It can predict many complex host failures. It also can predict earlier, thus leaving longer time for the mitigation engine to react.
Use supervised learning, which is similar to the previous works, but a main difference is that we focus on overall host health and failures that result in customer impact, instead of failures of individual components.
Learning Labels
- Negative Label: normal state
- Positive Label: dangerous to failure state
Short Time: For Narya, the host view of a failure is different from individual components’ view. The host failures could be unresponsive host, VM creation failure, host OS crash, etc. These temporary failure could happen much earlier than the permanent failure of a component.
System-View: certain faults might not be a problem to the source component but could be problematic from host’s view.
To get accurate and useful prediction result, we only use host failures that result in customer impact and are later con- firmed to be caused by some hardware component faults during diagnosis.
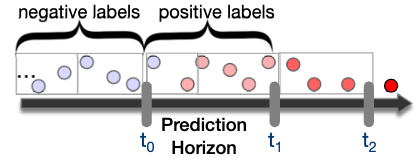
For training, it use the time unit hour, which means that it attach positive label for back to , and that before it is labeled as negative. The variable is called the horizon (usurally production horizon is set ot 7 days)
we looked at the feature distribution of failed nodes and measured the same distribution of healthy nodes.
Machine Learning Model
Binary Classifier: given signals, labels, host metadata, Narya’s predictor output hte failure probability of a host (we use 0.5 as the cutoff).
- Gradient boosted tree model (commonly used supervised learning method)
- combines decisions from a sequence of simple decision trees with a model ensembling(集成的) technique called gradient boosting
- Attention-based deep learning model
- reducing the feature engineering efforts by directly learning the features
- aim to learn both spatial features and temporal features
- Spatial: compare one component to its neighbors, e.g., one host often has multiple disks configured under RAID 0 (一排硬盘同时写入无 replica), thus they are expected to perform similarly -> if one disk is slower, then considered as imminent host failure
- The temporal features characterize changes in components over time
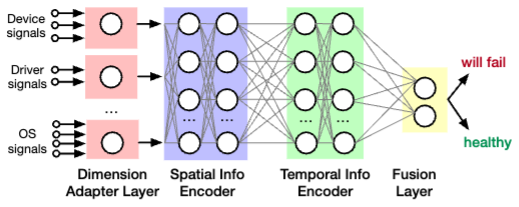
- dimension adapter layer to unify the dimension of signals from different sources
- employ a spatial information encoder based on self-attention
- calculates weights of a component’s neighbors
- the weighted sum of the neighbors’ feature vector represent its spatial information
- the temporal information encoder
- consists of positional encoding, self-attention, and location-based attention layers.
- employ a fusion layer to do binary classification.
Mitigation Actions

Table 2 lists the main primitive actions in Azure. Mitigating a failure often requires multiple primitive actions
An aggressive goal for Narya is to explore the actions arbitrarily and figure out the optimal combination. But this could potentially bring significant customer impact. Instead, Narya mitigation engine focuses on exploring pre-defined composite actions
Followings are implementations of the primitive actions
Live Migration
Goal: moves a running VM from one host to another with minimum disruptions.
Migration process involves transfer of the VM’s memory, processor and virtual device state
- The LM engine iteratively copies the VM’s memory pages while maintaining a dirty page set for the VM on the source host.
- Based on the dirty page rate, network bandwidth, the engine determines the maximum iterations to stop the VM
- After the VM is stopped, the LM engine synchronizes the dirty state with the target and resumes the VM on the target host
VM Preserving Soft Reboot
Used to preserve the VM state across a reboot of the host OS
The host OS kernel is reloaded into memory, the VM memory and device state are persisted to the newly loaded kernel.
The persisted state is restored and the rest of the state in the prior kernel are discarded
The restored VM experiences a brief pause similar to the live migration
Service Healing
used to restore the service availability of unhealthy or faulty VMs
Live Migration can fail or cannot be applied due to certain constraints such as network boundary
Service healing works for more general scenarios: The faulted VMs will be isolated by powering down or disconnecting from network. The controller generates a new assignment of the VM to healthy nodes
Mark Unallocatable
blocks allocation of new VMs to a host for some time T
often used before other primitive actions(like LM) are taken (recall eecs482 final’s last problem use the pin and unpin to protect the disk io lock).
Avoid
informs the allocator to try to avoid adding new VMs on this host (weaker constraint)
Blocking allocation has a strong impact on capacity since the host is not eligible for getting new VMs.
Thus, the number of hosts that can be marked unallocatable at the same time is limited (also recall the eecs482 final, pin has a upper bound, but not the exact same reason here).
NoOp
he controller does not take any action. This is the baseline to measure the benefits of prediction and taking actions.
Decision Logic for Adaptive Mitigation
Online Experimentation with A/B Testing
Narya System Design and Implementation
describe the system support for Narya
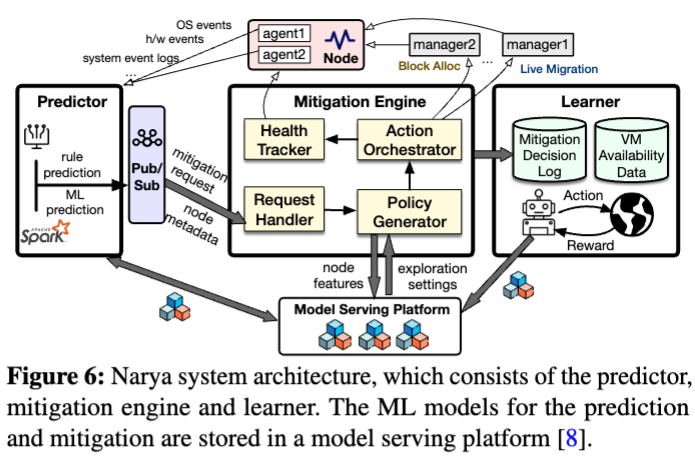
The Narya system must be able to process the massive signals and requests from the entire fleet with low latency and reliability.
Failure Predictor
deploys various agents in each node to monitor the health of the host environment. The Narya predictor ingests(摄取) health signals from these monitoring agents and runs rule based prediction and ML-based prediction
Rule-based prediction has low cost and high priority. Thus its prediction logic is executed directly in the host
ML-based prediction inspects much more signals such as performance counters and runs more complex prediction logic. Thus, the ML predictor is implemented as a centralized service.
It(ML-based) collects raw signals from monitoring agents using micro-batches (small groups) and incrementally processes them. Open source technologies are used for ML modeling (LightGBM + PyTorch).
Pub/Sub Service 发布订阅模式服务 (Publish+Subscribe)
A mitigation request is created if a node is predicted to fail with high probability.
The predictor publishes the request along with metadata information about the host (e.g., hardware generations, OS version) to a central pub/sub service, which we implement on top of Kafka.
Mitigation Engine
Internally, it is composed of four major microservices. These microservices communicate with each other and other services in Azure using REST APIs.
Create Mitigation Job
The Request Handler microservice consumes(Kafka Consumer) mitigation requests from the Pub/Sub service.
Upon receiving a mitigation request, it creates a mitigation job with a job Id. This job Id is used by other micro-services to track the mitigation and query its progress.
Instantiate Mitigation Policy
For a new mitigation job, the Policy Generator creates a mitigation policy, which maps the information from the request to the action to take. (represented as a decision tree)
2 types of nodes:
Selectionnode, which chooses the tree node to visit next based on someC#predicate;Actionnode, which executes a user-definedC#function.
The decision tree structure allows us to easily specify the decision logic.
The policy generator then applies safety constraints on the retrieved exploration setting to obtain an adjusted action probability distribution.
Additionally, the mitigation policy allows imposing rate limit for a tree node to avoid excessive mitigation that could cause capacity issue or cascading failures
Walk Policy Tree
Generator traverses the policy tree in DFS order and creates an action plan.
The generator performs many steps such as checking predicates, checking rate limit conditions, etc.
Carry out Action Plan
The Action Orchestrator microservice is responsible for carrying out the action plan asynchronously from the policy tree walk session
This step involves making API calls to the corresponding compute managers since different actions may be implemented by different managers
Log Action
The logging format for Bandit learning is special since it requires not only recording the chosen action but also the associated probability.
In particular, the mitigation engine will log the action timestamp, experiment name, model type, model name, model version, action distributions, chosen action, chosen action parameters, etc.
Track Node Health
The Health Tracker tracks node and VM health information during the mitigation process
Learner
a centralized component in Narya, learns the effect of mitigation action across different data center regions
Advantage:
- observing more data points and hence more confidence in the cost estimation
- a mitigation effect change in certain region due to software/firmware updates could be quickly learned and applied to other regions rolling out the same updates.
2 main jobs:
- Cost collection
- retrieves the mitigation engine’s decisions from the logs
- then correlated with the VM availability measurements and other important information
- determine the cost of the mitigation action for training
- Bandit model training
- The output model of the learner is a categorical distribution, which the model server can easily draw samples from