
0. Hadoop Distributed File System
Consistency 一致性
- CAP Consistency
- 所有节点对同一份数据, 在同一时刻具有相同的视图
- Transaction Consistency
- 事务开始前和结束后, 数据库必须处于一个合法的状态
- 数据复制中的一致性模型
- 如下表
| 一致性类型 | 定义 | 特点 |
|---|---|---|
| 强一致性(Strong Consistency) | 所有读操作总能读取到最新写入的数据 | 类似单机行为, 用户视角简单但性能代价高 |
| 线性一致性(Linearizability) | 操作结果看起来是按全局时间顺序排列 | 是强一致性的一种更严格形式 |
| 顺序一致性(Sequential Consistency) | 各节点操作顺序一致, 但不保证全局时序 | 稍弱, 允许不同读者看到写入顺序不同但一致的版本 |
| 因果一致性(Causal Consistency) | 如果一个操作因另一个而起, 它们必须按因果顺序执行 | 不相关的操作可乱序, 提高并发性 |
| 会话一致性(Session Consistency) | 一个客户端在一个会话内的所有操作是顺序一致的 | 用户体验更好, 适用于移动端等临时连接系统 |
| 最终一致性(Eventual Consistency) | 如果没有新更新, 所有副本最终会收敛到一致状态 | 高可用, 低延迟, 但短期内数据可能不一致(如 DNS, S3) |
Design Target
the HDFS is designed to store very large data sets reliably
to stream those data sets at high bandwidth to user applications.
In a large cluster, thousands of servers host directly attached storage and execute user application tasks.
Store Structure
HDFS stores file system metadata and application data separately.
- metadata stored on a dedicated server, called the NameNode
- application data stored on DataNodes
- unlike traditional ones, it does not use RAID for reliability
- it use replication (redundancy) at the granularity of block
All servers are fully connected and communicate with each other using TCP-based protocols
This ensures that the i/o bandwidth is multiplied, and there are more opportunities for locating computation near the needed data.
Architecture
NameNode
namespace 指的是在 unix (hdfs) 文件系统中所有的文件路径 (文件夹 + 文件)
name node 是 namespace 的唯一管理者, 它维护整个文件系统的结构和元数据
每一个 namenode 会将整个 namespace 都存储在 ram 中以便快速访问, 存储形式是类似于 unix inode 的数据结构
所有 ram 中的 inode 的集合称为 image 镜像, NameNode 会定期将内存中的 image 持久化为一个磁盘文件, 称为 checkpoint
对于一个 checkpoint 之后的修改会被存储在一个 log 文件中, 称为一个 journal, 用于还原相对于 checkpoint 的更新效果
checkpoint 会被同步复制到多个 block 中
当 name node 重启的时候会读取 checkpoint 并且结合 journal 来还原最新的状态
Files and directories are represented on the NameNode by inodes, which record attributes like:
- permissions
- modification
- access times
- namespace
- disk space quotas
The file content is split into large blocks (typically 128 MB) and each block of the file is independently replicated at multiple DataNodes (replicate index = 3).
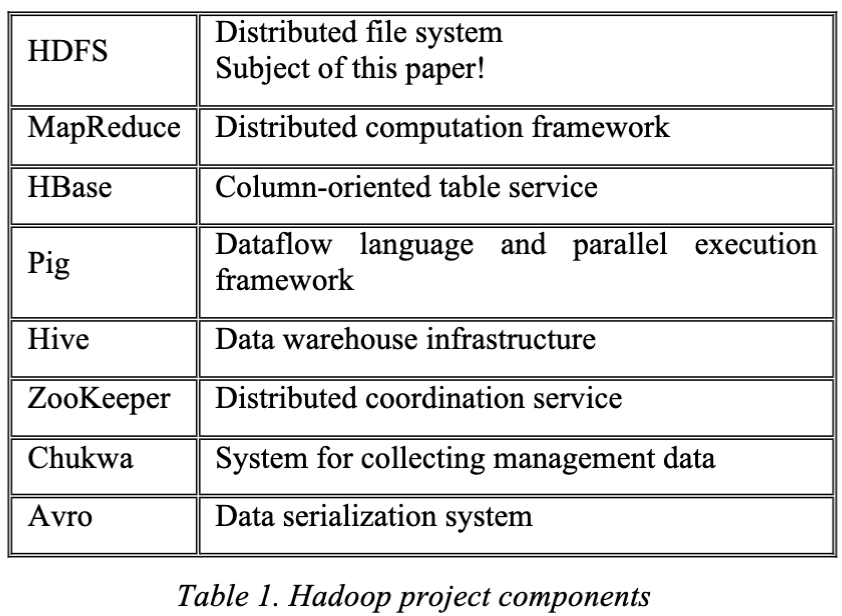
The NameNode maintains the namespace tree and the mapping of file blocks to DataNodes (the physical location of the file data).
An HDFS client wanting to read a file first contacts the NameNode for the locations of data blocks comprising the file and then reads block contents from the DataNode closest (among all replicas) to the client
Write: The client requests the NameNode to nominate(提名) a suite of three DataNodes to host the block replicas. The client then writes data to the DataNodes in a pipeline fashion. The current design has a single NameNode for each cluster.
DataNodes
在 datanode 中数据的存储形式是两份文件, 即一个源数据文件, 以及一个用来恢复原文件 (或者用来检查文件完整性) 的 metadata (包括 checksum 等数据)
启动阶段, datanode 会向对应的 namenode 发起一个 handshake 来确定 namespace ID 以及 软件版本, 其中这个 namespace ID 是在 format namenode 的时候进行的, Namespace ID 是 HDFS 文件系统命名空间的唯一标识符, 用于标记整个集群的数据空间, 并确保所有参与者(NameNode 和 DataNode)属于同一个逻辑文件系统;
一个最新创建, 还没有 namespace ID 的 data node 会被赋予一个 namespace ID 并且允许进入其他的 namenode 范围 (即通过 handshake 来进行 registration);
NameNode 自己也有一个 namespace ID
| 名称 | 是否唯一 | 谁生成 | 存在哪些节点 | 关键作用 |
|---|---|---|---|---|
| Namespace ID | [x] | NameNode format | NameNode + DataNode | 确保节点属于同一命名空间 |
| Storage ID | [x] | DataNode 启动时生成 | DataNode | 区分不同 DataNode |
| Cluster ID | [x] | NameNode format | 所有节点共享 | Federation/HA 使用场景下的全局 ID |
block report
DataNode 通过发送 Block Report(块报告)向 NameNode 告知自己所持有的 block 副本
block report 的内容包括每个 block 唯一的标识符 block id 和一个 generation stamp 标识这个 copy 的版本号(用来判断哪个 copy 是版本最新的)以及一个 length 来判断一个 block 的大小是否完整
name node 原本并不知道哪些 datanote 存储了哪些数据 block, 但是可以通过这个 report 来获取, 并且可以通过 data node 的主动上报来获得
第一个 block report 在新的 block 初始化的时候就会发送, 后续的报告每一个小时发送一次
Heartbeats
datanode 每 3s 会给 namenode 发送一次 heartbeat 来确保自己还在线并且 available, 如果连续 10min 还没有收到来自某一个 datanode 的 heartbeat 则会被标记为 unavailable
同样的, heartbeat 还可以同步磁盘空间的使用情况
namenode 也通过 heartbeat 的反馈来来对 datanode 进行控制
HDFS Clients
用户可以通过 HDFS client 来访问这个 hdfs 数据库,
hdfs 还会通过 api 暴露文件 block 的位置, 从而允许 mapreduce 来访问这个数据块, 这主要是通过 mapreduce 来并发运算找到文件在超大 file system 中的位置从而提升 read performance
Image and Journal
由于 image (checkpoint) 和 journal 能确保数据的强同步以及可依赖性, 如果丢失了这些文件就会导致 namespace 部分或者完全损坏, 因此这是 hdfs 最核心的数据信息, 通过 replication 来尽量确保安全, 一般会确保在同一个 node 的不同 volume 中都存放这个数据, 并且再结合 nfs 在远程备份一个
由于 namenode 本身必然是一个 multithread 的系统, 因此将 transaction 写入 disk 已经逐渐变成了一个 bottle neck 的问题, 而 hdfs 为了提升性能, 将不同用户的信息存储在一个 batch 中来进行统一访问, 即当一个 thread 发起同步 (sync) 请求的时候, hdfs 会将所有需要写入的事务一同写入到 disk 中, 从而减少 磁盘写操作的频率, 这样其他线程只需要关注自己的事务是否已经被保存, 不需要再重复发起 flush-and-sync 操作
CheckpointNode
namenode 除了其基本功能, 也会存在两个额外的功能: CheckpointNode 或者 BackupNode, 每个 node 在其 startup 阶段就确定了其基本的功能
CheckpointNode 会周期性地结合已有的 checkpoint 和 journal 来生成一个新的 checkpoint 和一个空的 journal; 一般会跑在 namenode 之外的机器上, 因为二者理论上的内存大小一致, 且这个节点会从 namenode 中下载 checkpoint + journal 然后本地合并最后再返回到 namenode 完成同步;
BackupNode
bn 会接受来自 namespace transaction 的事务流 (journal stream) 即命名空间事务如文件的移动或者重命名等, 并且也会同步在本地跑一遍相同的 transaction, namenode 将这个 node 视为 最新的命名空间状态记录; BackupNode 建立 checkpoint 的过程并不需要从 namenode 中下载下来, 而是可以直接本地自己重建, 这样会更加高效
可以将 bn 视作一个只读的 nn, 它包含了除 block location 之外的所有 metadata, 使用 bn 可以让 nn 不需要强制持久化存储
FileSystem Snapshots and Updates
在软件升级期间, 由于软件错误或人为错误而损坏系统的可能性会增加;在 HDFS 中创建快照的目的是最大限度地减少升级期间对系统中存储的数据的潜在损害; 快照机制允许管理员持久保存文件系统的当前状态, 以便在升级导致数据丢失或损坏时, 可以回滚升级并将 HDFS 返回到快照时的命名空间和存储状态
datanode 的 snapshot 创建由 namenode 进行统一指挥, dn 不会通过复制整个文件夹来创建 snapshot, 而是选择使用创建 link copy
IO
文件读写
hdfs 通过 single writer - multiple reader 的形式进行文件读写
每当一个 client 想要写入一个文件的时候会 生成一个 lease, 当存在并拥有这个 lease 的时候其他用户不能写入这个文件, 且写入者会周期性地 renew lease (通过不断地向 namenode 发送 heartbeat 信息来实现更新); 当文件被关闭之后, lease 也就被 revoke (撤销)
lease 的 duration 存在一个 soft 和 hard 的 limit:
- soft limit 到期时, writer 必然还拥有着唯一文件 access 权限
- 到期之后, writer 如果出现关闭失败或者 renew lease 失败, 其他 client 就被允许抢占这个文件权限
- hard limit 到期之后, hdfs 就会假设 client 已经退出, 并且会强制自动关闭文件并且恢复 lease (所有权清空)
在写入一个文件的时候, hdfs 并不确保其他用户能直接读取到这个修改的内容, 直到该文件被对应用户 close (使用 hflush 指令可以强制高同步性)
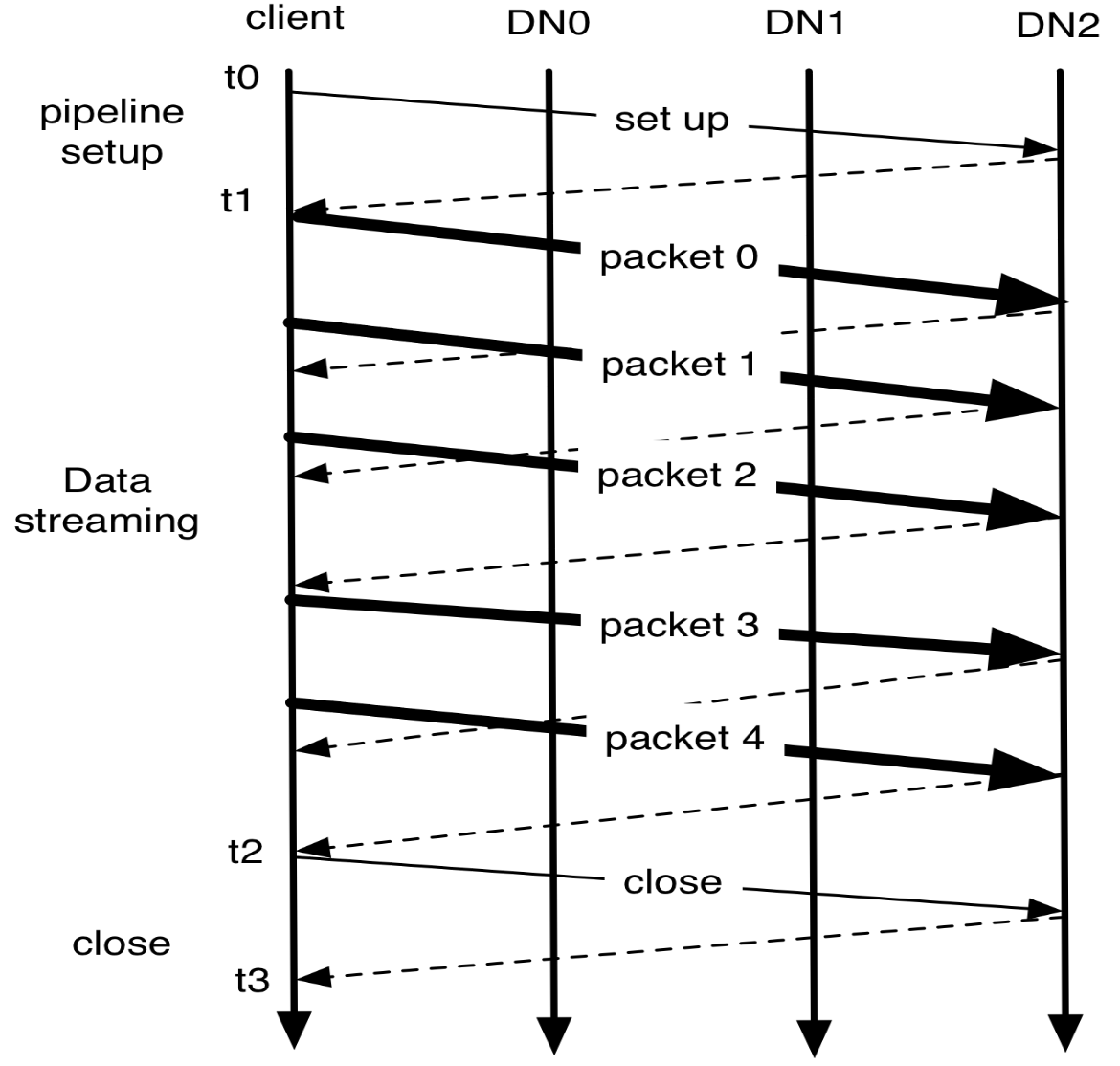
管道流写入 pipelined stream write
在创建一个 block 并且写入的过程中, 多个 datanode replica 之间会形成一个 pipeline, 这个连接顺序是最小的连接长度, 并且从 client 端开始, 每当一个 buffer 被填满 (大约 64KB, 称为一个 packet) 之后就会发送到最近的一个 node, 并且下一个 packet 发送并不需要等待第一个 ack 回来, 而是可以直接发送, 但是传输中的 pack 总数是存在上限的 (即所谓的 window size)
注意这里的 pack 大小远远小于一个 block 的大小 (128 MB), 因此 block 的写入并不是 atomic 的, 所以需要动态调整一个 block 的 offset 范围
完整性 integration
hdfs 通过 client 端和中央端维护各自 checksum 来确保数据完整性的实现
- create file: client 计算checksum 传递给 hdfs center, 由中央计算对比
- read file: client 计算 checksum 并且和 hdfs center 发送过来的对比
如果发现数据不完整, 则向 namenode 发送一个请求来告知数据不完整, 再 fetch 另一个 replica 来继续操作
读取流程
- client 向 nn 获取对应文件的 block 列表, 以及每个 block 的所有 replica 的位置
- 每个 block replica 的排列按照到 reader 距离从小到大顺序
- 如果读取第一个 replica 失败, 就按照顺序去读取下一个 node
注意读取的时候从 namenode 读取到的 offset 并不一定是最新的写入值, 所以最靠谱的方案是向最近的一个 datanode replica 中来读取
Block Placement
这一段讲的是如何结合实际的 物理 node (主机硬盘和交换机网线) 来最优化 数据的放置位置, 重点考虑 网络拓扑结构
暂时不考虑 nsdi 方向, 以后有空再看 ~
Replication Management
回忆上文提到过的 block report, namenode 会在每一次的 report 中来判断每个 datanote 是否发生了 over/under-replicated
- over-replicated: 挑选一个 node 来进行删除
- 第一条件是不能减少存储对应 dn 的 rack 的数量
- 次级条件是从剩余空间最小的 disk 中删除对应的 node
- 总的目标是 balance storage utilization across DataNodes without reducing the block’s availability
- under-replicated: 创建一个 replication priority queue, 如果只有一个 replica 则拥有最高的 priority
- 如果 replica=1 则把 replica 放到不同的 rack 上面去
- 如果 replica=2
- 如果二者在同一个 rack 上, 则将第三个放在新的 rack 上
- 如果二者在不同的 rack 上, 则将第三个放在同一 rack 的不同 node 中
- 这里的目标是 reduce the cost of creating new replicas
namenode 还要确保不是所有的 replica 都在同一个 rack 上, 所以 nn 会将 三rep共rack 的现象视作 under-replicated 的情况, 因此会申请一个新的处于不同 rack 上面的 node, 这里就会导致 over-replicated -> 最终会删除处于同一个 rack 上的 node
Balancer
hdfs 的 block 放置策略并不会考虑 datanode 的 disk 空间利用, 这个目的是避免将新的 (新的更有可能会被 ref) 数据放在某几个小的 datanode subset 中; 换言之这里放置 block 的目的是让数据能均匀地放在所有 datanodes 上 (imbalance 仍然会在新的 node 被加入 cluster 的时候发生)
引入一个 balancer 来作为 disk 使用空间的平衡工具, 而平衡的定义是已有的各个 datanode 的 utilization (used space / capacity of the node, range 0 - 1), 而所谓的平衡状态就是各个 datanode 的 ratio 都小于一个固定的 threshold 值
balancer 的工作任务就是不断地将 block 从 replica 大的地方移动到 replica 小的地方, 同时确保 data availability (也就是确保每次数据移动不会减少 replica 数量或者 rack 分布数量), 同时为了数据移动的高效, 要尽量减少 inter-rack 数据复制, 同时也会有一个 copy 过程的 bandwidth 占用上限约束这一流程
Block Scanner
每个 datanode 都会运行一个 bs 来周期性地检查 replica 和 验证 checksum 是否符合对应数据
每次 client 读取一个文件经过 verify 之后会通知对应 datanode, dn 就会将这个认为是一个 replica verification
每个 block 的 veri 的时间会被存入一个人类可读的 log 文件, 在任意时间都会有最多两个文件存在顶层的 datanode 文件夹 (prev/curr-log) 每次验证之后时间戳都会 append 在后面
每次一个 read client/ block scanner 发现了损坏的文件就会通知 namenode, 由 nn 来标记这个 replica 是损坏的, 但是不需立刻删除这个文件, 而是先申请一个新的 block 来存放这个文件, 直到确保有效 replica 数量达到了对应的 replication factor 之后才会删除破损文件 (确保数据可用性为主); 也就是说及时所有的 replica 都损坏了, 这一机制仍然允许用户从这些损坏的 replica 中获得数据文件
Decommissioning 退休机制
cluster administrator 确保了哪些 node 可以加入 cluster (列出了一个 host address 表单) 以及哪些不可以加入 cluster
administrator 也可以让系统重新 evaluate 这个列表
decommissioning 的意思是对一个本来处于列表中的用户 (单位往往是一个 datanode) 被 excluded 这一过程; 一旦这个 datanode 被标记为 decommissioning 就不会被选择作为 replica placement 的 地方位置, 但是可以持续被 read; namenode 会开始 schedule 申请新的 replica block 来解决这个, 直到某个 datanode 的所有的 decommissioning 都被 replicated 就会被标记为 decommissioned state, 然后可以被 safely removed