3. 网络层
网络层基础
-
核心功能:
- 寻址(Addressing)
- 转发(Forwarding): 将数据包定向到正确接口(基于本地转发表);
- 路由(Routing): 全局计算转发表(通过路由协议);
-
架构分层:
- 数据平面(Data Plane): 处理单个数据包的转发(快速, 本地决策);
- 控制平面(Control Plane): 计算转发表的分布式算法(全局, 慢速);
IP协议核心设计
-
IP数据包结构:
-
Header:
字段名 位数 功能 版本号(Version) 4 标识IP版本(如IPv4=4); 头部长度(IHL) 4 以32位word为单位的头部长度(如无选项时为5, 对应20字节, 最长 60B 因为 IHL 最长 4bit 即 0xF word = 60B); 服务类型(ToS/DSCP) 8 定义优先级或拥塞通知(如ECN); 总长度(Total Length) 16 整个IP包的总字节数(最大65535字节); 生存时间(TTL) 8 防环路, 每经过一跳减1, 归零时丢弃包; 协议(Protocol) 8 标识上层协议(如TCP=6, UDP=17); 头部校验和(Checksum) 16 仅校验头部完整性, 每跳重新计算; 源/目的IP地址 32×2 端到端通信的基础; -
分片相关字段:
- 标识符(Identification): 唯一标记同一原始包的分片;
- 标志位(Flags):
- DF(Don’t Fragment): 禁止分片(若MTU不足则丢弃并返回ICMP错误);
- MF(More Fragments): 标记是否为最后一个分片;
- 偏移量(Fragment Offset): 以8字节为单位, 指示分片在原始包中的位置;
-
-
TTL (8b): 防止 loop
- 目的: 防止数据包在网络中无限循环;
- 实现: 每经过一个路由器, TTL 值减1, 当 TTL 为0 时, 路由器丢弃该包并发送 Time exceeded 错误消息给 src;
-
校验和(Checksum): 仅校验头部, 每经过一个路由器需重新计算;
- 由于 header 的 ttl 在每一个路由器都会发生变化, 所以每一个路由器都需要重新计算校验和
-
Type of Service (ToS): 支持 优先级和服务质量(QoS) 特殊处理
- 目的: 可针对服务 priority, congestion notification 特殊处理一些包;
- 现在称为 DSCP (Differentiated Service Code Point)
-
Options: 可选字段, 用于调试或特殊需求;
- 示例: 记录路由(Record Router), 时间戳(Timestamp), Strict/Loose Source Route 等;
-
Protocol: 指明上层协议类型;
- 常见值: TCP=6, UDP=17, ICMP=1;
- 作用: help with demultiplexing at the destination;
- 接收方 task: 1. 根据 transport layer header 来确定上层执行函数; 2. 发送
response 到src
- 接收方 task: 1. 根据 transport layer header 来确定上层执行函数; 2. 发送
分片与重组 Fragmentation and Reassembly
- 分片触发条件: 数据包超过链路MTU(如IPv4默认1500字节);
- 重组的问题:
- Fragment can get lost;
- Fragment can follow diff path;
- Fragment can get fragmented again -> 在中间重组有点小丑🤡,
且容易导致网络负载过重 - 结论: 重组只能在 destination 进行, 中间路由器不处理分片;
- 重组逻辑:
- 重组依据 (IPv4):
- 为了区分 packet 属于同一原始包, 使用 标识符 (Identifier);
- 确认 frag 是否有丢包, 需要 偏移量 (Fragment Offset), unit 8 Bytes;
- 判断是否最后一个 frag, 使用 MF (More Fragments Coming);
- 确保某些切片不会再被分片, 使用 DF (Don’t Fragment);
- 额外保留 1b (Reserved)
- 重组依据 (IPv4):
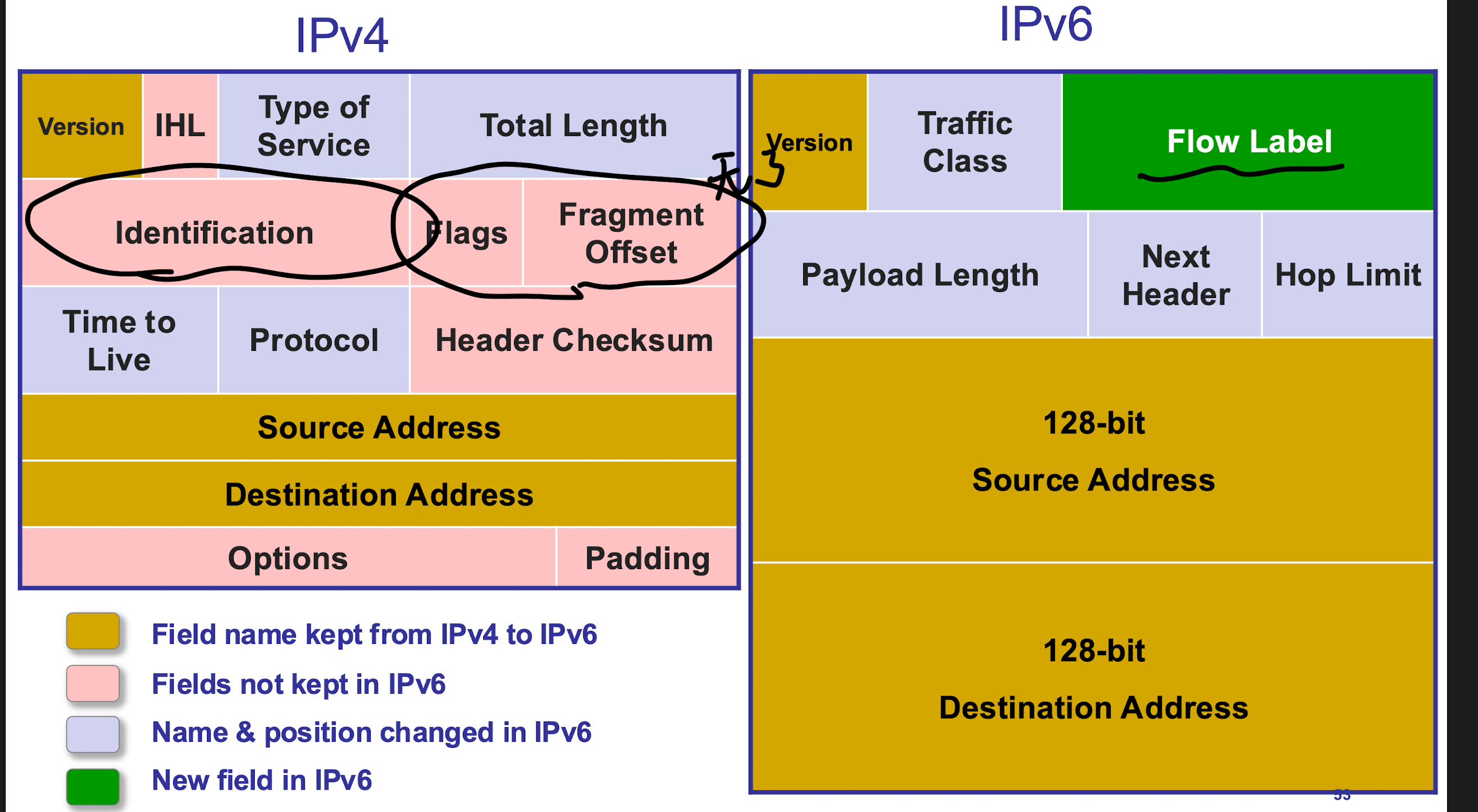
IPv6改进与设计哲学
- 核心改动:
- 地址扩展: 128位地址(彻底解决IPv4地址耗尽问题);
- 简化头部:
- eliminate fragmentation (分片由终端处理);
- eliminate checksum (依赖上层协议校验, 如TCP/UDP);
- new options mechanism: 通过"Next Header"字段链式扩展(更灵活);
- eliminate header length;
- IPv6主头部固定为40字节, 不再需要长度字段, 简化了数据包解析
- extension header 扩展头部为可选功能模块:
- 扩展头部仅在需要实现特定功能时添加(如分片, 路由选择, 安全加密等), 不同功能的扩展头部可以链式组合, 形成扩展头部链;
- add Flow Label: 标记数据流, 支持QoS, help classify;
- 20位流标签可标识特定数据流(如视频流, VoIP), 帮助路由器实现QoS(服务质量)和流量分类, 优化实时应用性能
- 设计原则:
- 端到端原则 E2E: 将复杂功能(如分片, 校验)移至终端;
- 高效性: 减少路由器处理开销(如去校验和, 固定头部);
路径 MTU 发现机制 Path MTU Discovery, PMTUD
为了找到路径MTU, 主机首先发送整个数据包, 并将ip首部的禁止分片标志设置为1,
这样路由器在遇到需要分片但是又不能分片的场景时, 直接丢弃并通过ICMP协议将整个不可达的消息发送给主机,
主机将ICMP通知中的MTU设置为当前的MTU, 根据整个MTU对数据进行分片处理;
如此反复, 直到不再收到ICMP通知, 此时的MTU就是路径MTU, 整个链路使用最小MTU发送数据
IPv6 利用在这个方法确保 E2E 的切片处理机制而不是在中间路由器处理切片
关键对比: IPv4 vs IPv6
| 特性 | IPv4 | IPv6 |
|---|---|---|
| 地址长度 | 32位 | 128位 |
| 分片 | 支持路由器分片 | 仅终端分片 |
| 校验和 | 头部校验和 | 无(依赖上层) |
| 头部长度 | 可变(含选项) | 固定40字节 |
| 流标签 | 无 | 支持20位流标签 |
路由器 Data Plane
IP路由器基础
- 核心作用: 互联网基础设施的核心组件, 市场规模超1200亿美元, 主要厂商(Cisco, Huawei, Juniper);
- 容量定义:
- 公式:
Router capacity = N × R- 也就是通过出口速率来定义路由器的容量;
N: 路由器端口数,R: 端口线速(如10/40/100 Gbps);
- 公式:
- 路由器类型:
- 核心路由器 Core: 高带宽(100Tbps聚合), 端口速率达400Gbps;
- 边缘路由器 Edge: 中等带宽(1Tbps聚合), 端口速率100Gbps;
- 小型企业路由器: 低带宽(<10Gbps), 端口速率1Gbps以下;
路由器内部结构
- 控制平面 Control Plane: 路由/控制处理器, 负责路由决策;
- 数据平面 Data Plane:
- 输入线卡 input linecard:
- 任务: 接收包, 更新IP头(TTL, 校验等), 执行最长前缀匹配(LPM)来查找output
linecard, queue the packet at the interconnection fabric; - 最大难度: 高速处理(100B包@200Gbps → 每4ns处理一个包), 依赖ASIC/网络处理器;
- 任务: 接收包, 更新IP头(TTL, 校验等), 执行最长前缀匹配(LPM)来查找output
- 交换结构 switch fabric: 连接输入与输出端口, 常见方式:
- 共享内存, 总线, 交叉开关(非阻塞, 如Crossbar);
- 输出线卡 output linecard:
- 功能: 包分类(多维度范围匹配), 缓冲区管理(如Drop-Tail), 调度算法;
- 输入线卡 input linecard:
线卡 Linecard
一个线卡可以同时作为接收端和发送端, 其与对应的 ip 地址 +
端口一一对应 (也有可能会有多个 ip 地址对应一个端口进行 broadcast)
Input Linecard Tasks
- 更新: 更新IP头部(TTL, 校验和等), 较为简单;
- 最长前缀匹配(LPM): 比较困难
- 目标: 根据目标IP地址查找最佳匹配端口;
- 实现: 树状数据结构(如Trie树)优化查找效率(O(log n));
- 示例: 地址范围分层匹配(如
110000xx→Port1,1101xxxx→Port4);
这里的困难往往通过硬件加速来解决
Output Linecard Tasks
- 分类 Classification: map packets to different flows;
- 缓冲区管理 Buffer Management: 避免拥塞, 决定何时丢何包;
- 调度算法 Scheduler: 决定何时发送何包, 保证公平性;
分类方法 Classification
- src/dest IP address/TCP port
- Type of Service (ToS) field in
- Type of Protocol (TCP/UDP)
调度算法 Scheduler
- 每一个 flow 都应该有对应的 queue, scheduler 应该决定的是哪一个 queue 应该被发送
- 调度算法的目的是 fast, 兼顾 fairness/priority
Round-Robin
- 每个队列轮流发送一个包, 表面上最公平的算法
- 如果轮询之间没有任何差异, 称为 fair-queue (FQ) 方法
- 如果会根据包的大小(正比关系)来调整, 称为 weighted fair-queue (WFQ) 方法,
如果每个队列权重相等, 那么就是 FQ
不同的输出方式
- FIFO: 最简单的处理方式
- no classification
- drop-tail buffer management: 当 buffer 已经满了则丢弃新来的包
- FIFO scheduling: 按照包到达的顺序来发送包
路由器辅助的拥塞控制
- 3 个核心目标:
- 隔离流量(公平性), 调整速率, 检测拥塞;
公平性模型 Isolation/Fairness
- 最大最小公平性 Max-Min Fairness:
- 公式:
a_i = min(f, r_i),∑a_i = C表示总物理带宽的 bottleneck; - 示例: 总带宽10G, 需求8G/6G/2G → 分配4G/4G/2G;
- 特点描述: 如果你的流量没有达到你收发端口速率上限,
那么没有别的端到端流量会大于你的流量 - 这事实上是 FQ 的一个特例或者说理想状态
- 公式:
- 公平队列(FQ): 隔离流量, 避免RTT依赖, 允许灵活速率调整;
- bit-by-bit fairness: 每在一个队列发送一个 bit 就切换到另一个队列,
并且计算虚拟时间, 把虚拟时间最短的放到最前面来发送, 优点是保证公平性, 最终导致 Max-Min
- bit-by-bit fairness: 每在一个队列发送一个 bit 就切换到另一个队列,
- MMF 和 FIFO 的对比
- FQ 优点:
- Isolation: cheating flows 无效了
- BW share 与 RTT 无关
- 每个 flow 都可以选择自己需要的调整策略
- FQ 缺点:
- 更加复杂, 需要保存更多的状态如 queue state 以及 packet book-keeping
- FQ 优点:
- FQ 对于链路拥塞的控制: 只能控制拥塞但是不能消除拥塞, 因为拥塞是由于链路的带宽不足导致的
- 例: 如果两条大带宽链路通过一条中等带宽共享链路连接到两条大小带宽链路上, 那么很有可能导致保证公平的状态下一条小链路的流量发送端会超额发送, 导致带宽浪费
- 特点是 Robust to:
- Cheating
- Variation in RTT
- Details of delay/reordering/retransmission
调整速率 Rate Adjustment: Rate Control Protocol (RCP)
- 每个包都带有一个 rate field 信息
- 路由器可以根据当前网络情况来计算 fair share 值并且插入到 packet header 中,
从而让 end-point 来调整自己的发送速率到 f
检测拥塞 Congestion Detection
- 显式拥塞通知(Explicit Congestion Notification, ECN):
- 作用: 但如果端到端能成功协商ECN的话, 支持ECN的路由器就可以发生拥塞时在IP报头中设置一个标记, 发出即将发生拥塞的信号, 而不是直接丢弃数据包; ECN减少了TCP的丢包数量, 通过避免重传, 减少了延迟(尤其是抖动), 提升了应用的性能
- TCP SYN 握手包会包含两个额外的flag: ECN-echo(ECE) 和 Congestion Window Reduced (CWR);
这样双方就可以协商在数据传输期间是否可以正确的处理设置了CE位的数据包 - 机制: 路由器通过 IP 包头标记拥塞(如 ToS/DSCP 位), 接收端通过ACK反馈; 优点: 区分拥塞与丢包, 减少延迟, 易于部署(如数据中心应用);
- 优点
- 可以区分 corruption (包破损) 和 congestion (拥塞) 的情况, 通过 rate
adjustment 来预先调整 - Serve as early indicator to avoid delay
- Easy to incrementally deploy (in ToS/DSCP field in IP header), common in
data center applications
- 可以区分 corruption (包破损) 和 congestion (拥塞) 的情况, 通过 rate
Intra-Domain Routing: AS 内部寻路
- 基本目标: 找到到达目的地的有效路径(Find Path to Destination);
- 扩展目标: 寻找最小成本路径(Least-Cost Path);
- 路由状态有效性(Valid Routing State):
- 全局路由状态有效当且仅当:
- 无死锁(No Dead Ends): 除目的地外, 所有节点均有下一跳;
- 无环路(No Loops): 数据包不会无限循环;
- 全局路由状态有效当且仅当:
路由状态分析(Routing State Analysis)
- 局部状态(Local State): 单个路由器的转发表(Forwarding Table), 无法独立验证有效性;
- 全局状态(Global State): 全网路由器的转发表集合, 决定数据包路径;
- 验证方法:
- 构建路由树(Spanning Tree):
- 标记指向目的地的下一跳(箭头表示);
- 删除未使用的链路;
- 若剩余结构为连通树且无环, 则状态有效;
- 示例分析:
- 有效状态: 形成连通树(如示例1);
- 无效状态: 存在环路或孤立节点(如示例2);
- 构建路由树(Spanning Tree):
最小成本路径路由(Least-Cost Path Routing)
-
目标: 基于链路成本(如延迟, 负载)计算源到目的地的最优路径;
-
核心算法: Dijkstra算法
- 输入: 网络拓扑图, 链路成本;
- 步骤:
- 初始化:
- 集合 , ;
- 其他节点初始距离为 , 直连节点距离为链路成本;
- 迭代更新:
- 选择未加入集合 的最小距离节点 ;
- 更新相邻节点 的距离: ;
- 重复直到所有节点加入 ;
- 初始化:
- 输出: 最短路径树(Shortest Path Tree)及转发表;
- 时间复杂度: , 适用于中小规模网络;
链路状态路由 (Link-State Routing)
-
核心算法
- Dijkstra算法(最短路径优先, SPF)
- 已知全网拓扑和链路成本, 计算从源到所有目的地的最短路径
- 每次迭代确定k个目的地的最短路径
- 每个路由器独立运行 Dijkstra 算法
- Dijkstra算法(最短路径优先, SPF)
-
链路状态泛洪 (Flooding)
- 路由器将本地链路状态信息广播至全网
- every router learns the entire network topology
- 转发规则: 收到信息的节点向所有接口转发(除来源接口)
- 触发条件:
- Topology change (link/node failure/recovery)
- Configuration change (link cost change)
- periodic updates (定时发送, 如每30秒)
- 路由器将本地链路状态信息广播至全网
-
收敛与性能 (Convergence)
-
收敛(convergence): 全网路由器达到一致 (consistent) 的路由表状态
- 触发条件: 链路状态泛洪完成, 所有路由器运行Dijkstra算法
- 收敛时间: 从链路状态变化到全网一致的时间
-
收敛延迟来源: 故障检测时间, 泛洪时间, 路由表重计算时间
-
收敛期间的问题: 路由环路, 黑洞丢包, 数据包乱序
-
收敛后特性: 全网一致的路由表, 避免环路
-
-
协议实现
- OSPF(开放最短路径优先, Open Shortest Path First)
- Open: Publicly Available;
- 直接基于IP传输, 使用可靠传输机制 (不是 udp/tcp)
- Flood 链路状态通告(LSA, link state advertisement) 至自治系统 (AS) 内所有路由器
- IS-IS(中间系统到中间系统)
- 与OSPF类似, 主要用于ISP网络
- OSPF(开放最短路径优先, Open Shortest Path First)
-
Scalability
- 消息复杂度: O(NE)(N为节点数, E为链路数)
- 计算复杂度:
- Convergence Delay: O(Network Diameter)
- 网络直径: 网络中任意两节点之间的最长最短路径
- Entries: O(N)
距离向量路由 (Distance-Vector Routing)
-
核心算法
- Bellman-Ford方程
- 通过邻居节点的距离向量迭代更新自身路由表
- 每个节点告知邻居其自身的 Global View
- 分布式, 异步更新: 节点仅与邻居交换距离向量(DV)
- Bellman-Ford方程
-
算法流程
- 节点维护自身距离向量 和邻居的DV
- 触发更新条件: 链路成本变化或收到邻居的新DV
- 更新规则: 根据Bellman-Ford方程重新计算并广播变化
-
Count-to-Infinity
- 距离向量路由的一个问题, 当链路失效时, 节点可能会错误地认为路径仍然存在, 导致无限循环更新
- 解决方案:
- Poison Reverse (毒性反转) 向邻居通告到达该目的地的距离为
- Loop-Free Path: 使用 path vector, 或者使用 src tracking
-
Scalability
- 消息复杂度小于 ls 算法
- 计算复杂度: O(N), 每次收到一个表对应更新
- Convergence Delay: O(Network Diameter)
- 网络直径: 网络中任意两节点之间的最长最短路径
- Entries: O(N)
路由协议对比
| 特性 | 链路状态路由 (Link-State) | 距离向量路由 (Distance-Vector) |
|---|---|---|
| | Message Complexity | O(NE) | O(N) |
| Convergence Delay | faster | varies, may have count-to-infinity problem |
| robustness | node can advertise wrong link cost, and node calc its own table | node can advertise wrong path cost, and nodes’ table error will propagate |
自治系统(Autonomous System, AS)
基本概念
- 定义: 由单一管理实体控制的网络区域(如ISP, 大型企业网络)
- AS编号(ASN): 全球唯一标识符(如密歇根大学拥有ASN 177-180)
- 数量统计:
- IPv4 AS约77,000个, IPv6 AS约34,750个(截至2025年)
- 流量集中趋势: 2019年, 前5大"超大型AS"(如Google, Netflix)贡献半数互联网流量
域内与域间路由对比
| 特性 | 域内路由(Intra-domain) | 域间路由(Inter-domain) |
|---|---|---|
| 协议 | OSPF(链路状态), RIP(距离向量), 统称为 IGP | BGP(路径向量, 策略驱动) |
| 目标 | 最短路径, 快速收敛 | 策略优先(商业关系, 隐私) |
| 挑战 | 快速计算路径, 避免环路 | Scalability, Autonomous, Privacy |
域间路由的挑战
1. 扩展性(Scaling)
- 功能要求: 每个路由器都应该能访问到全网的路由信息
- Naive: 每个路由器维护全网路由表, 但随着AS数量增加, 路由表将爆炸
- Better: 将多个地址相近的网址合并成一个路由表 entry 从而减小路由表大小
- Host addressing is the key to scalability: 通过层次化地址分配来减少路由表条目
2. 管理自治与隐私
自治系统应具有一定的自我管理属性, 包括:
- Freedom in picking routes
- 可以选择经过/不经过哪些路径
- Autonomy
- 对于内部采取 dv/ls 路由协议可以由自己 as 来决定
- 可以选取自己的 policy
- Privacy
- 可以选取自己的网络拓扑, routing policy
IP地址分配与CIDR
1. IPv4地址结构
- 32位地址: 分网络前缀(Network Prefix)和主机后缀(Host Suffix)
- 示例:
12.34.158.5/23→ 网络部分(前23位), 主机部分(后9位)
- 示例:
- Inter-domain Routing: 依靠于 network prefix 来进行路由
- CIDR (Classless Inter-Domain Routing 无类域间路由):
- 灵活划分网络与主机边界(如
12.34.158.0/26, 子网 subnet mask 掩码255.255.255.192)
- 灵活划分网络与主机边界(如
- Classful Addressing: 传统的类划分(如A/B/C类)已不再适用, CIDR取而代之
- 示例:
A类(0-127)→/8,B类(128-191)→/16,C类(192-223)→/24 - 会导致地址浪费, 例如主机数量介于 8 - 16 bit 之间就必须要用
/16的地址, 这样就会浪费掉 2^8 - 2^16 个地址
- 示例:
2. 地址分配层次 Hierarchical
- 聚合条件: 地址分配需 match 网络拓扑, 否则路由表无法有效聚合
- 加入新的节点: 新节点的加入只需要更新与其直接相连的路由器的路由表, 而不需要更新整个网络的路由表
- Multi-homed 问题: 当一个网络连接到多于一个 AS 的时候 (往往是为了 fault-tolerance 或者 load balancing), IP 地址的同类地址聚合可能会失效
- 路由表膨胀: 多宿主组织因拥有来自不同ISP的多个前缀, 这些前缀无法在全局范围内聚合, 从而导致全球路由表中的条目增加;
边界网关协议(BGP, Border Gateway Protocol)
1. 核心特性
- 策略驱动: AS基于商业关系选择路径, 而非单纯最短路径
- 路径向量协议: 广播完整AS路径(如
AS1 → AS3 → AS5), 避免环路
2. AS间商业关系
| 关系类型 | 经济模型 | 路由策略 |
|---|---|---|
| 客户-提供商 | 客户向提供商付费 | 提供商为客户流量提供中转(Transit) |
| 对等互联(Peering) | 互不付费, 流量对等交换 | 仅交换直接流量, 不中转第三方流量 |
3. 路由选择原则
- Valley-Free原则: 路径需避免"经济低谷"(如
客户 → 提供商 → 对等 → 客户无效) - 路由策略示例:
- 优先通过客户链路(产生收入)
- 避免通过竞争对手网络中转流量
4. BGP 选路优先级
| 优先级 | 规则 | 定义 | 备注 |
|---|---|---|---|
| 1 | LOCAL_PREF | 本地偏好值(Local Preference), 一个整数, 值越大越优先 | 仅在同一 AS 内部有效; 由 AS 内部管理员配置, 并通过 iBGP 向所有 BGP 邻居传播; 第一道门槛, 只在 LOCAL_PREF 相同的路径间继续后续比较 |
| 2 | AS_PATH | AS_PATH 列表记录了 UPDATE 消息中经过的 AS 序列; 长度越短, 跨越的 AS 越少 | 默认最低跳数优先; 可防止环路, 同时也是衡量"路径远近"的重要指标; 若 LOCAL_PREF 不同则不比较 AS_PATH |
| 3 | MED | Multi-Exit Discriminator, 多出口判别器, 邻居 AS 可打的推荐值, 值越小越优先 | 仅在同一个邻居 AS (源AS) 发过来的多条路径间比较; MED 默认不向其它邻居转发; AS_PATH 相同时才比较 MED |
| 4 | eBGP > iBGP | 区分路由是通过 eBGP(跨 AS)学到, 还是通过 iBGP(同 AS 内部)学到 | 优先使用通过 eBGP 收到的路由(更直接的外部链路); 如果同一前缀有一条 eBGP, 一条 iBGP, 选 eBGP |
| 5 | IGP 成本 | 本地 IGP(如 OSPF/IS-IS)到各条路径中 next-hop 下一跳的内部开销, 成本越低越优先 | 仅在多条 iBGP 路径之间比较; 选择到 next-hop 路由器距离最短(IGP 度量最小); 进一步优化内部转发效率 |
| 6 | Router ID | BGP 邻居的 Router ID(通常是最大的 Loopback IP 或手动配置的唯一标识) | 前 1–5 条都相同后才比较; 取数值最小的 Router ID; 最终 tiebreaker, 实际很少用到 |
软件定义网络 Software Defined Network (SDN)
控制平面机制
- Routing: Distributed Routing Algorithms
- Isolation: Firewalls
- Traffic Engineering: adjusting weights
抽象机制的问题
- Forwarding Abstraction (Data Plane): be compatible (兼容) with low-level hardware/software -> feature
- Network State Abstraction (Control Plane): make decision based on the entire network
- Specification Abstraction (Control Plane): compute configuration of each physical device -> configuration
Forwarding Abstraction
- 关注的是如何在高层次上描述"我要如何处理这些报文"
- 设计转发接口需要和硬件实现无关
- 设计细节需要考虑 header matching (协议表头匹配) 和 allowed actions
Network State Abstraction
- Global Network View
- 创建一个 logically centralized view of the network (Network Operating System)
- NOS通常运行在多个分布式控制器上(controller server);
- 虽然控制器可能在不同的物理节点上运行, 但从上层来看, 它们对外表现为一个"逻辑集中"的控制平面
- 信息双向流动(Information Flows Both Ways)
- 交换机或路由器会把自身的状态, 拓扑信息等数据上报给控制器, 控制器据此构建和更新全局网络视图
- 控制器基于全局视图和策略, 将配置或转发规则下发给交换机/路由器, 从而控制具体的转发行为
Specification Abstraction 规格抽象
- 把"高层策略定义"和"底层网络配置"分离开来, 让管理者可以更专注于"想要什么结果", 而不是"如何在硬件设备上实现这些结果"
- 控制机制仅表达"所需行为"
- 不管是隔离(Isolation), 访问控制(Access Control)还是服务质量(QoS), 在高层抽象里, 控制者只需要描述"我想要实现怎样的网络策略或行为"
- 不负责底层具体实现
- 抽象视图: 只包含实现目标所需的关键信息
- 根据不同的应用需求(Isolation, QoS等), 需要的细节可能不同;换言之, 不同场景下, 对网络拓扑或设备属性的关注点不一样, 但原则是"只保留与策略实现相关的细节", 以简化管理
目的
- "每个目标都可以作为一个应用"强调了SDN通过抽象化的方式, 把网络功能开发和底层设备管理分离开来, 让运营者能够灵活快速地实现各种定制化的网络需求
- 通过这种抽象, 网络功能的实现变得类似于"写一个程序"或"装一个插件", 而不需要在底层设备上手动配置复杂的命令
逻辑中心化管理
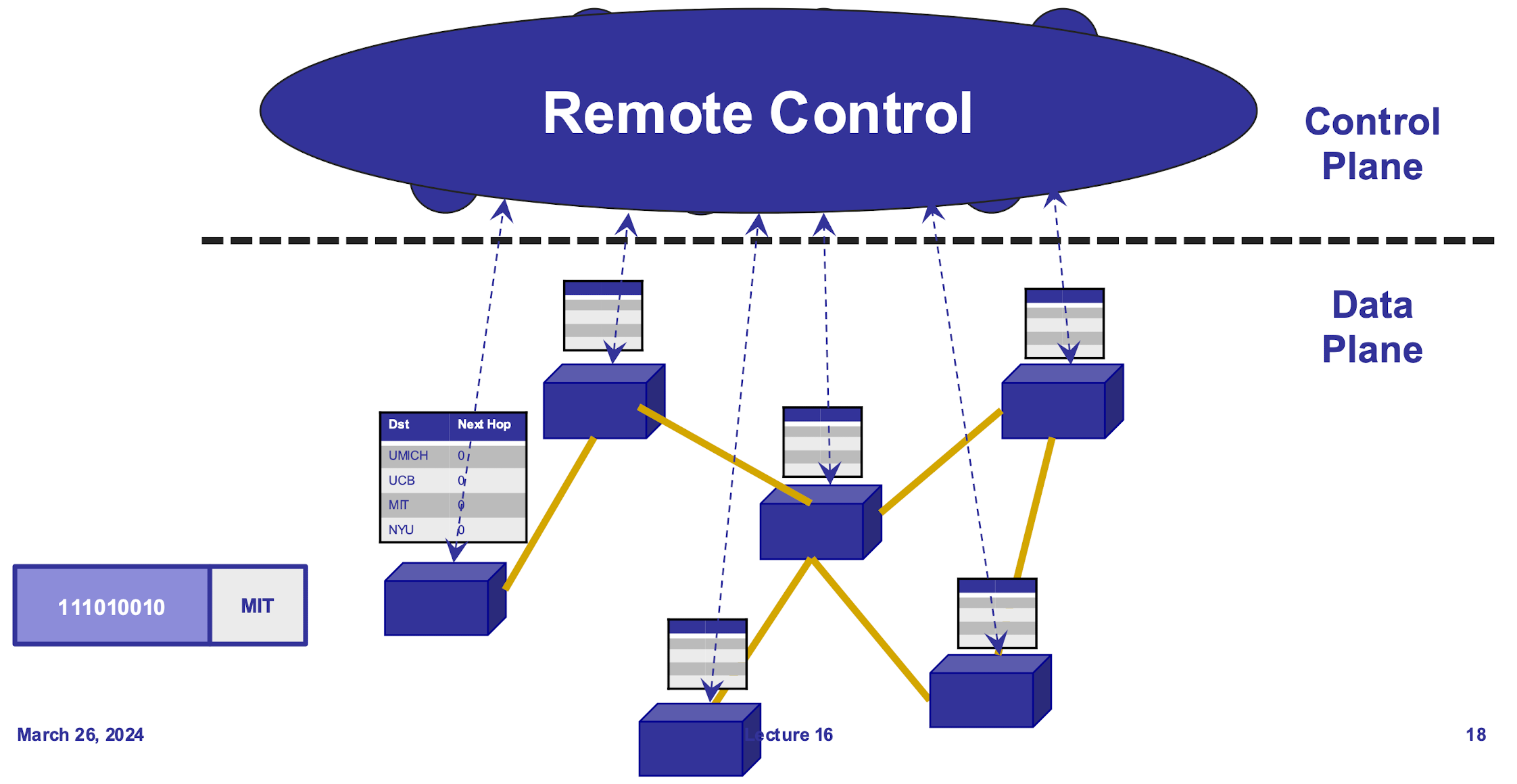
控制分布
- Distinct Remote Controller: interacts with local CAs
- Each router contains a flow table, each entry of the table defines a
match-action rule- 每个 table 条目如果发现 header-match 则会窒息那个这个 control action
- Entries of the flow table is computed and distributed by locally
centralized controller
OpenFlow 协议
对于 data plane 与 control plane 在 sdn 中的分离思想, openflow 是用来连接二者的
Data Plane Abstraction (Forwarding Abstraction)
- 基于报头字段来定义"流"
- 在OpenFlow中, 流(Flow)并不一定仅仅根据"源IP+目的IP"定义, 还可以匹配更多字段(如TCP/UDP端口, 以太网地址, VLAN, 协议类型等), 从而更加灵活地定义转发规则;
- 通用化的转发模型: 匹配-动作(Match-Action)
- 匹配(Pattern/Match): 根据数据包的报头字段(如IP地址, 端口, 协议)进行匹配;
- 动作(Action): 对匹配到的数据包执行的操作
- 丢弃(Drop)
- 转发(Forward)到指定端口或指定下一跳
- 修改(Modify)报头字段(如改写目的MAC或IP)
- 发送数据包到控制器(Controller)进行更高级别的处理
- 优先级(Priority)
- 当多个匹配规则可能同时适用于同一个数据包时, 需要依赖"优先级"来决定最终执行哪条规则;
- 例如, 匹配条件更精确的规则通常会被设置为更高优先级, 以免被宽泛的规则"覆盖";
- 计数器(Counters)
- 对于每条流, OpenFlow可以维护一些统计信息, 例如匹配到的数据包数量(#packets), 数据字节数(#bytes)等;
- 这些统计信息对于网络监控, 流量分析以及策略动态调整非常有用
- Match-Action 统一化了不同设备的转发标准
OpenFlow 中 data 与 control 的交互
- 控制器可以远程 (TCP) 对交换机的流表进行增删改查, 从而实现对网络流量的集中式控制
- 三大类 OpenFlow 消息
- Controller-to-Switch: 由控制器发送给交换机的消息, 用于下发或查询流表规则, 获取交换机状态等;例如:
- Features: controller queries switch features, switch replies
- Configure: controller queries/sets switch configuration parameters
- Feature/Configure 区别:
- Feat: 交换机有多少个物理端口, 支持哪些 OpenFlow 版本, 支持的匹配字段类型, 最大流表容量
- Config: 设置交换机的端口状态(启用/禁用某端口), 设置交换机的流表老化时间(idle timeout/hard timeout), 或更改交换机的全局运行模式(如是否启用某些高级功能等)
- Feature/Configure 区别:
- Modify-State: add, delete, modify flow entries in the OpenFlow tables
- Packet-out: controller can send this packet out of specific switch port
- 控制器在没有收到数据包(如发生 miss 时)或希望主动发送数据包时, 将数据包交由交换机处理和发送;
- 指定对数据包执行的动作(如发送到特定端口, 广播, 或者其他修改动作), 以满足网络策略的要求
- Asynchronous(Switch-to-Controller): 交换机主动发送给控制器的消息, 通常用于上报事件或状态变化;例如:
- Packet-In(当交换机无法匹配到合适规则时, 将数据包及其元数据发送给控制器)
- Flow Removed(流表项过期或被移除时的通知)
- Port-Status(告诉控制器其端口状态的变化)
- Symmetric(对称消息): 可以在控制器与交换机任意一端发起, 主要用于一些通用目的的消息, 如保持连接或诊断;
- Controller-to-Switch: 由控制器发送给交换机的消息, 用于下发或查询流表规则, 获取交换机状态等;例如:
功能固定数据平面
- 传统交换机的"固定功能"特性
- 设计和生产时, 就已经决定了它能做哪些事, 支持哪些协议或处理哪些报头字段
- OpenFlow 早期也是一种固定协议
- 定义了固定的匹配字段(如源/目的 IP, 端口, MAC 等)
- 定义了有限的动作类型(如转发, 丢弃, 修改某些字段)
- 在传统网络设备开发模式下, 当网络运营方(Network Owner)需要新功能时, 往往要经历非常漫长的流程
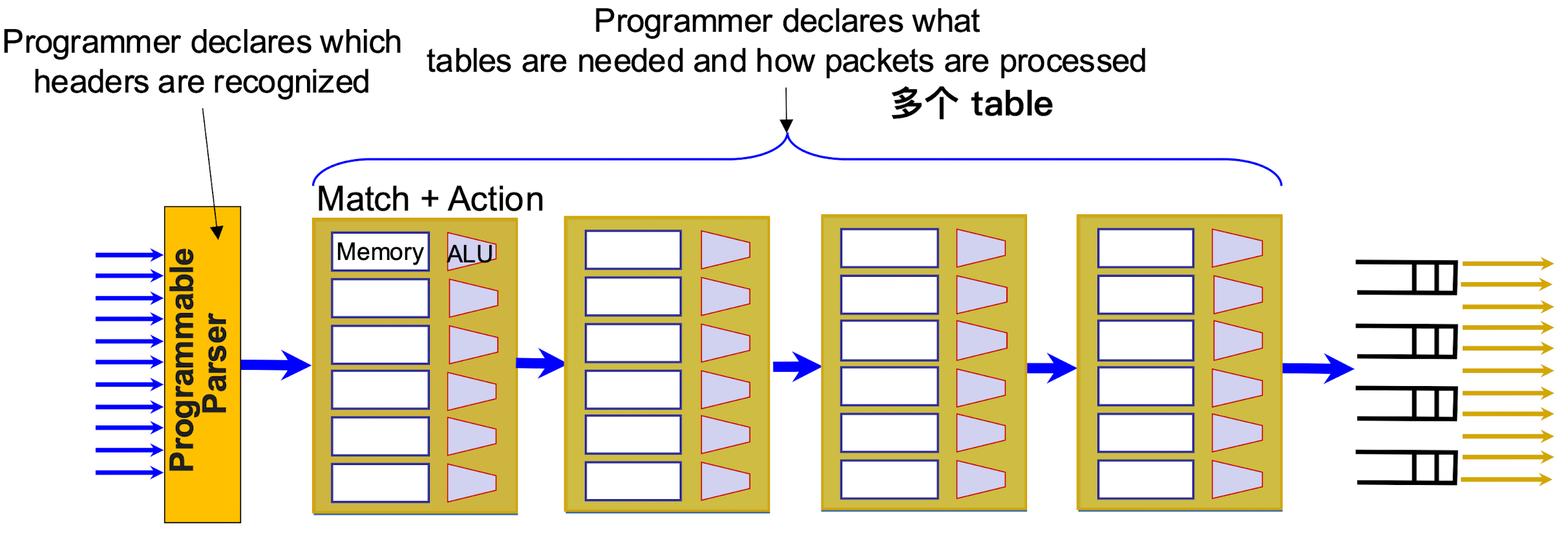
PISA 架构
- PISA(Protocol Independent Switch Architecture, 协议无关交换机架构)是一种面向可编程数据平面的芯片架构, 旨在摆脱传统网络设备"固定功能"的限制, 让开发者可以灵活定义要处理的协议, 报头字段以及具体的处理逻辑
- 将数据包处理划分为一系列相同的"流水线阶段(Pipeline Stages)", 每个阶段都包含:
- 匹配(Match): 对特定字段进行查表(如TCAM或SRAM)
- 动作(Action): 对匹配到的报文执行操作(如转发, 修改字段等)
- ALU(Arithmetic Logic Unit): 用于执行加减, 逻辑运算等简单计算
- 由于每个阶段的结构都相同, 开发者可以在编译时灵活安排每个阶段需要匹配哪些字段, 执行哪些动作;
- 多表(Multi-table)处理
- 与早期 OpenFlow"单表或固定数量表"不同, PISA 允许程序员声明任意数量的查表操作, 串联多个表来完成复杂的逻辑;
- 每个流水线阶段可以看作一个或多个 M-A 表; 数据包在通过整个流水线时, 可以被逐步解析, 匹配并执行各种动作;
- 协议无关(Protocol Independent)
- "协议无关"意味着该架构并不固化对任何特定协议(如 IPv4, IPv6, MPLS 等)的处理逻辑;
- 只要开发者在程序(P4 等)中定义好所需的协议头及处理方式, 硬件就能照着执行;
- 这为快速支持新协议或自定义协议提供了极大的灵活性;