
1. AIOpsLab: A Holistic Framework to Evaluate AI Agents for Enabling Autonomous Clouds
AI for IT Operations (AIOps) aims to automate complex operational tasks, such as fault localization and root cause analysis
- traditional: ddressing isolated operational tasks
- LLM and AI agents: enabling end-to-end and multitask automation
Target: self-healing cloud systems, a paradigm we term AgentOps
AIOpsLab
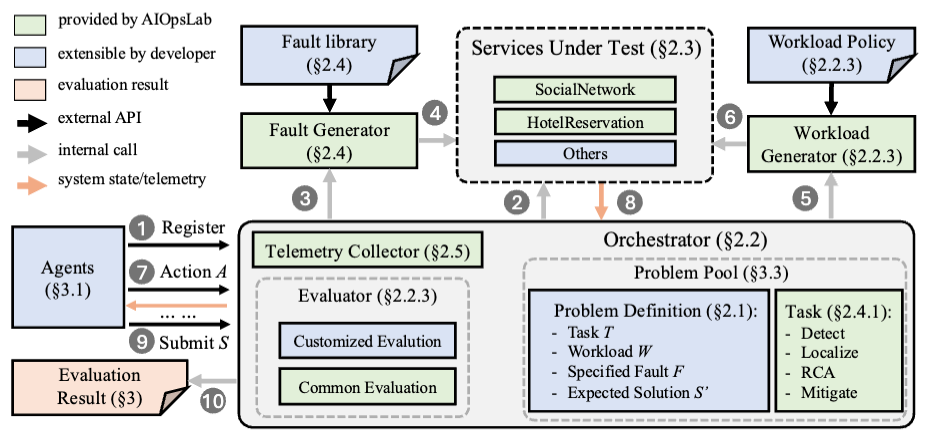
a framework that not only deploys micro-service cloud environments, injects faults, generates workloads, and exports telemetry(遥测得的) data but also orchestrates these components and provides interfaces for interacting with and evaluating agents.
The ultimate goal of AIOps(different from AgentOps) is to create autonomous self-healing clouds, where AI-driven approaches can detect, localize, and mitigate faults with minimal human intervention.
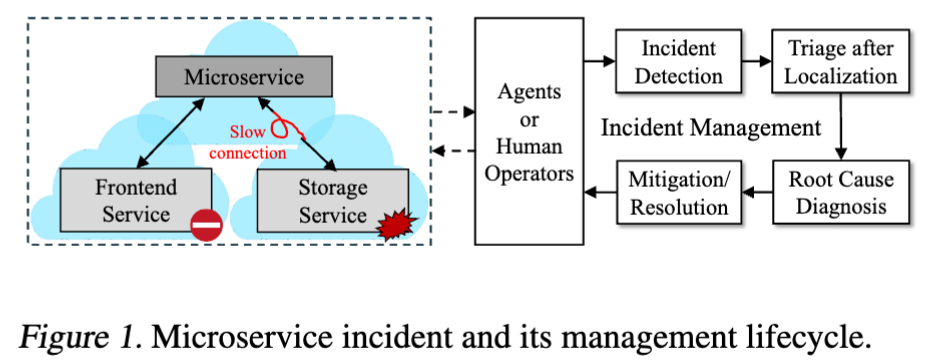
In AgentOps paradigm, agentic approaches are not limited to isolated operational tasks but are capable of seamlessly managing multiple, cross-layer tasks across the entire op-
Progress in AI for ‘Ops’, particularly AgentOps, remains limited, due to the lack of high-quality benchmarks for diverse, realistic scenarios
->
Addressing this gap requires a framework that aids the design, development, and evaluation of AIOps agents within an interactive environment (Key Contribution of the Paper)
Challenges
- manage an evaluation flow that is generally applicable to diverse agents and clouds, powerful enough to evaluate agents by complex and realistic operational tasks, and valuable enough to provide different feedback or observability, together with extensibility that make it possible to accommodate new tasks and agents by the user
- peration benchmarks: the lack of realistic evaluation scenarios, as existing approaches often rely on static datasets; Such setups do not capture the dynamic, unpredictable, and evolving nature of real-world cloud environments, where workloads and incidents fluctuate(波动) over time
- existing AIOps approaches and their benchmarks often focus only on isolated aspects of the incident lifecycle, such as anomaly detection or fault localization.
- This lacks a cohesive framework to evaluate AIOps agents comprehensively.
- It limits support for decision-making that could assist in chaining algorithms or selecting the most suitable agent for a given operation scenario
- existing AIOps approaches and their benchmarks often focus only on isolated aspects of the incident lifecycle, such as anomaly detection or fault localization.
problems
The designed set of evaluation scenarios are referred to as problems, which replicates realistic incidents within the microservice system
- problem pool is structured around a task-level taxonomy(分类法)
- go beyond simple performance or crash failures
- incorporate(包含) fine-grained root causes to fully assess the diagnostic and mitigation(减轻) abilities of AIOps agents.
ACI (Agent-Cloud Interface)
AIOPSLAB features the Agent-Cloud Interface (ACI), a unified interface that enables agents to interact with the cloud.
ACI allows agents to communicate, take action, and receive feedback, orchestrating these interactions to detect and resolve issues in dynamic and interactive environments.
Method
Problem Definition (Formalized)
Support a wide range of evaluation scenarios (problems), which replicate realistic incidents within the microservice system
Formalize an AIOps problem as a tuple
- represents a task
- represents a context
- represents the expected solution(oracle)
The context C can be further formalized as a tuple - is the operational environment in which the problem occurs
- the cloud service
- the fault model
- the workload model
- is the problem information usedto describe the problem to the agent
- service description
- task descriptions
- documentation about available APIs that is directly shared with the agent
- indirect information
- logs
- metrics
- traces observed in the operational environment
Orchestrator
Orchestrator strictly enforces the separation of concerns between the agent and the service, using a well-defined central piece, the Orchestrator.
It provides a robust set of interfaces that allow seamless(无缝的) integration and extension of various system components.
Agent Cloud Interface
Existing interfaces to the cloud are not well-designed for LLMs and agents
E.g. humans can reliably ignore irrelevant information, which can prove distracting for agents and hamper performance
ACI specifies:
- the set of valid actions available to the agent
- how the service’s state is conveyed back to the agent as the observation of its actions
Session Interface
manage the lifecycle of the agent and the service
a session-based system
a Session is created for each instance of an agent solving a problem
- starts with simple API calls passing a unique problem identifier
Our only requirement is that the agent must implement a get_action method with the following signature: async def get_action(state: str)-> str. It takes the service’s state as input from the Orchestrator and returns the next action the agent wants to take. (It could be a wrapper func)
Other Interface
Problem Initializers
Given context , the Orchestrator deploys services and uses infrastructure-as-code tools to deploy the required cloud service for each problem.
Include 2 generators:
- workload generator
- supports several workload policies and also replays industry workloads
- fault generator
- uses a custom fault library that instantiates faults across different levels of the system stack
- The library contains and extends to several fine-grained and parametric faults that go beyond surface-level symptoms and engage deeper into more complex resolution strategies
These 2 generators introduce controlled service disruptions that simulate live benchmark problems
Problem Evaluators
Evaluate the agent’s performance on a problem
It compares the agent’s solutions against predefined success criteria and evaluation metrics specific to each task.
AIOPSLAB provides an optional qualitative evaluation of agent trajectories using LLMs-as-Judges (Zheng et al., 2024)
Orchestrator maintains comprehensive logs of all agent trajectories, including actions taken and resulting system states, facilitating detailed analysis and debugging
Cloud Services
deploys live microservice applications as cloud environments
Task-Oriented Fault Library
Task Taxonomy
Categorizes the tasks that AIOps agents should accomplish according to the different stages of the incident management lifecycle, with progressively increasing complexity
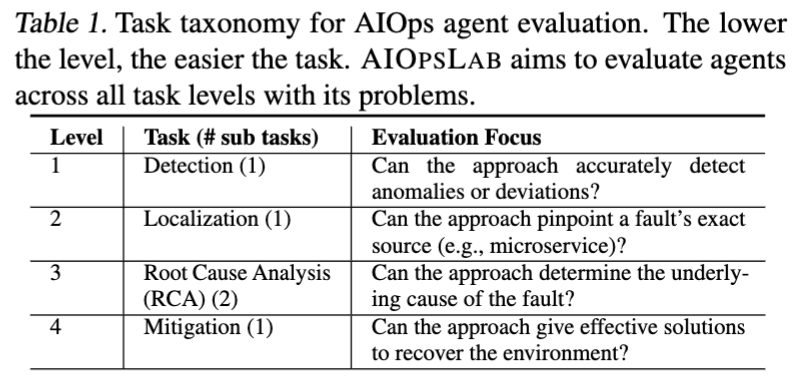
Level 1 focuses on the preliminary(初步的) identification of unusual behavior within the system
To instantiate problems across different task levels, we use fault injection to inject faults into the system, and construct a problem pool for AIOPSLAB
classify them into two main types
- Symptomatic Faults
- Functional Faults
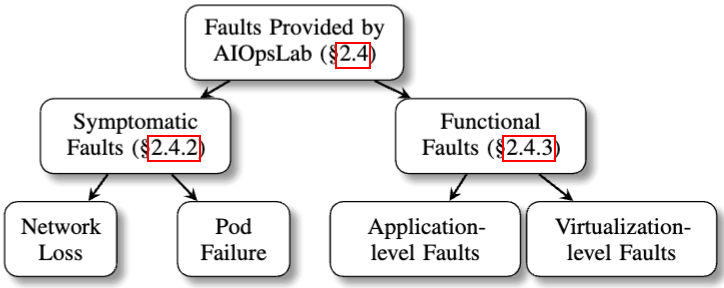
Symptomatic Faults
E.g.
- performance degradation
- crash failure
can be observed by increased latency, resource exhaustion or service outages
Theses faults are level 1 (detect) and level 2 (localize) tasks in taxonomy
Functional Faults
most of the fault injection tools focus solely on injecting system symptoms (too coarse-grained faults).
The failure scenarios to evaluate AIOps agents across tasks must go beyond simple performance or crash failures, and reflect realistic cases that challenge agents, where functional faults come into play.
- diagnose the root cause (Level 3)
- incorrect deployment or operations
- apply the correct mitigation strategies (Level 4)
Observability
collects a wide array of telemetry data by its telemetry collector
- races from Jaeger (Jaeger Authors, 2024) detailing the end-to-end paths of requests through distributed systems
- application logs retrieved by Kubectl, or formatted and recorded by Filebeat (Elasticsearch, 2024b) and Logstash (Elasticsearch, 2024a)
- system metrics monitored by Prometheus (Prometheus Authors, 2024)
Also export the data offline to facilitate evaluating other traditional AIOps approaches.
Capture information from other dimensions, e.g., codebase, configuration, and cluster information
Evaluation
Metrics
- Correctness accuracy of the agent’s response to problems, evaluates whether the agent successfully detects, localizes, analyzes and resolves the problems as expected.
- Time/Steps efficiency of the AIOps agent for each type of task
- TTD (Time-to-Detect): time elapsed from the occurrence of a fault to its detection
- TTM (Time-to-Mitigate): time taken from detection to complete mitigation of the fault
- The number of steps or actions taken to solve the problem is also recorded
- Cost the number of tokens, including both the input token and output tokens, generated by the agents/environment as an indicator of the cost.
Problem Pool of AIOpsLab Benchmark
- level 1 Detection of the presence of faults in real-time, which is a binary classification (yes -> fault is present). Can also be made complex by asking the agents to label the abnormal telemetry data
- level 2 Asks the agents to specify the exact location of the fault, usually a service or pod name in Kubernetes
- level 3 Identify (1) the system layer the fault affects and (2) the type of the fault, e.g., misconfiguration or operation error.
- level 4 Interact with the environment to fix the fault with a series of actions, such as updating the configuration, or rollback to a previous version, etc
Injecting-to-Others
Most faults enable users to extend and create new problems easily by injecting the fault into other targets, such as service.
Injecting faults into different targets is crucial because each service may have distinct dependencies, resulting in varied fault “blast radius” or failure propagation topologies.
Faults can manifest at different locations within the microservice architecture to help evaluate the ability of the AIOps agents since different locations may indicate distinct difficulties
Performance Results
Problem difficulty differs across task levels
none of the agents consistently achieve high problem-solving accuracy across four task categories in AIOPSLAB benchmark.
Influence of the Step Limit
examine the impact of the maximum number of allowed steps on the agent’s performance
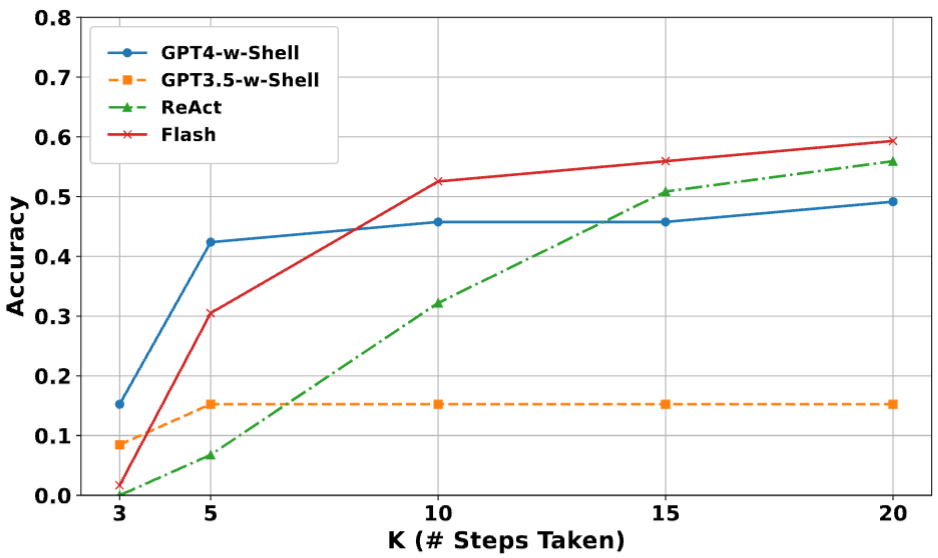
Notably, the plateauing of accuracy after a certain number of steps indicates that self-repair with environment feedback can saturate quickly for AIOps problems.
On the contrary, in development tasks (Dev), such as code generation, feedback via various compositional tools such as linters, type checkers, and test cases help agents continuously improve.
This suggests the need for
- better task decomposition for AIOps problems using planning
- improved feedback mechanisms for intermediate steps
- solutions that go beyond environment feedback and self-repair
Agent Behavior: The Good, the Bad and the Gaps
All agents perform better than the traditional non-LLM AIOps methods in terms of the problems for detection and localization tasks
Agents also diverge in their patterns of API usage.
Wasting steps on unnecessary actions
- repeatedly calling the same API
- generating non-existent APIs (especially in loops)
- spending excessive steps in multiagent communication
Overloaded information when consuming data
Analyze the correlation between the agents’ actions and the success or failure of problem-solving, as well as the distribution of actions across steps
Agents may subsequently consume the log/trace data with a cat command directly, which can overwhelm the model’s input context window and cause distraction and more tokens to be consumed
Consequently, using these telemetry APIs without careful consideration or analysis can add more noise into the agents’ reasoning, possibly leading to token exhaustion.
We expect more refined telemetry data processing and filtering mechanisms to be implemented in the agents to avoid this issue in the future.
Invalid API usage
GPT-3.5-W-SHELL consistently generates incorrect command formats
REACT agent occasionally generates incorrect API commands, but typically recovers by reasoning through the errors and self-correcting its commands.
False Positive Detection Issues
misinterpreting normal activities (e.g., standard workload generation) as faults.
Discussion
- helps engineers to easily create customized incident scenarios for evaluating agent with ACI as guard-rails(护栏)
- ensures that agents are tested within a controlled environment, allowing users to focus on designing scenarios that accurately represent incidents in their systems and defining the specific problems their agents should solve
- adaptable to other fault types
- users can create problems where agents are required to label the workload or telemetry data to identify anomalies.
- LLM-as-Judge: in the binary-choice detection task, agents may answer correctly but provide incorrect interpretations or reasoning. This can help address the issue by comparing the LLM reasoning chains with the problem description
Related Work
AgentOps: However, beyond the lack of
publicly available implementations and associated private datasets, there is a notable gap: the absence of a unified benchmark capable of providing realistic evaluation scenarios to assess agents’ performance across operational tasks.
AIOps: do not simulate the dynamic and complex cloud environments, not to mention allowing agents to interact with them to solve operational tasks.
Conclusion
- develop a framework, AIOPSLAB, which combines a fault injector, workload generator, cloud-agent orchestrator, and telemetry observer to simulate cloud incidents and provide an agent-cloud interface for orchestrating and evaluating AIOps agents.
- leverage AIOPSLAB to construct a benchmark suite with 48 problems and evaluate four agents to demonstrate the application of AIOPSLAB in evaluating LLM-based agents across different types of AIOps tasks