
1. 多线程同步机制
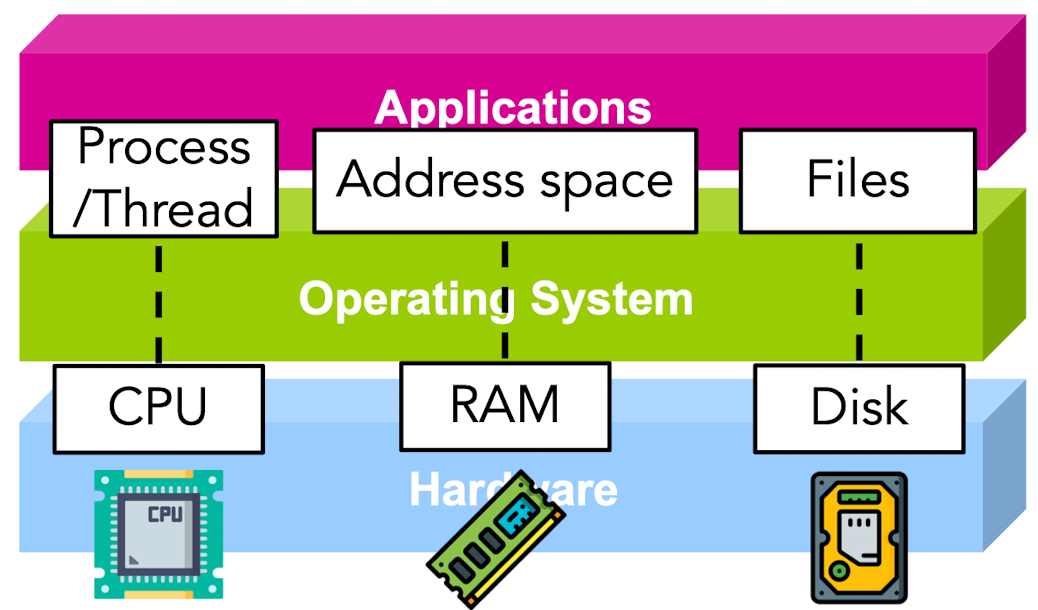
OS 抽象机制
OS 是一种对硬件功能映射到软件层的抽象机制
- cpu -> process/thread
- ram -> address space
- disk -> files
进程属性
进程 process 是一个在执行中的程序, program 是一个静态 static 的实体,有能执行的潜能
每个线程拥有所有程序运行所需要的状态和属性
- address space (memory)
- code (text)
- data (global -> heap)
- stack (运行状态)
- PC 表示程序运行进度
- 通用reg
- 通用 OS 资源如网络连接等
进程之间互相 isolate 即不可访问其他线程
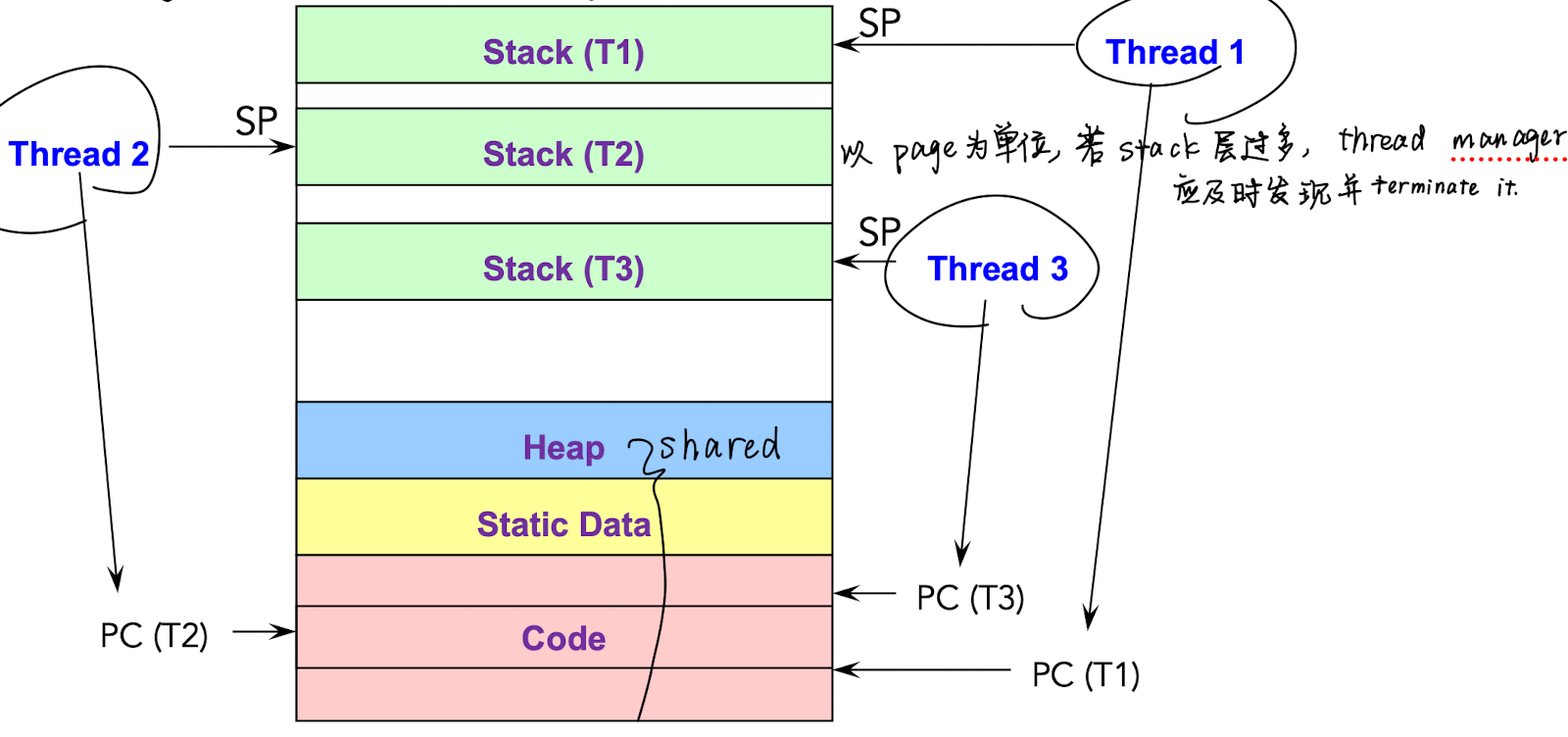
线程属性
线程表示的是一系列执行流 execution stream
定义了 PC, SP, register, 没有定义单独的 address space, general process attributes (PID, open files…)
每个线程只能归属于一个 process, 一个进程可以有多个线程
同进程线程共享
进程内表示状态的资源: regs, code, stack, data segment
每个线程独自拥有: stack (SP), regs, PC
共享: code, data segment
即 stack 独自,heap 共享,所以建立在 page 的两端不会互相冲突
线程目的抽象
一个进程下多个线程的并发 concurrency 可以通过资源同步来合作同时运行来完成任务,这里涉及两个目的:
- 资源同步
- 多个线程 (数量可能超过 cpu 可以同时处理的任务数量) 如何合理分配 cpu 执行顺序和时间
多线程的使用原因
- 单线程处理: 满处理程序会耽误快速处理程序的执行时间
- 异步 io: 输入和处理是异步进行的,快但是需要很多 state 来记录每个请求的状态,以及要记录正在处理哪个请求
- 每个请求对应一个 thread: 允许很多函数并行运行,轻量级
- 系统自带的 thread manager 会管理 cpu 共用资源
- 每个线程的状态属于该线程,管理方便
多线程的缺点
- 过多线程导致性能下降
- 资源同步困难
- 不定性,不同线程的运行速度完全不确定,对于不同资源的访问和修改时间节点不可预测
多线程适用场景
- network
- disk
- user
- 分治算法 (不同分支之间完全没有影响)
Inverleaving
资源交叉下,需要确保资源的访问修改顺序符合我们预期的结果
互斥锁 Mutual Exclusive Lock (Mutex)
假设 A B 同时会访问冰箱并查看其中有无牛奶,如果没有牛奶则前往购买,目的是没有牛奶后尽快有人去购买牛奶,且冰箱放不下 2 瓶牛奶
如果直接并行,那么 check() 与 buy() 的时间并不能进行限制,即可能出现 A.check() -> B.check()->A.buy() & B.buy() 的情况买了两杯
Critical Section 临界段
上述问题中牛奶数量的访问是一种临界数据段,需要遵循以下四种要求
- mutual exclusion: 同一时间只有一个线程能访问这个段落
- progress:
- 如果临界段没有被占用那么任意线程可以直接进入之
- 在临界段内的线程一定会在有限时间内离开该段落
- 不可以在临界段内不离开临界段而执行 return/throw 等跳出
- bounded waiting: 等待进入临界段的线程一定会进入
- performance: 等待和退出临界段的 overhead 一定要尽量小
其中 2.3. 可以合称 liveness,即等待时间需要有限
应用到上述过程中,就是AB访问牛奶不能同步运行,如果A先访问,则B准备访问的时候必须先等待A访问结束才能接着访问是否有牛奶,这时候A可以在临界段内留下 “前往购买中” 之类的信息告诉 B 不需要购买,这样 B 就不会重复执行buy()函数了
原子级指令 atomic
指不可分割的指令,内部的代码要么没有完成要么以完成状态出现,虽然内部多步指令并不是在同一瞬间发生执行的,但是同时的目的是让不同指令按照顺序完成执行,即可以通过互斥锁的包装使得访问这些数据的指令不能同时运行(包括多核下其他 cpu 核心不能执行以及中断不能强制停止当前线程的执行),从而形成了次序结构
包裹内容
由上可知手动原子级指令是将可并行的程序强制时间上串行以保证同步性,但可知这里浪费了一定的速度,可以改进包裹的内容
例如, 最简单的包裹是包含 A 查看冰箱和 A 买完牛奶然后 B 访问,这样 B 看到的一定是 冰箱里有牛奶,但是 buy 是一个很慢的过程,B 线程需要浪费很多时间来进行等待,但是前面举的例子里面A留下告示说明自己已经去买了,那么B就可以很快看到这个指令,而也不会买到2杯牛奶,因此并不是一个坏事
因此可以简单总结一下包裹的内容:
- 包裹的是类似 bool 或者 enum 之类的 state 变量的查询或者修改,往往用于同类 (执行同一个函数的多个线程) 之间不要多次执行一类操作
- 不改变或者不访问相关状态的函数可以放在 mutex 外面进行
invariant 不变量 (纯 mutex 类)
一个互斥锁包含了一系列的 bool 或者 enum state,并且需要根据设定保持在锁外某些表达式要保持一定的不变量,这些不变量只能在锁内部进行解锁与修改
例如上述例子,两个同类使用mutex互斥的时候需要在锁外保持 is_milk_not_empty | is_going_to_buy == true 从而第二个访问的人看到的要么是有牛奶,要么是已经去买了从而不会再去买第二次
这种同类之间互斥的不变量就是为了确保每个指令能正确执行并且只执行一次
粗粒度锁 coarse-grain mutex
互斥锁的设计应该是比较粗的,即一个锁包括一类(多个)相关状态变量, 但是对某个相关状态变量而言其不能被多个 mutex 分别保护,并且一次性包裹连续的访问,修改流程,达到保证不变量;考虑到 efficiency 的问题, 例如 buy() 需要占用很长的时间且会更改 is_milk_not_empty 的状态变量,可以分割状态,用一个类似 is_bought 之类的 state 变量记录购买完成的状态,并且放在 buy() 的后面实现, 从而可以将慢过程放在锁外加快速度
Fine-grain locking problem
细粒度锁对应的就是每个锁管理的变量类别较少且不可交叉,说明一些整体的属性很难控制不变量 (因为没有对应的更大的、套住整体的锁)
例如 buy() 拆分成 go_to_market(); pick(); pay() 三步,二人都可以执行
条件变量 (Condition Variable)
在等待一个 state flag 满足一定条件的时候会进行 while(state) 的等待,
此时为了能让其他线程能够丢改这个 state (在critical内部), 就必须要不断给 mutex
unlock 然后为了确保 invariant (离开 while 去执行后续指令的时候仍然要上锁),
就需要不断 接着 lock, 如下:
1 | while(state) { |
像这种一直在重复 while 循环的操作称为 busy waiting, 会浪费很多 cpu 资源,
同时考虑如下情景: 对于一个 queue 类有一对相反操作 (注意上述 mutex 举例是同类操作) enqueue 和 dequeue, 其中对于 dequeue 应该首先判断当前 queue 的尺寸是不是大于 0, 只有确保 >0 才能 dequeue, 如果 =0 则将当前线程放入等待队列, 直到有 enqueue 操作之后再执行此次 dequeue. 这里其实强调了一个相对操作下的 顺序问题(Ordering).
原子级三部曲
在 queue 的例子中, 假设 enqueue 函数实现如下:
1 | void enqueue(){ |
那么考虑在 dequeue 函数中的 while(!queue.empty()) 内部的 unlock 和 lock 以及
a) add curr thread to waiting set, b) release the lock c) go to sleep 三步指令的顺序, 尤其是 unlock 的位置会导致对应的 enqueue 并发影响:
- 如果 unlock -> to_waiting_set -> sleep -> lock, 则在 解锁之后可能在 enqueue
中率先 enqueue 并且检查 dequeue waiting set (此时为空), 然后才轮到
to_waiting_set, 这个顺序导致该线程没有被及时唤醒 - 如果 to_waiting_set -> unlock -> sleep -> lock, 则在解锁时候先执行 enqueue
导致前面等待enqueue的wait 已经被解决了, 但是这之后线程才执行 sleep 就不合理了 - 在 sleep -> unlock 不合理, 因为此时本线程已经沉睡了, 不应该还能执行指令
综上所述, 只能将三步变成一个 atomic 指令
Monitor
互斥锁 + 条件变量 (while 组合) 为一个 monitor
Producer-Customer 模型
这里指的是相对任务的双方互相等待的问题, 即对于一个商品存在一个产品buffer, 如果
buffer 不为空则 customer 可以消费, 如果 buffer 为空则 producer 可以生产, 如果
buffer 满了则 producer 等待, 如果 buffer 空了则 customer 等待
减少 signal 和 broadcast 的次数
由于使用 while 是为了防止多个线程同时唤醒下某些 state 又不满足导致的缺失,
因此在这个模型中, 由于每次生产者只会生产一个产品, 也就是最多只能唤醒一个消费者,
因此在这个模型中不应该出现使用 broadcast 的情况, 而是应该使用 signal; 不仅如此,
在这个模型中, 并不是每次 消费者进行消费之后就一定要 signal 生产者来补充, 只有
buffer_size == MAX-1 的时候才有必要 signal (叫醒因为 buffer 填满而等待的生产者)
Readers-Writers 模型
这是一个同类不对称任务的问题, reader 和 writer 共享一个 web 资源, 其中 reader
可同时阅读, writer 不可以互相之间或者和 reader 同时享用资源
优先级模型
首先明确在这里 reader 之间可以共享资源, 因此唤醒 reader 采用的应该是 broadcast
函数, 但是 writer 之间不可以共享资源, 因此唤醒 writer 采用的应该是 signal 函数
其次, 如果想要给 reader 更高的优先级, 那么就应该先给 reader 进行 broadcast, 将
reader 线程放进 ready_queue 中, 再放入 writer 线程, 这样就可以保证 reader
线程的阅读率先执行