
6. File System
文件系统抽象 File System Abstraction
| attribute | Hardware Reality | OS abstraction |
|---|---|---|
| interface | heterogeneous | uniform |
| storage objects | a few (disks) | many (files) |
| name structure | simple numeric name (id) | rich name (symbolic, hierarchical, unified) |
| access speed | slow | fast |
| crash resilience | unreliable | reliable |
硬件层到 os 的转变方式
- Heterogeneity
- 原因: many i/o devices, each with its own idiosyncrasy
- Solution: abstraction
- build a common interface (Application 层和 File System 层之间设置统一接口 POSIX)
- write device driver for each device
- Linux src code 70% is drivers
- Disk interface
- 硬件接口表现为 linear array of sectors (扇区)
- 扇区为最小的物理存储单位, 每个扇区为512字节 (typically)
- write atomically, 要么全部写入要么全部没有写入
- 4KB in advanced format disk
- disk 会将逻辑 sector 映射到物理 sector
- 逻辑 sector: 由 OS 决定
- 物理 sector: 由 disk 决定
- os 不知道 mapping
- 硬件接口表现为 linear array of sectors (扇区)
机械硬盘结构 Disk Geometry/Structure
- Platter: 磁盘盘片
- Data is stored by inducing magnetic changes to it
- Each platter has 2 sides, each called a surface
- Spindle: 磁盘主轴
- 围绕 spindle 旋转
- Spindle rotates the platters at a constant speed (unit RPM)
- Track: 磁道
- A circular path on a platter (Concentric circles of sectors)
- All tracks at the same distance from the spindle form a cylinder
- 每个 surface 包含上千个 track
- Cylinder: 柱面
- A stack of tracks of fixed radius
- Heads record and sense data along cylinders
(不同层的head指向同一个 xy 坐标位置) - Generally only one head active at a time
- 分区的最小单位
ext2文件系统分区结构体:
1 | struct partition{ |
- 磁盘分区是告诉操作系统"我这块磁盘在此分区可以访问的区域是A柱面到B柱面之间的块",
这样操作系统就知道它可以在所指定的块内进行文件数据的读, 写, 查找等操作;磁盘分区即指定分区的起始与结束柱面
机械硬盘访问 disk 的方式
- 流程: Seek, Rotate, Transfer
- Seek: 移动磁头到指定 track
- 花费时间: 1-10ms
- 是一个物理运动过程, 很难减少时间
- Rotate: 等待 disk 旋转到读写头的位置上
- 花费时间: 取决于 rpm 转速, 一般 用来表示平均等待时间
- Transfer: 读写数据
- 最终的 io 操作
- 非常快, 依赖于 rpm 和 sector density
- 能达到 100 MB/s 的最大传输速度
优化 i/o 性能
- General Strategy
- Avoid doing I/O (disk is slow)
- 方法: 使用 write-back cache
- Reduce overhead (particularly seek time)
- 放置数据的位置很重要
- disk 角度要用更好的 scheduler 来改变内存访问顺序
- Amortize overhead over larger requests
- Avoid doing I/O (disk is slow)
- Disk Scheduling
- FIFO: 容易出现左右不断摇摆的情况, 读写头路程过大
- SSTF (Shortest seek time first):
- 选取距离目前读写头最近的 track 访问
- 优点: 减少 seek time
- 缺点: 会导致 starvation
- SCAN: 电梯调度算法
- Sweep across disk, servicing all requests passed
- Like SSTF, but next seek must be in same direction
- Switch directions only if no further requests
- 优点: 避免 starvation
- 缺点: 会导致某些 track 无法访问
- CSCAN: only sweep in one direction
- Amortizing Overhead:
- Efficiency = transfer time / (overhead + transfer time)
- 为了达到 50% efficiency,
固态硬盘的结构 Solid State Disk (SSD, flash memory)
- Increasing popular storage medium
- remembering data by storing charge
- Low power consumption
- No mechanical seek time (better random read performance)
- Better shock resistance (抗冲击性)
- limited times of overwrite possible
- limited durability
文件存储基础设计
- 元数据(Metadata)
- 存储文件内容位置, 大小, 权限, 时间戳等信息;
- 文件头(File Header / Inode)
- Unix中称为inode, 用于映射 file offset 到 disk block, 存储在磁盘中;
- 文件尺寸分布特性
- 大多数的文件尺寸非常小
- 占据电脑主要硬盘内存的是大尺寸文件
- 很多 io 的设计优化是针对大型文件的, 要很好的支持 random access (支持任意 offset 可以以接近 O(1) 的时间复杂度直接访问)
和 sequencial access (类似 for (auto it: structure) 的顺序遍历)
- Free list(空闲链表)是一种数据结构, 用来记录那些目前未被使用, 可供分配的资源块
文件分配方法
连续分配(Contiguous Allocation)
- 实现: 文件预分配连续磁盘空间(如IBM OS/360);
- 优点:
- 顺序访问快(Sequential Access);
- 随机访问易计算(Random Access);
- 缺点:
- External Fragmentation: 在两个已有的 block 之间的内存难以利用
- 文件动态扩展困难(前一个文件的末尾可能会被顶住);
- 因此可以联想到使用 linked-list 结构进行分散的访问
链表分配(Linked Allocation)
- 实现: 磁盘块通过链表连接(如DOS FAT);
- 优化:
- 文件分配表(File Allocation Table, FAT)缓存到内存, 减少磁盘访问;
- 优点:
- 支持动态扩展, 无外部碎片;
- sequencial 访问速度很快
- 缺点:
- random access 慢(需遍历链表);
- 对于 disk 访问尤其缓慢: 需要每个 node 都访问一次 disk 减慢了速度
- 由于 链表 的主要优势是依靠指针到每一文件块, 但是缺点是每个指针都存储在当前
file block 中, 降低的后面block的访问速度, 因此可以考虑将所有文件指针集中在同一个内存地址中 (FAT)
FAT (file allocation table) by DOS FS
- 实现: 将 链表指针放入一个固定尺寸的 FAT 中
- FAT index: 是上一个文件块的 file block offset
- FAT entry: 是下一个文件块的 file block offset, 最后一个 block 的 entry 是 EOF
- 特点: 仍然需要 ptr chasing, 但是整个过程是在 FAT 本地进行的, 确保在内存的同一个位置 (locality), 对 cache 支持更好
- 缺点 (相较于理想状态): 仍然不是很支持 random access
- 应用: 更多出现在兼容性要求较高的场景中, 例如 u盘 (FAT32)
- 由于 FAT 的尺寸有限且固定, 因此统一调度可能会导致尺寸过大, 扫描一个文件的 entry 可能也是一个比较大的时间开销,
且被所有进程公用, 可能会导致数据竞争的问题, 为了解决这个局部问题, 要更加考虑将数据本地化, 让每个文件各自管理其所有 block offset (Index Allocation)
索引分配(Indexed Allocation)
- 特点: 局部集中文件块的指针, 类似于一个 page table, 因此也会具有 pt 自身的局限性: 最大文件尺寸是固定的
- 在文件创建的时候自动创建这个数据结构
- 优点:
- 支持随机访问和动态扩展;
- 相比于 fat 的做法会更快, 因为不需要用到 ptr chasing 问题
- 支持随机访问和动态扩展;
- 缺点:
- 如果 局部 fat 的大小对所有文件是固定的, 那么, 对于小文件, 其 table 太大浪费了内存, 对于大文件可能 entry 不够用, 且局部
fat 是连续内存, 文件过大会导致对连续内存的要求上升- 类似 pt 的解决方案: level of indirect
- 解决目的: Allow large files, but small files don’t waste much header space
- 大文件需连续索引空间, 导致内部碎片;
- 如果 局部 fat 的大小对所有文件是固定的, 那么, 对于小文件, 其 table 太大浪费了内存, 对于大文件可能 entry 不够用, 且局部
- 从上面的 level of indirect 来看, 应该采用 hierarchical 结构来链接一个文件, 也就是 多级索引文件 (Unix Inode)
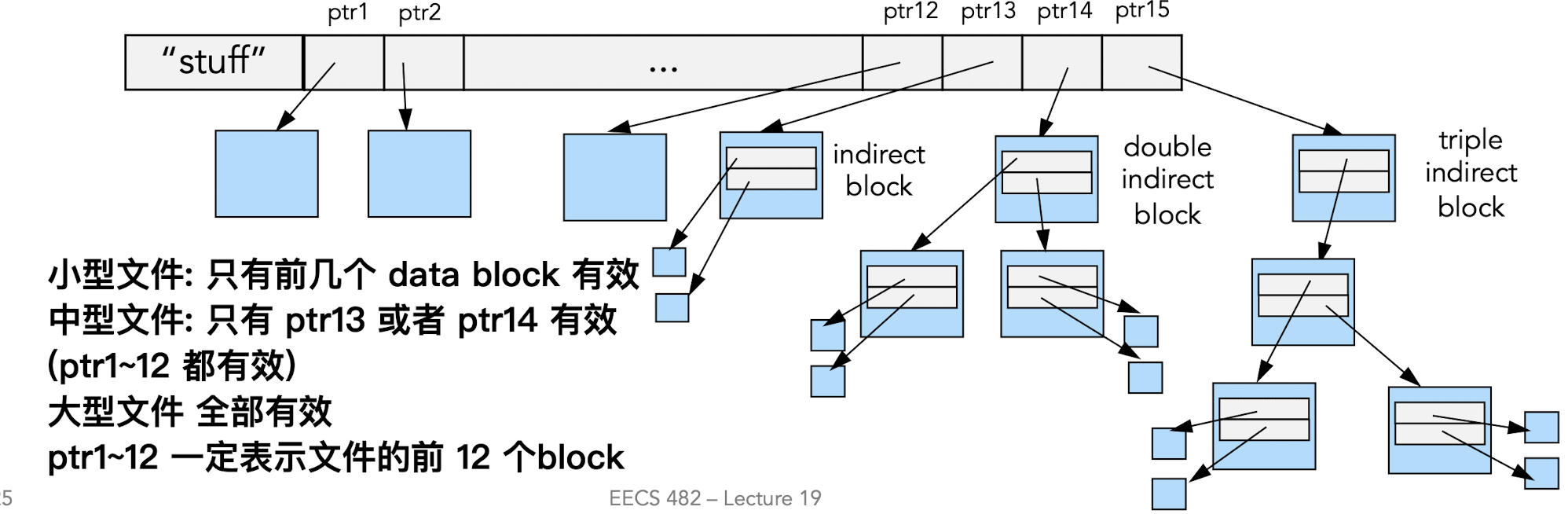
多级索引文件 (Unix Inode设计)
- Inode: 是 unix 系统 (ext32) 用来定位不同文件块的特殊数据结构, 存储在 disk 的一端, 即所有文件/目录的 inode 都存储在这一个 fixed-size array (known location) 硬盘地址中
- index of inode in the array is i-number
ls -i <file>可以直接输出文件的 i-number- 打开文件的时候, inode 会被读入到 memory 中
- 随着文件关闭/超时 自动将 inode 写回 disk
- 文件的 metadata 存储在下图中 “stuff” 数据块中 (即metadata 存储在 inode 中)
- 分析: 如果完全按照 pt 的设计, 这里很有可能会出现小文件并不需要层级结构, 访问速度偏慢, 因此使用 多层-单层并存的结构
- 也叫 Non-Uniform Depth
- 间接块并不存储在 inode 中, 而是存储在文件对应的专门磁盘块中, inode 只存储指向这个 block 的地址
- 结构:
- 12个直接块(Direct Blocks)指向数据块;
- 单/双/三重间接块(Indirect Blocks)支持大文件;
- ptr1~12 一定指向文件的最前面 12 个 block
- 小型文件只有前几个 ptr 有效
- 中型文件可能有单层/双层 indirect block 有效
- 大型文件则全部 ptr 都有效
- 优势:
- 小文件性能优(直接块快速访问);
- 支持超大文件(通过间接块);
目录与路径解析
- 背景问题/目的: referencing files
- user: 需要一个 结构性的方式来管理文件
- FS: 需要一个命名接口, 允许在硬盘中的物理文件存储能够被逻辑文件结构读取使用
- 作为一个 data structure 来存储 一系列文件的 file headers
- 目录(Directory)
- Unix中目录数据块包含
<文件名, inode号>条目; - 可能采用多种数据结构, 如 list, hash table, B-tree
- 目录的存储方式
- 大多数情况和一般的文件存储方式相同, indexed files, inode
- sometimes different
- users can r/w arbitrary data to a file
- users cannot r/w arbitrarily to a directory, because of FS security, and
metadata consistency
- Inodes directory: Inode 描述的是 disk 中对应 文件的 block 在硬盘的什么地址, 而 directory
- Inode of a directory 描述的是对应的 dir 的 data block 在 disk 的存储地址
- 这个 data block 存储的是 directory 里面的文件 inode 编号
<name, inode #> - 相比之下, unix inodes 并不存储文件名
本身是一种特殊的 file, 所以说 dir 按照 inode 的形式进行存储
- 这个 data block 存储的是 directory 里面的文件 inode 编号
- Inode of a directory 描述的是对应的 dir 的 data block 在 disk 的存储地址
- Unix中目录数据块包含
- 路径解析示例 Hierarchical file path translation:
- 从
/的根目录开始进行查找, 这个地址在 unix 中是处于inode #2(disk 中), 是一种 convention- 常用路径往往存在于 电脑缓存中, 因此实际上的查找是在 cache 里面实现的
- 解析
/home/notes.txt需依次访问- 从 disk 读取 inode #2 到 mem
- 基于 block ptr 来获取
/在 disk 中 data block 对应的地址,
解析这个地址得到/下的所有文件名 - 这个 data block 存有
<home, #home_i>的 pair, 读取 i-number == #home_i
的 inode 块并且获取其 首个ptr地址 - 基于这个地址获取 data block, 其 entry 表示 dir
/home/下的所有文件 - 在该 data block 中找到
<notes.txt, #notes_i>的条目并且回到 inode 找到
i-number == #notes_i 的条目
- 从
多存储设备下的统一文件系统
- 将多个设备接入同一个系统, 其中每个设备的根目录的名称都是
/- 一个 directory entry 可以指向其他设备的 root 路径
- 例:
/bin/tmp/afs是网络 server 的路径
缓存与性能优化
文件缓存(File Buffer Cache)
- 目的: 将文件 block 存储在 mem 中, 从而更好的利用 locality, 被系统的所有 process 共享
- 写回策略对比
- write-through: slow, but safe for data storage
- write-back: loses data on OS crash, power failure
- 当代 FS 使用 delayed write-back
- 背景守护进程 daemon 会周期性地将 dirty page 写回 disk (30sec)
- 如果在 30s 内对应 block 经过多次变化, 那么只需要进行一次 io
- 如果一个 block 被删除了超过 30s 就不会再需要 io 了
- 如果 crash 则丢失 30s 内写入的数据
- Unreliable, but practical
- system calls (Unix: fsync) enable apps to force data to disk
- 背景守护进程 daemon 会周期性地将 dirty page 写回 disk (30sec)
- virtual mem V.S. file caching
- 都使用 phymem 来作为 dick 的 cache 结构
- vm: 使用 disk 来增大容量 (swap 分区)
- fs: 使用 mem 来加快 performance
- 都会竞争使用 phymem
- 二者管理的元数据结构不同, 为了防止互相干扰, 因此应该对这些数据做一个隔离
- 都使用 phymem 来作为 dick 的 cache 结构
内存映射文件(Memory-Mapped Files)
- 实现: 通过
mmap()将文件映射到虚拟地址空间; - 优点: 减少数据拷贝, unifies 内存与文件访问接口;
- 缺点:
- 进程对数据移动控制弱, 写回的时机由 os 的 pager
和调度机制来决策, 无法主动调用read()/write()来明确控制 io 时机和大小 - 不适用于 streamed I/O(如 pipe, sockets),
因为内存映射是需要一个可以随机访问的后端存储的结构 (比如磁盘文件), 但是
streamed IO 并不支持随机访问(且不能像文件一样已知长度), 不能直接使用 内存映射方式, 当然内存映射的目的是加快随机读取和修改数据存储, 与连续处理输入流的 streamed io 目的从本质上不同
- 进程对数据移动控制弱, 写回的时机由 os 的 pager
预读(Read Ahead)
- 机制: 预测顺序访问需求, 提前加载后续数据块;
- 优势: 重叠I/O与计算, 提升吞吐量;
- 当前一个进程在运行的时候 os 会提前读取后续需要的 block
- 当当前进程结束之后, 后面需要的 block 就会在 cache 里面了
- 对于 sequential 访问是一个极大的 win (VV 笑)
Consistency on Crash
Atomic write one sector
- 从 disk 视角要确保对数据的写入在逻辑上是 atomic 的: 即对于同一组数据的写入, 在
crash (power failure) 发生的时候, 正在处理的数据写入要么全部写进去要么全没有写进去 - 物理过程上讲肯定存在部分写入的情况 (partially updated)
- Goal: atomically update file system from one consistent state to another
写入元数据
- Inode Bitmap (B): Endinode array 中哪些是有定义的
- Inode Array (I): 例如创建一个数据
- Data Blocks (D): 实际存储数据的地方
Crash on Update 对不同存储顺序的讨论
以下几种情况讨论不同 B/I/D 存储顺序能否解决 crash on update 的问题
- B-crash-ID 某个 inode 实际没有被写入但是在 bitmap
中显示是被占用了的, 从而导致地址悬空, 内存泄露 - I-crash-BD 同一个 inode 可能会被 overwrite
- BI-crash-D 系统认为对应的 data 已经被修改, 但是实际上访问的时候并没修改
- D-crash-BI
- 写入内容可能会被覆盖
- 在执行 ls 指令的时候, 会访问到对应的更新过的 data
块并且显示修改的内容, 但是执行对应指令的时候可能无法访问新修改添加的文件
Transaction (Logging)
- 将数据的存储分为两个目标:
- Data Store: Persistent copy of data
- Log (Journal): Append-only record of changes
- Write Ahead Logging (Journaling)
- 将 存储的 intent (意愿) 率先写入到 log 中
- 写入之后才开始 log
- 如果出现 crash, 首先检查 log, 然后根据最后一个 log 的情况来执行 recovery
- crash before the “intent” is fully written -> no op
- crash after the intent is fully written -> redo op
- 确保 atomicity: 一个任务要么全部执行了, 要么完全没执行
- Logging Steps
- Write updates (dirty blocks) to journal
- 包括
Tx Begin, B/I/D 三块的更新数据
- 包括
- Write commit record
- 即在 log 段的最后写一个
end logging之类的记录 Tx End会有一个 id 标识, 其必须与Tx Begin的标识符一致
- 即在 log 段的最后写一个
- Copy dirty blocks to real file system
- 要确保已经完全写完了
- Reclaim the journal space for the transaction
- 将前面写好的数据在执行确保完成之后清空
- Write updates (dirty blocks) to journal
状态分析
- log 中有 Tx Begin 但是没有 Tx End
- 在写入 log 的时候发生了崩溃, 说明正式的数据写入还没有开始, 因此忽略这个写入 (do nothing)
- log 中有 Tx Begin/End, 但是 D 的数据还没有写入
- 这个会发生在步骤 2 没有用 cv 等锁来强制等待 step 1 结束之后再开始执行,
因为系统的调度并不一定按照 FIFO 的策略来执行, 因此需要 强制等待 - 这也解释了为什么 不能 merge step2 with step1
- 这个会发生在步骤 2 没有用 cv 等锁来强制等待 step 1 结束之后再开始执行,
- log 中有 Tx Begin/End, 且 B/I/D 经过检查了但是整个记录没有被清空
- crash 发生在 step 3 和 4 之间
- 数据安全且 persistent/consistent, 效率略微降低
日志文件系统 Journaling File System
- Cost: 1 journal = 2 disk writes, 2 seeks
- 需要找一种方法来 balance consistency and performance
- Data journaling
- 记录所有的 write (data + inode)
- expensive to journal data
- Metadata journaling
- journal only metadata
- high performance
- used by most systems (ibm jfs, sgi xfs, ntfs)
- problem: file may contain garbage data
- 新旧内容混杂, 数据块会直接丢失
- 新增的 inode 数据浪费空间
- Ordered Mode
- write file data to FS first, then journal metadata
- defualt mode for ext3
- problem: old file may contain new data
- 为什么要先写 data 再写 meta?
- 数据一致性, 安全性: 先写 data
只会导致原来的数据被覆盖, 但是不会导致不一致的情况, 而先写 meta
会导致生成一个没有写入的地址, 导致数据不一致, 指针非法
- 数据一致性, 安全性: 先写 data
- 为什么要先写 data 再写 meta?
FSCK 策略 (file system checker)
- 当电脑开机的时候, 遍历 fs 来检查数据是否一致
- 尝试自我修复
- B’ID: 根据 I 来把 B’ 进行撤销回 B
- BI’D: 根据 B 来把 I’ 恢复回 I
- performance problem: take hours
- not well-defined concsistency
- 如果无法修复将任务转给用户来进行处理
- 比如 B’ID’ 的情况无法处理
服务器并发系统下的多线程处理
detach() 方法
- 参考下列循环+线程构造的结构
1 | while (condition){ |
- 线程对象 t 析构时, 如果仍为
joinable()(即未调用join()或detach()), 根据 Boost.Thread 和 C++ 标准库的规范, 这会触发未定义行为(通常是程序直接终止, 类似std::terminate()); - 线程对象 t 析构时, 线程已分离(t.joinable() 为 false), 因此析构是安全的, 不会触发未定义行为;线程执行流继续独立运行, 直到其任务函数自然结束(即使线程对象 t 已销毁);系统会在后台自动回收线程资源(如栈内存), 但线程任务逻辑会完整执行;
hand-over-hand mutex 目的
- 在多线程访问同一个链表的背景下, 如果要实现对
push(),pop()进行安全的访问和调用, 且考虑到高效率的访问链表- 如果对整个链表进行上锁: 安全, 但是整个链表太长, 后续需要访问链表的线程需要等待前一个线程完全读取结束之后才能访问, 效率低, 导致 starvation
- 目的: 让多个需要访问同一个链表的线程遵循排队原则: 根据 FIFO 原则逐个访问同一个 node, 但是不会出现访问过程的插队或者错序, 内部访问顺序和最初进入链表的顺序一致
- 逐个node内部上锁: 只会保证内部的访问不会被竞争, 无法保证node 之间的顺序
- 连环锁 hand-over-hand mutex
-
遵循如下代码结构
-
m1.lock(); handle1(); m2.lock(); m1.unlock(); handle2(); m2.unlock(); -
这就确保 acquire 第二个锁的时候在第一个 node 内部, 且不会导致竞争, 确保后续访问顺序和进入 list 的顺序一致
-
共享读锁与独占写锁
- 共享读锁 (boost::shared_lock) 指可以同时读取的一个 critical section 资源, 但是不可以被 写入 获取;
- 独占写锁 (boost::unique_lock) 指只能被一个线程所持有的关键资源, 不可以被其他写入或者读取获取;
- 可升级锁 (boost::upgrade_lock) 对于一个锁需要在经过判断之后进行升级的锁
- 升级流程: 原子性地将一个锁升级为独占写锁 (中间不会存在释放锁和加新锁的间隔), 并且等待当前所有的同一个
shared_lock完成读取操作并且释放资源之后再执行unique_lock来修改资源即可 - 可升级锁最多只能被一个线程拥有: 如果两个线程同时拥有同一个可升级锁, 那么当两个锁同时升级为独占锁, 那么就会互相等待对方释放其读取锁, 从而引发死锁 如果两个线程都需要对同一个资源进行 “可能升级的操作”, 直接各自申请
upgrade_lock即可,boost底层实现会强制等待前一个升级锁完全解锁以后才会将下一个锁变成可升级锁- 当线程 A 持有
upgrade_lock时, 其他线程的upgrade_lock或unique_lock请求会被直接阻塞, 底层实现保证本个可升级锁在升级的时候不会收到其他阻塞的同一个 upgrade_lock 的影响
- 当线程 A 持有
- 生命周期
- 原可升级读锁(upgrade_lock)的生命周期: 作用域结束时间: upgrade_lock 的生命周期到其 定义的作用域结束 为止(即其所在的代码块 {} 结束);
- 当调用 upgrade_to_unique_lock 升级为写锁时, 原 upgrade_lock 会被隐式释放(不再持有任何锁), 但其对象依然存在, 直到作用域结束
- 升级后的独占写锁(upgrade_to_unique_lock)的生命周期: 作用域结束时间: upgrade_to_unique_lock 的生命周期到其 定义的作用域结束 为止;
- 锁的所有权转移: 升级操作会将锁的所有权从 upgrade_lock 转移到 upgrade_to_unique_lock, 后者负责管理写锁的释放;
- 原可升级读锁(upgrade_lock)的生命周期: 作用域结束时间: upgrade_lock 的生命周期到其 定义的作用域结束 为止(即其所在的代码块 {} 结束);
- 升级流程: 原子性地将一个锁升级为独占写锁 (中间不会存在释放锁和加新锁的间隔), 并且等待当前所有的同一个
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.