1. OSI 概述与应用层
概述
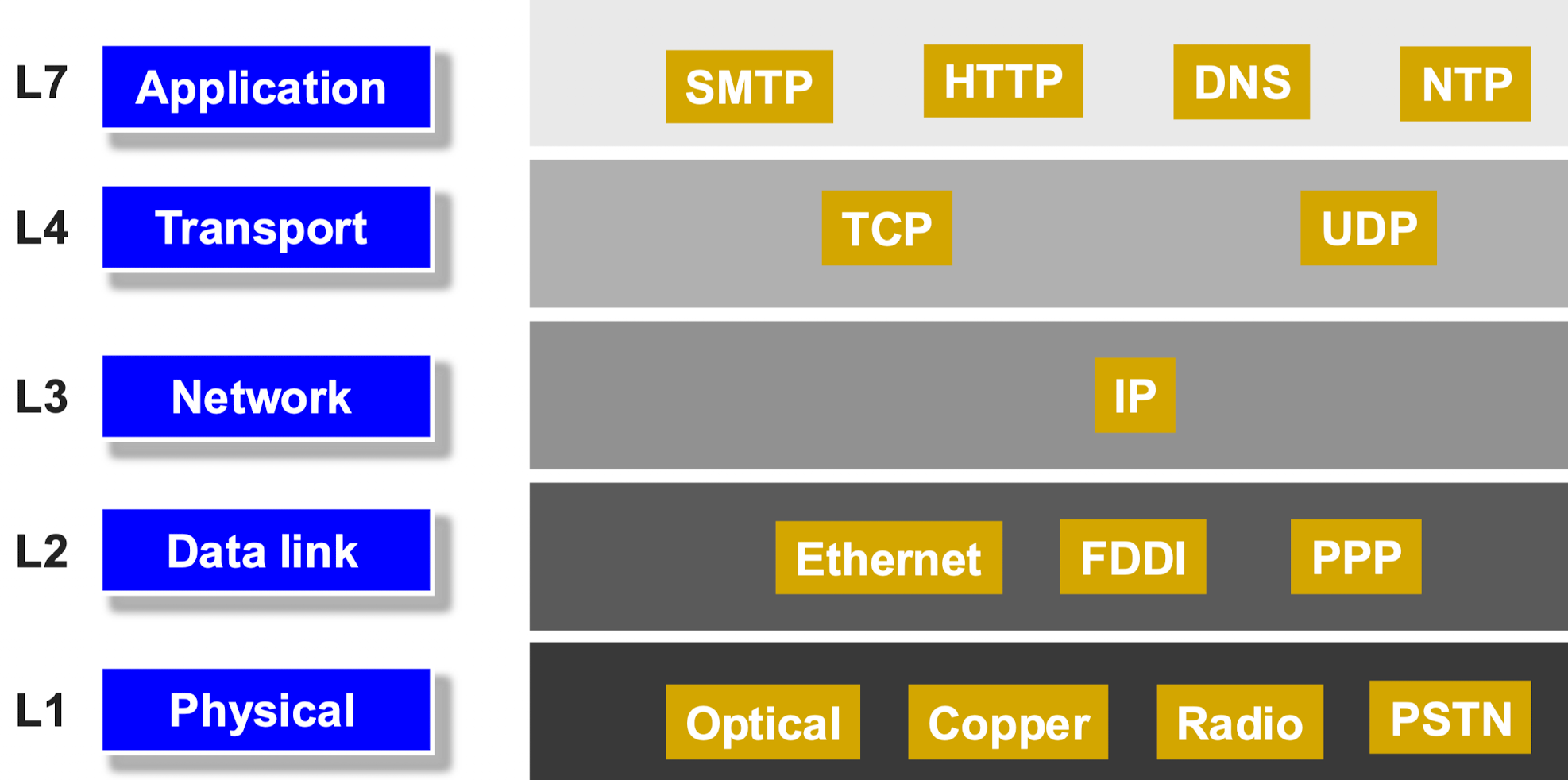
网络信息传播需要遵循 应用(Application) -> 封装送货信息+路由选择(Transport) -> 国际地址封装(Network) -> 地区地址封装(Data Link) -> 物理层发送(Physical) 的五层收发结构
- 低层级 (后面的不需要知道前面发生了什么)
- 每一层只负责该层任务以及与相邻层的 api 交互
- 同层之间遵循同样的协议,可以互相交流
分层的优缺点
优点
- reduce complexity
- improve flexibility
- better manageability
- increase redundancy (冗余多): 每一层都有自己的恢复措施,因此可靠性更强
缺点
- high overhead
- cross layer information is often useful
- speed decreased
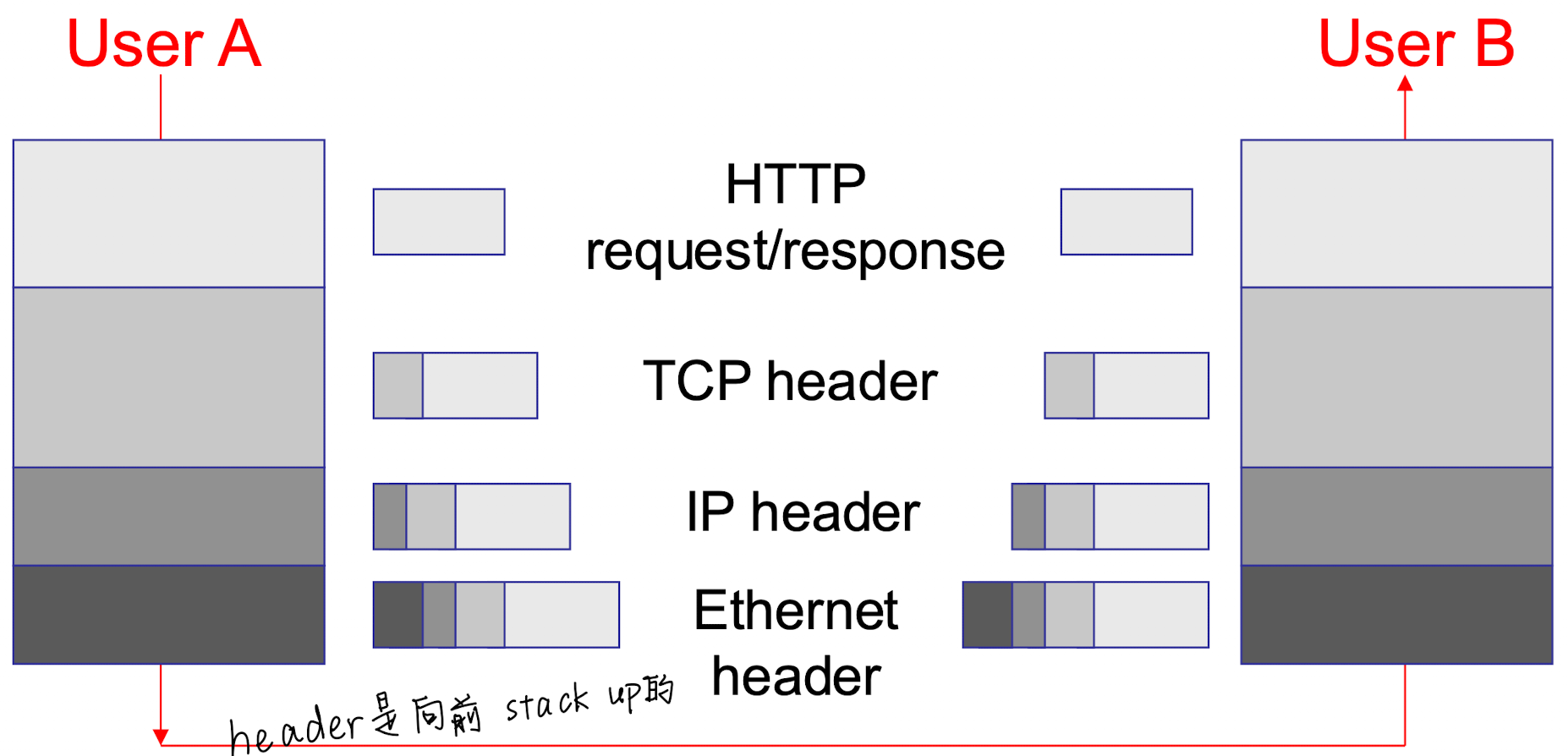
封装形式
- Header: 每一层协议,除了物理层都会给数据包在前面 append 一个表头表示 instructions on how to process payload.
- Payload: 表示有效的数据部分 semantic message
- Protocol 表示的是不同端共用的交流途径
传输模型
在网络数据传输模型中,只有两端的 end system (host) 可以拥有上面两层 application 和 transport 层,每一个 node 都会有下 3 层,其中链路交换机 (switch) 和路由器 (router) 有以下不同
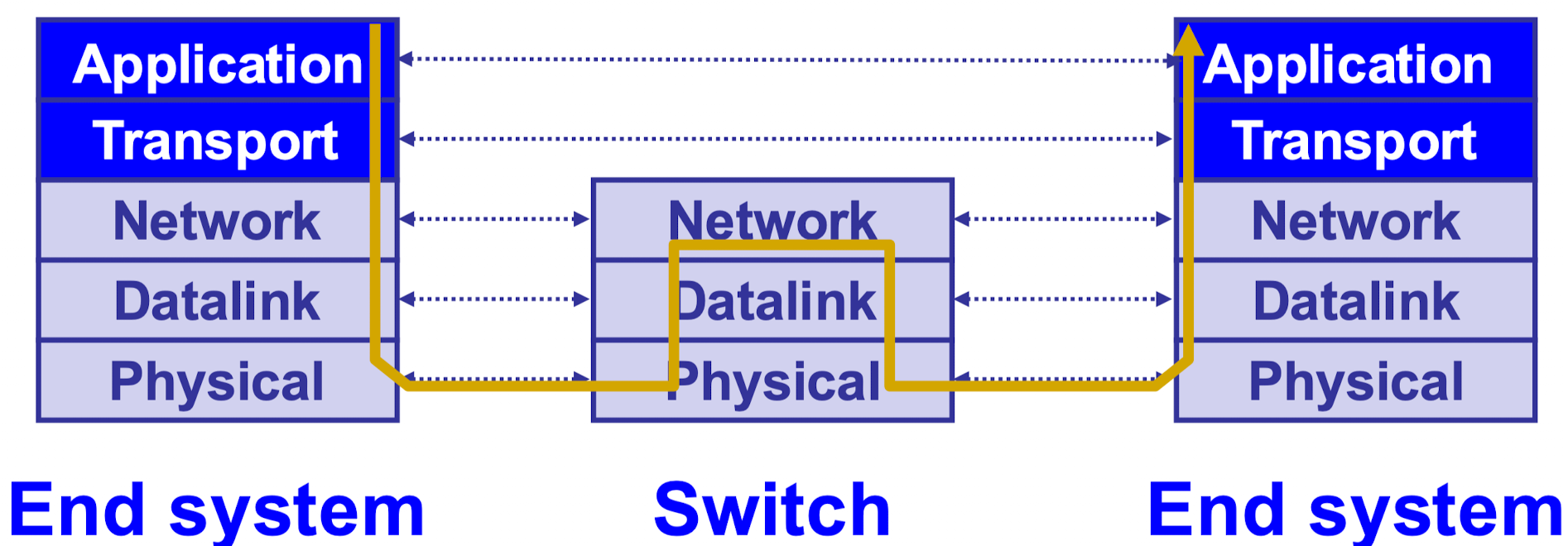
路由器和链路交换机
- 路由器可以拥有 network 层,可以解码 IP 协议包
- 链路交换机没有 network 层,不可以解码 IP 协议包, 只能收发本地数据包但是不能参与 global 的数据传输
transport 层简介
一般来说 transport 层是由操作系统负责的,有 tcp 和 udp 两个协议,前者提供了面向连接的服务,包括确保传递和流量控制;后者没有。
IP layer hourglass 沙漏构型
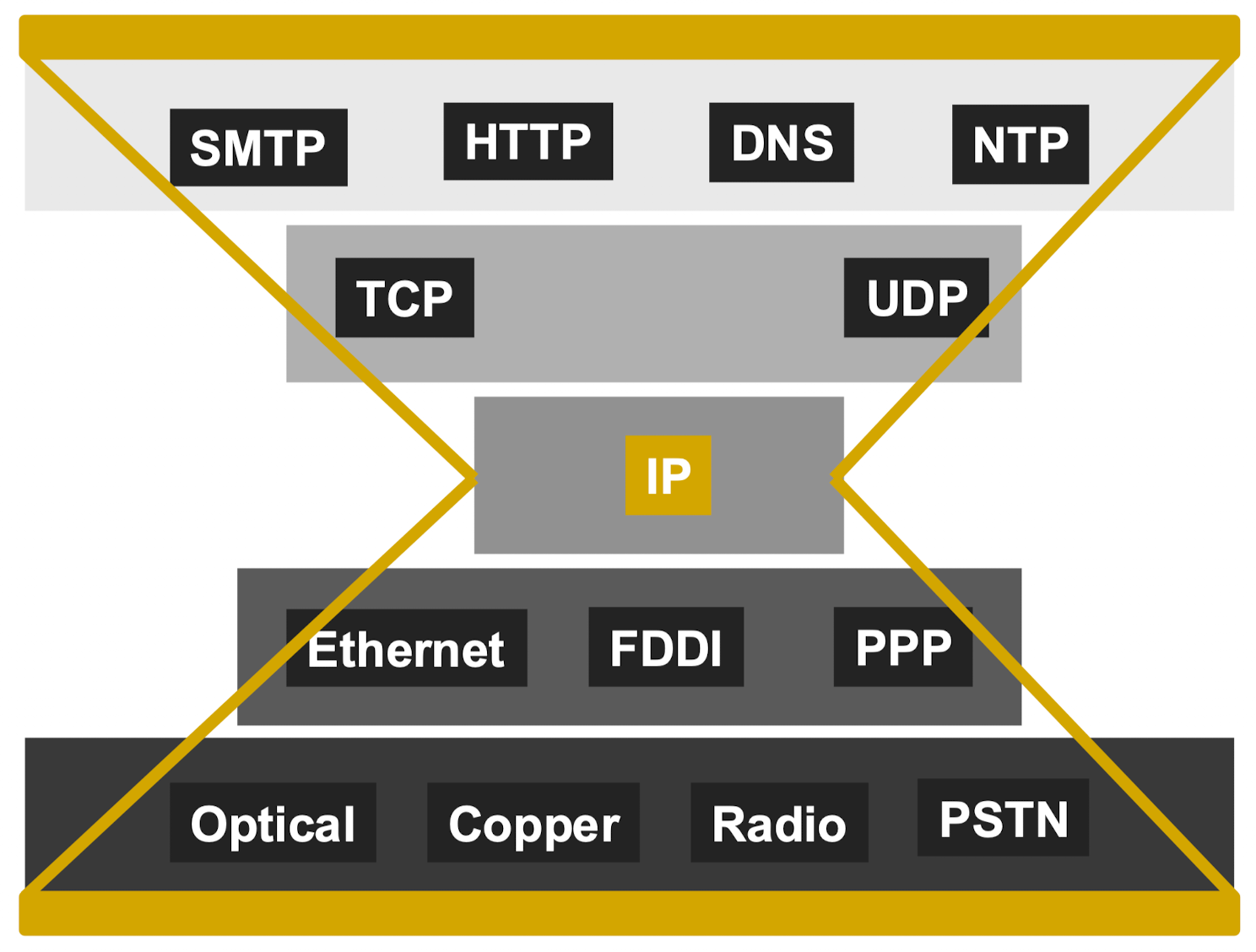
如图所示为osi的layer hourglass 模型,意思是以 ip 为界上下 decoupled (去耦合)
- 上层为应用层
- 下层为运输层
且 ip 协议可以让上下两层(软件硬件)之间的不同协议可以互相兼容,也可以支持上下两层各自迭代升级
allow arbitrary network to interoperate
ip 的局限
- IPv4 到 IPv6 的升级非常困难
End-to-end arguments
- 网络应该是 dumb 的,即传输过程包含尽量少的信息和检查
- endsystem smart,即由末端进行数据处理和检查
- 某些时候可以违反这个来达到更高的效率
- 中间 immediate node 不会对所有传入数据进行检查
例如在下载一个文件的时候往往会带有一个 signature (如下图) 用于验证下载是否完整,那么这一步应该只在 endsystem 处进行而不是在每个 node 进行检查

sharing fate
Fail together or don’t fail at all
指系统连接中如果某个元件失效,那么整个链路连接就发送数据失败,尤其指两个 end 任意一个失效,整个发送就无效
- server 端失效,则由于数据实体本身无效,故接收端也不应有效
- client 端关闭 browser, 那么数据也不需要了,因此传送无效
- 关闭路由器,那么链路断了,整个发送无效
应用层
历史
wwwdistributed db of pages linked through HTTP- 1990 first http implementation
- 1991 http0.9,
GETcmd from web - 1992 http1.0, client/server info, caching
- 1996 http1.1, performance&security optimization
- 2015 http2, latency optimized+binary protocol+server push
- 2022 http3, solves head-of-line(HOL) blocking problem
web 的组成部分
Infrastructure 基础组成
- client
- server
Content
- url: naming content
- html: formatting content
Protocol for exchanging content: HTTP
URL: Uniform Record Locator
协议写法 protocol://host-name[:port]/dir_path/resource
- protocol: http, https, ftp, smtp, rtsp…
- host-name: dns name (<www.baidu.com>) , ip addr(192.168.0.1)
- port: defaults to standard port of the protocol
- http: 80
- https: 443
HTTP: Hyper Text Transfer Protocol
client-server hierarchy
如下图所示
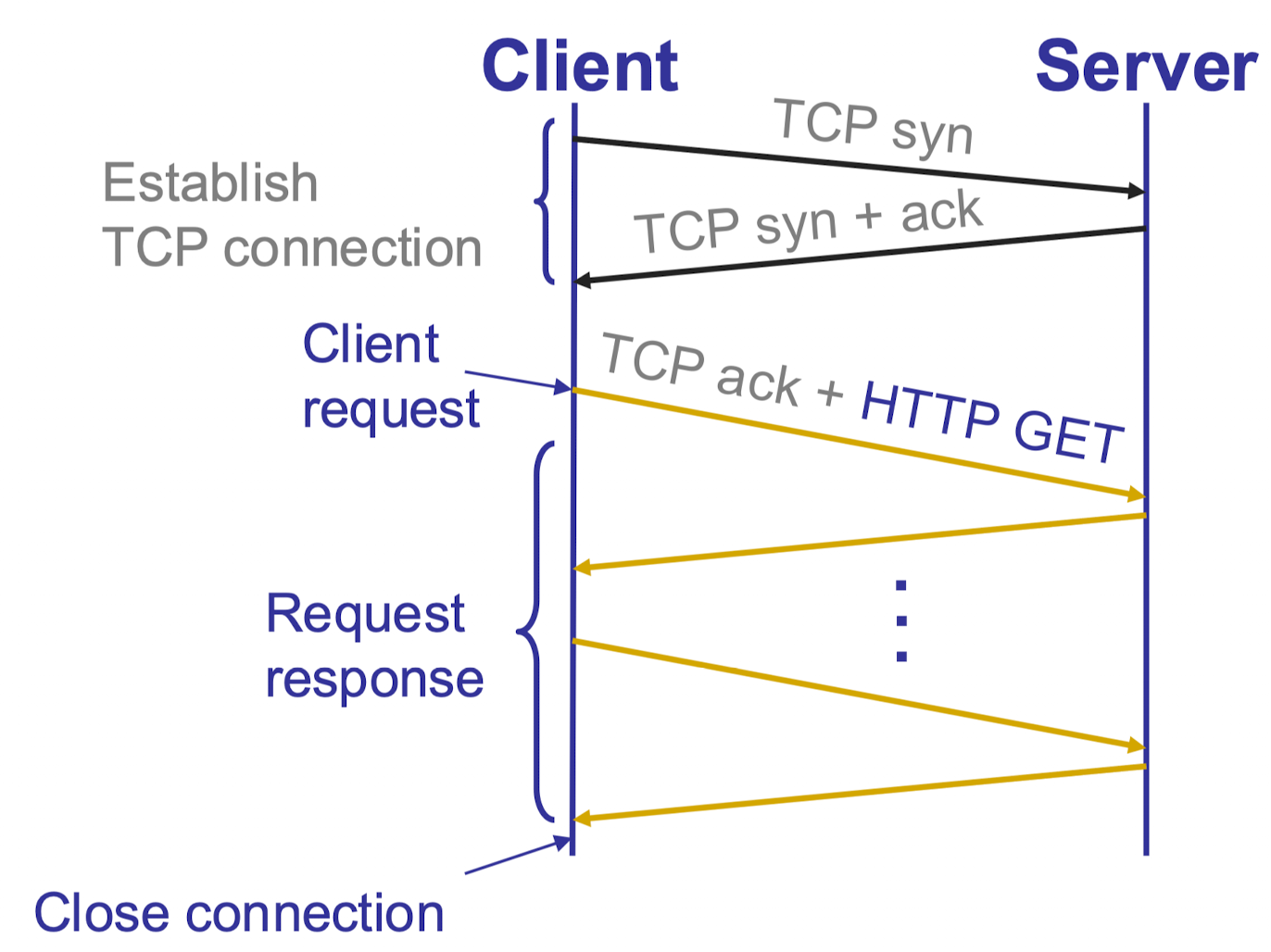
协议是一个 stateless 的量,早期为 ascii 格式 (http2前), 后来变成了 binary 格式
http1.1 定义的 method
- GET
- HEAD
- POST: 发送信息,比如 web form 网络表单
- PUT: 将文件通过路径发送到指定的 URL 地址下
- DELETE: 将文件从指定 url 的地址中删除
HTTP request
- c2s:
- rq line: method, resource, protocol+version
- rq header: info or modify rq
- body: optional data

- s2c:
- status line: protocol+version, status code, status phrase (OK 等)
- response header: info
- body: optional data
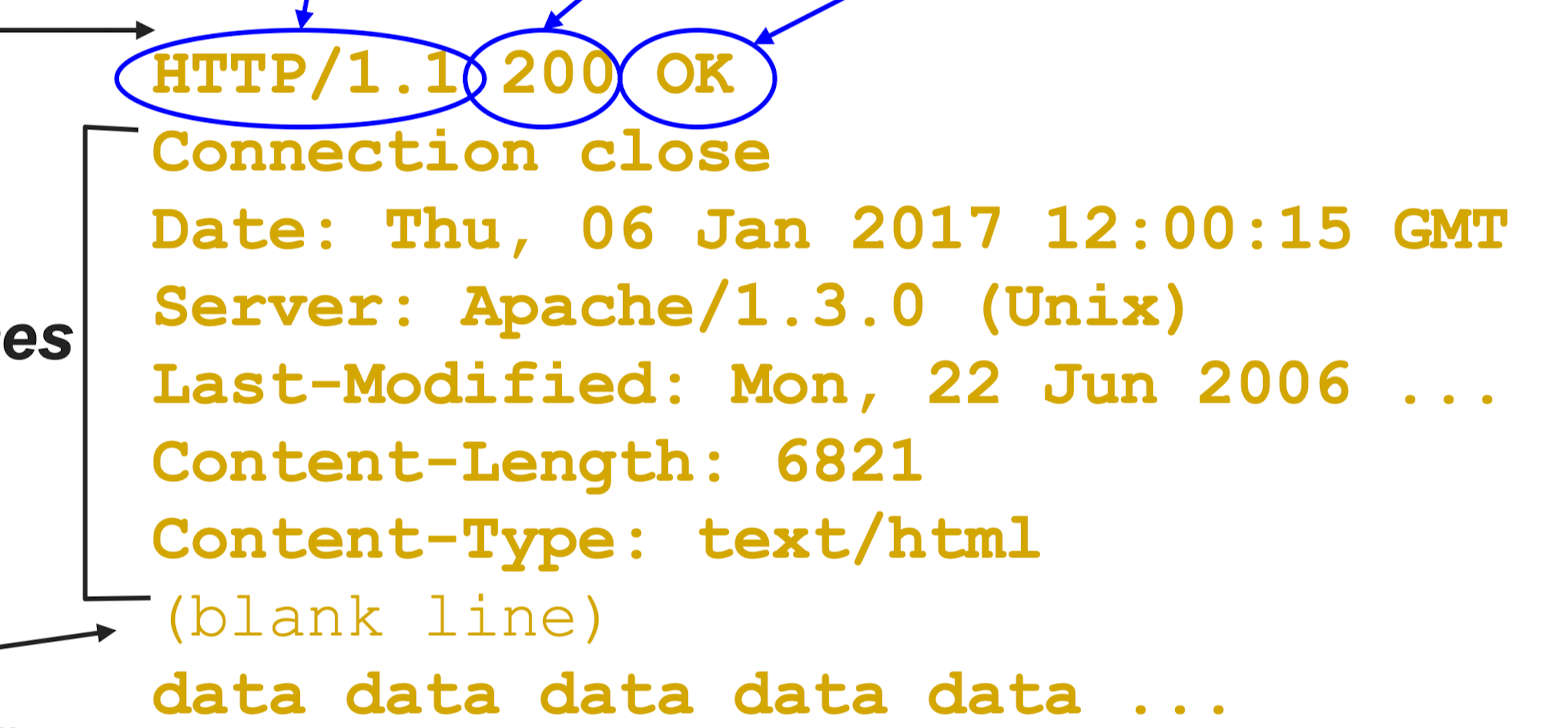
HTTP 无状态协议
每个 request 是独立对待的,也就是服务器并不需要存储每个访问的状态,节省了内存
- Pros:
- failure handle easy
- high rate of request
- order of request does not matter
- Cons:
- some apps need persistent state: shopping cart, user profile…
记录 HTTP 状态的元素: cookies
存储在 client 端的浏览器中,记录了server的状态,并且在访问 server 的时候会将数据传输给 server
可以作为 authentication, 例如每天只需要登陆一次 canvas
Web Performance
对于网页 html 的对象一般是 html 文本和一些潜入的 images
在通过网络获得这些内容的时候往往会 1 item at a time
也就是在 naive 网络协议中,每获得一个对象就需要新建一个 tcp 协议通道
下文将讨论一些优化的方法
Response time
- 1 RTT for tcp setup
- 1 RTT for http request and first few bytes
- transmission
总共 2RTT + transmission time (data size / bandwidth)
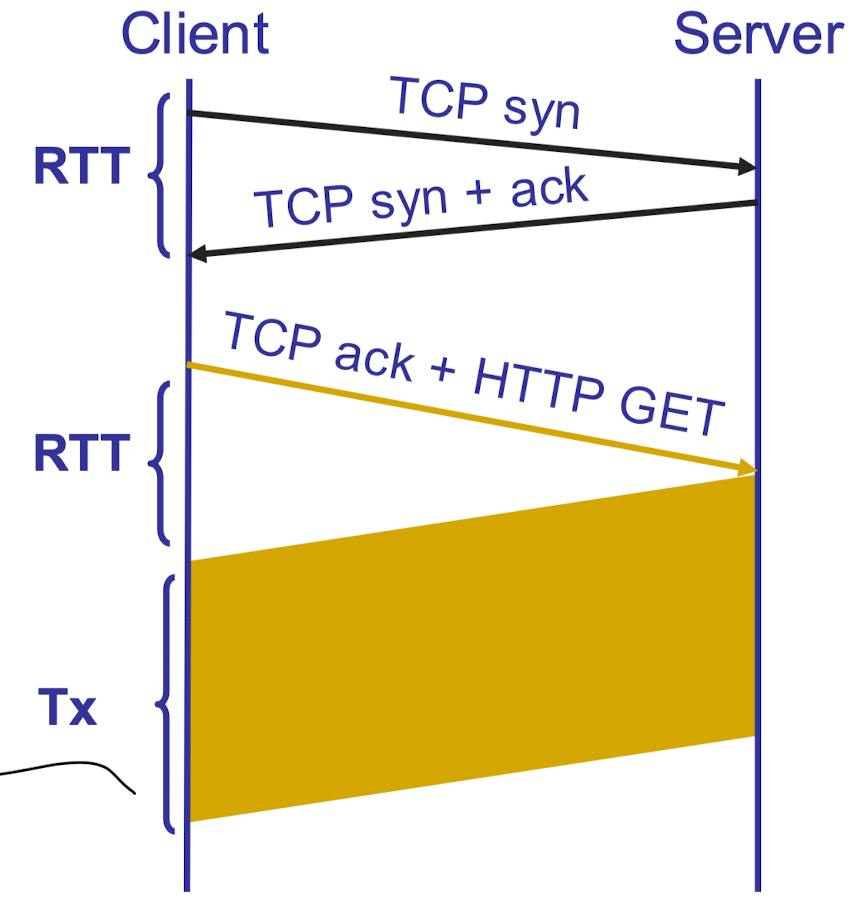
这是 http/1.0 版本下的传输时间消耗,这对于 html 本身和其内部任何一个 img 对象都要执行一遍,inefficient
并行处理方式 concurrency
将不同的请求以并行的方式发出,这对于 client 和 provider 来说都是好事,但是对于 network 来说并不是好事,因为并行传输会增大网络资源的消耗,对于 bandwidth 有一定的要求,并且由于线程的无序性可能会对顺序有一定要求
持续连接方式 persistent connections
对多次 request 保持 tcp 连接状态
将当前页面的所有 object 都在一次tcp建立的通道中传输,c/s 端可以tear down conn
优点是
- 避免多次连接的时间 overhead
- 允许底层的协议 如tcp 知道一些高层的参数比如 RTT 和 ban bandwidth 等特性参数
这个功能在 http/1.1 中实现并且设为默认
流水线处理方式 pipelined requests
将多次的请求设置为一个 batch 来统一回复,减少了 packet 的数量
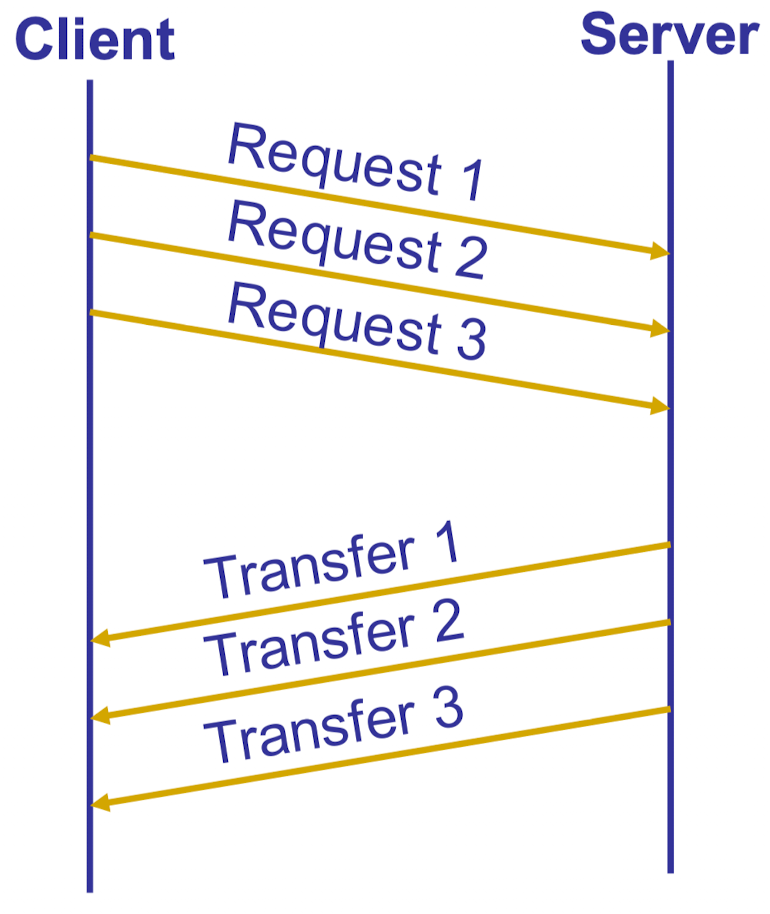
使用 FIFO 的顺序来处理收到的多个包,因此可能会遇到 HOL 问题 (即队列前面的包因为问题阻塞导致所有后面的包无法发送,这可以通过 优先队列的思想进行解决)
n个小数据包获取速度对比
此时包的尺寸忽略不计,主要是 propagation delay
| method | time |
|---|---|
| once-at-a-time | 2n RTT |
| m concurrent | 2n/m RTT |
| persistent | (n+1) RTT |
| pipelined | 2 RTT |
n个大数据包获取速度对比
定义每个数据包的尺寸为 F 定义 tcp throughput 限度是 而 link bandwidth 是 , 因此主要的限制因素是
整个传输过程的主要时间损耗是 transmission delay, 即想要加快只能提升 throughput
| method | time |
|---|---|
| once-at-a-time | RTT |
| m concurrent | RTT |
| persistent | RTT |
| pipelined | RTT |
注意上面假设了 即并行下 m 个 tcp 通道不会达到 的限制, 如果超过了就是 RTT
网络缓存器与内容分发网络 Web Cache and CDN
cache 实现
在http 表头有一个 If-modified-since 变量记录了是否在完成后发生过修改,如果返回 NotModified 则表示没有发生过变化,也有可能会返回一个 OK; 如果返回一个 Expires 表示资源的安全保存时长; No-Cache 表示忽略所有的 cache, 永远直接从 server 获取数据
cache 的存储位置
Reverse Proxies 反向代理缓存
在靠近源服务器的一些代理服务器会缓存一些服务器常常被访问的数据,从而在服务器发生高访问需求的时候进行代理转发,降低源服务器的访问量
Forward Proxies 正向代理缓存
主要服务于客户端,可以降低网络流量并且降低延迟,一般由 isp 提供
Content Distribution Networks (CDN)
网页复制 Replication
在多个地理位置分布服务器,用户访问最近的服务器
- 平衡服务器之间的访问负载
- 降低延迟和最大带宽使用
- 当内容没有 cache 的时候效果好
在 CDN 网络中,如果节点上没有缓存数据,就会从服务器 pull 数据存入,这就是 caching
如果内容非常流行而网络公司主动将高效数据推送到 cdn 节点上,那么就是 push (replication)
DNS: Domain Name System
发展
早期 host-address mapping 存储在 host.txt 文件中,但是由于网络膨胀,该方法不再使用
因此引发了如下需求
需求
- uniqness: 命名冲突少
- scalable: 新建的网站的 ip 容易加入到已有的文件中
- distributed: 自动整理,局部存储
- high available
- loopup fast
- 不要求 perfect consistency
因此采用继承架构 (hierarchy)
网络 dns 继承架构
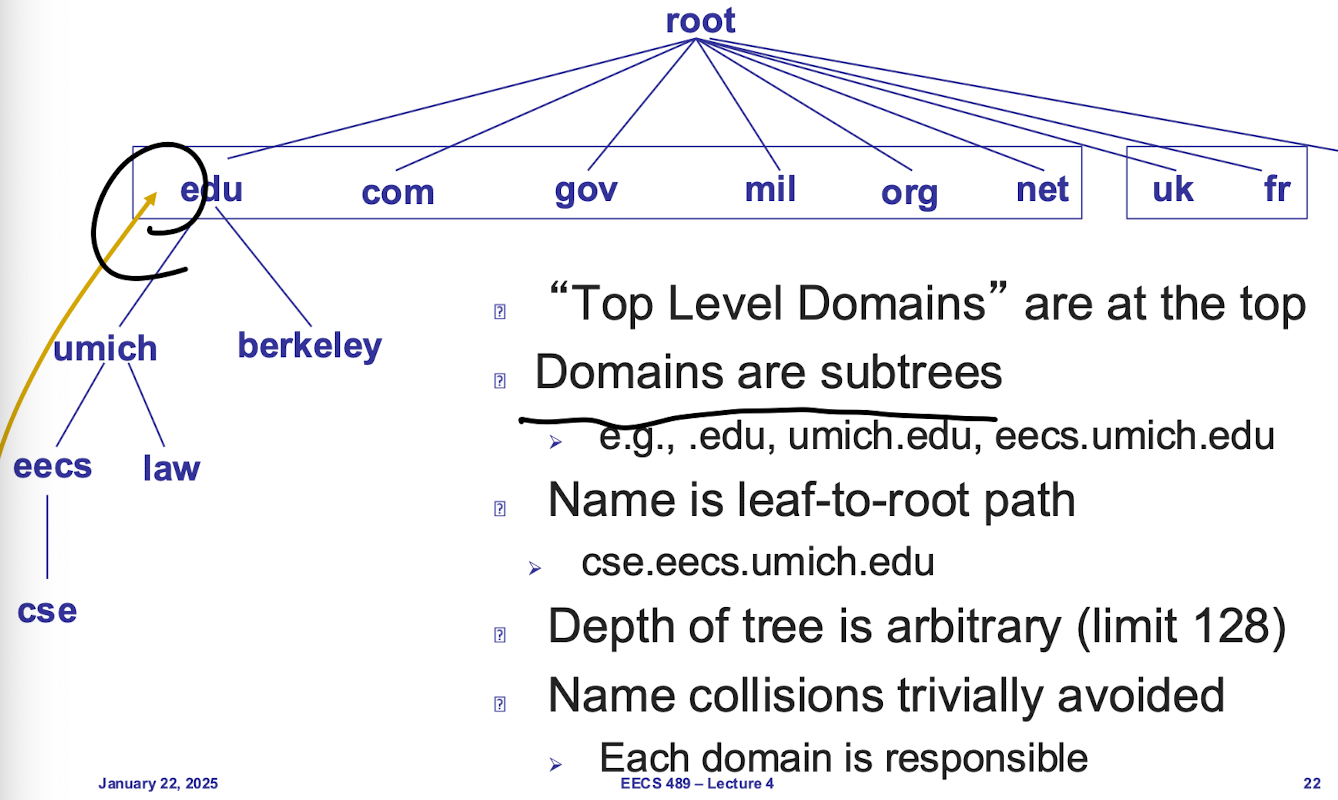
如图,这里root 表示根服务器,存储了各个 TLD (top level domain) 的服务器地址,url的域名通过从前向后地位递增进行解析查找
Authoritative DNS server: 最底层的域名,存储实际上的 name-to-address mapping,由对应的申请公司自行维护
Domain: 指的是子树,即从 对应根节点向下的所有域名集合
zone: 表示继承结构某一个枝干, 例如 JI 控制的部分为 *.ji.sjtu.edu.cn
存储形式: Resource Records
内容形式为 (name, val, type, TTL)
可以通过 type 来区分不同 RR 具体存储的内容形式
| type | name | val |
|---|---|---|
| A(Address) | hostname | ip address |
| NS(Name Server) | domain | name of DNS server for domain |
| CNAME(Canonical Name) | alias name | real name (canonical name) |
| MX(Mail eXchanger) | domain in email | name of mail server |
DNS 名称解码方法
- Recursive: ask server to do it for you
- Iterative: ask server who to ask next
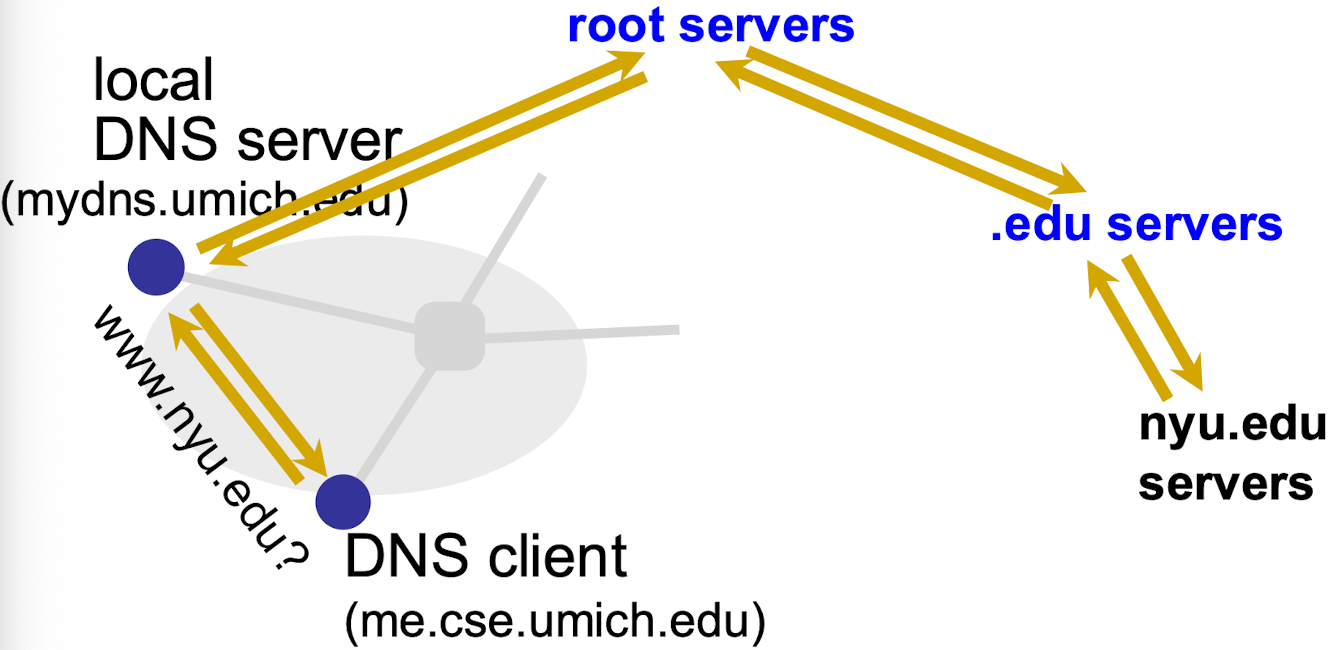
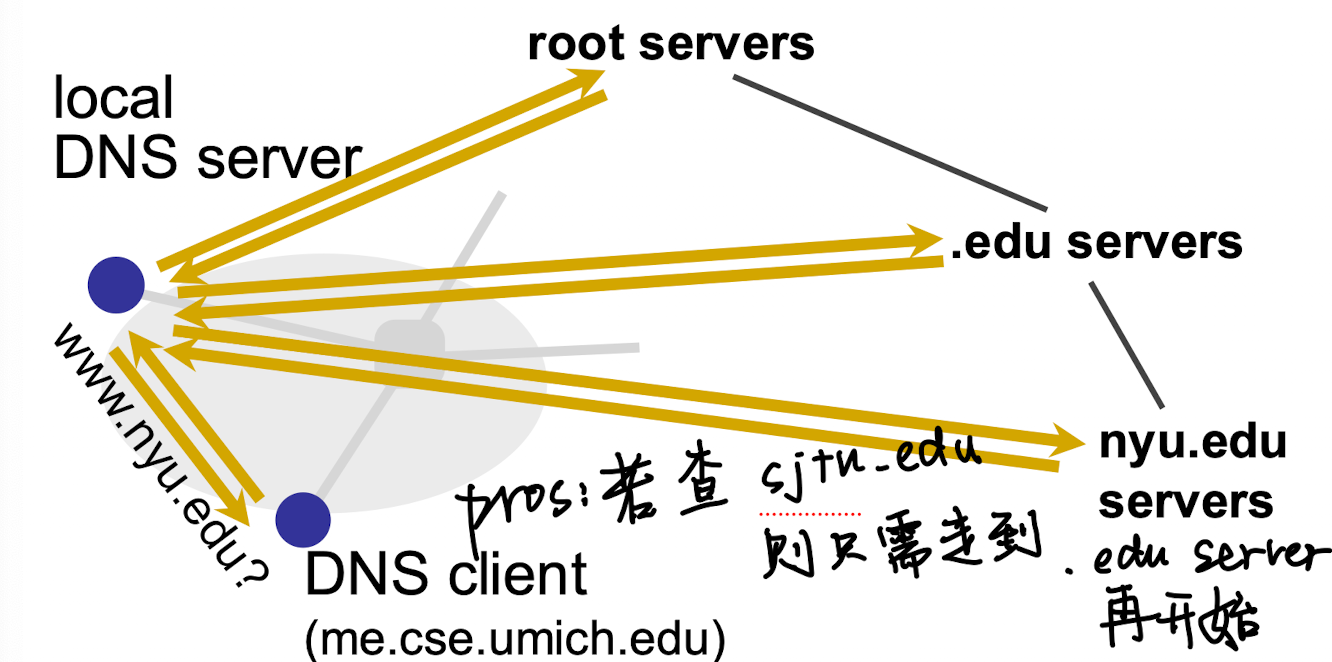
DNS 可靠性
通过复制(replicate) dns 服务器的内容将数据存储在多个子服务器中,只要一个服务器正常运行就可以正常映射
常常用 UDP 协议进行 query,因为其比 tcp 更加轻量化,可以更快的处理大量需求
指数退避exponential backoff: 指的是在处理故障服务器的时候第二次延长等待时间,从而防止对故障服务器过大的请求压力,给恢复服务器提供了时间和机会
DNS caching
通过将常见的存入 cache 提高访问效率,并且加入一个 time to live (TTL) 来存储有效时长,超过时长的 cache 设定为无效,从而被删除
视频流
观看视频的方式有两种:1. 下载之后播放 2. 在 bilibili 等在线平台观看
在线平台如果采用一个 GET 指令下载很大的文件有点不大现实,因为等待时间会很长,且用户可能会移动播放节点导致被跳过的部分浪费,且用户的清晰度可能会变,因此需要一个可变的视频流
视频缓冲区
定义一个缓冲区用来缓存下载的视频资源,如果缓冲区没有满,就优先下载填满之,视频本身不会播放;缓冲区满了之后前端开始播放,后端接着下载
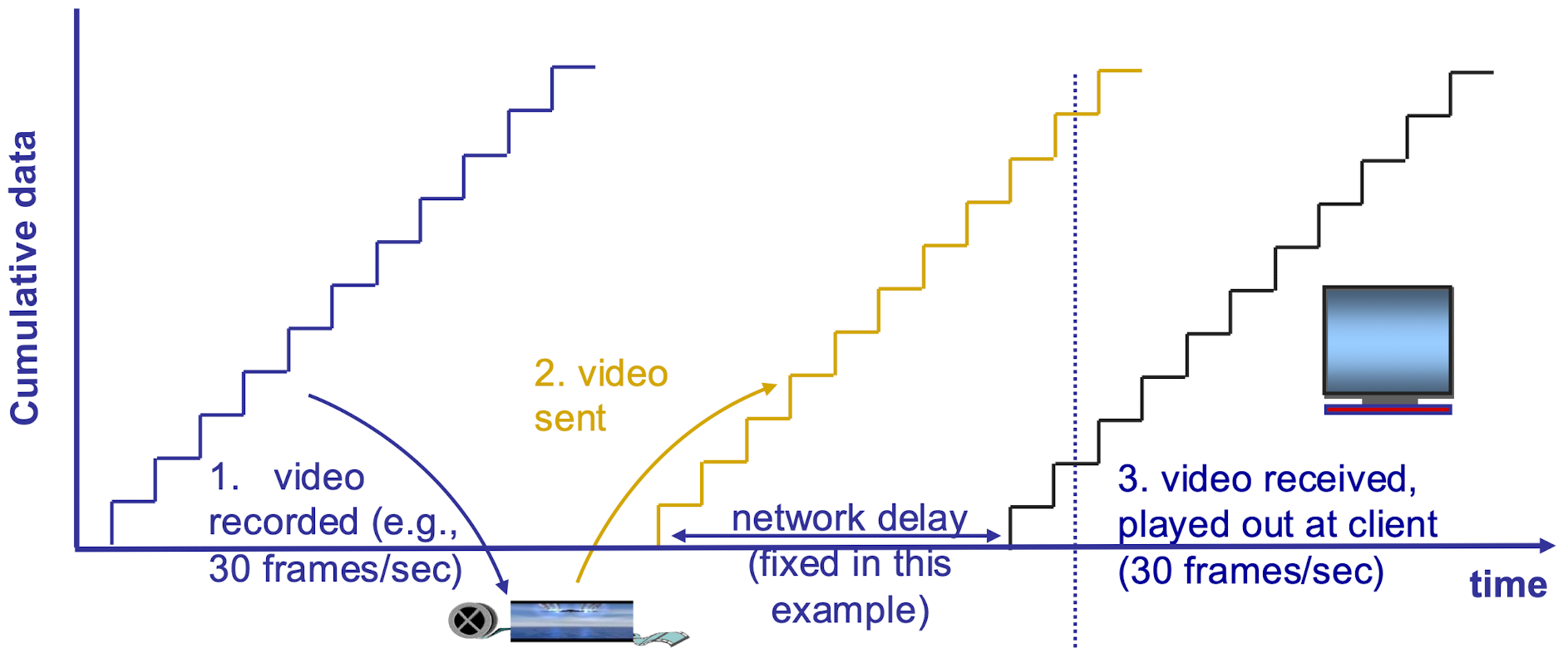
问题
- 不同用户的网络环境不同且可能变化,但是 http streaming 会导致所有用户的 bitrate 一致
- 不能动态的适应网络变化
DASH: dynamic adaptive stream over http
- 保持多个清晰度的视频资源,保存在一个清晰度菜单 (manifest) 中
- 客户端每次请求下载一个 chunk, 并且测量网速
- 如果网速小,下载低清晰度的视频
- 网速高下载高清晰度的视频
- Adaptive bit rate (ABR) 自适应比特技术: 实时根据带宽动态调整视频分辨率,从而确保流畅播放
Cloud System 云服务器系统
数据中心 Data Center
- 易于叠加扩大 Scale
- 需要容易组装
- 价格低廉
- 硬件高效的利用率
- 需要能容忍频繁的局部硬件故障
- 多租户模型 multi-tenancy 一个系统支持多个用户(或组织)同时运行,但每个用户的资源和数据彼此隔离
- 性能保障
- 用户之间隔离
- 可移植性,即可以从一个云服务器转移到另一个
分割聚合模型 Partition Aggregate
这是一种分布式计算模型,将任务数据分割成多个小块,每个小块分配一个工作节点进行处理,然后在向上聚合,直到得到最后结果
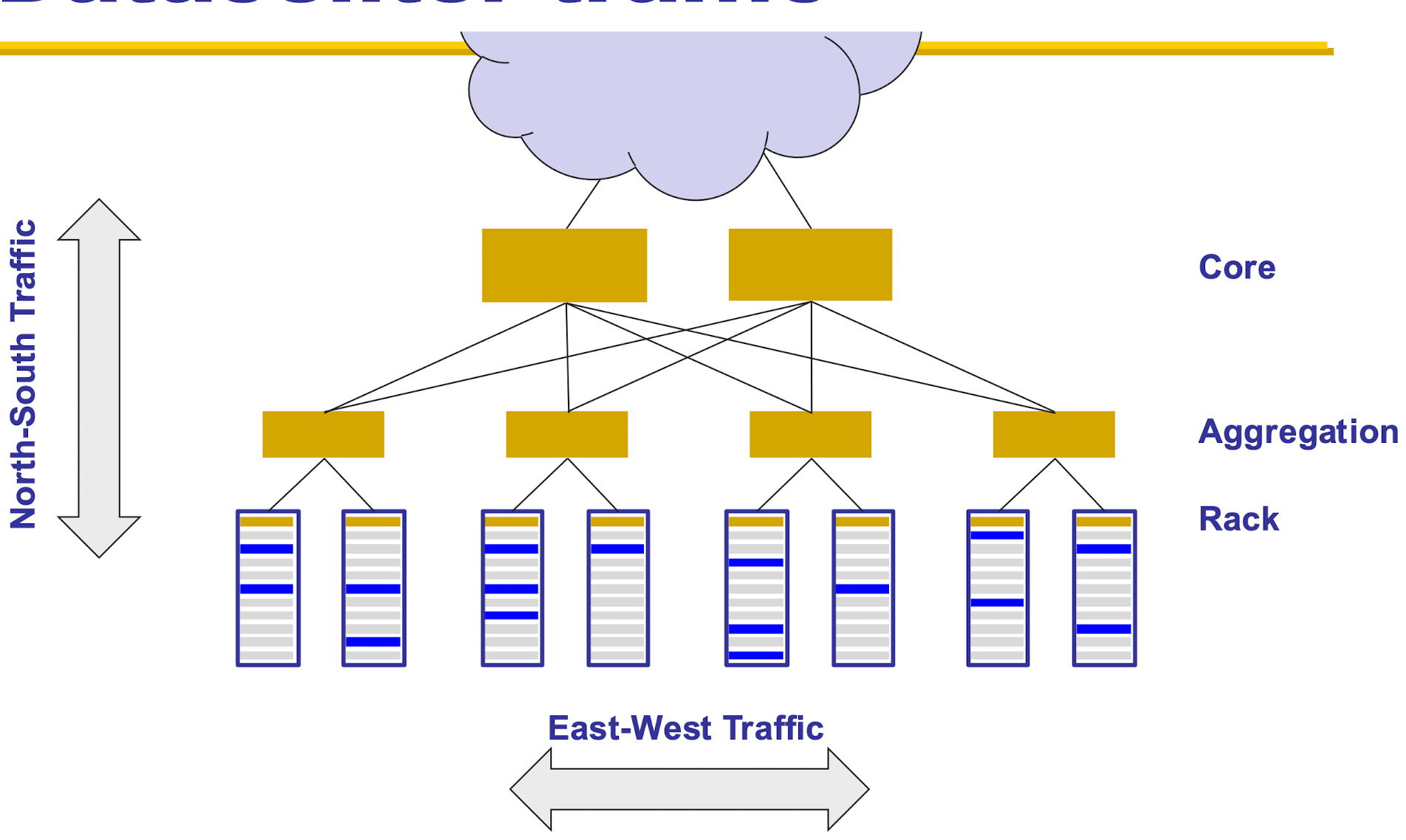
在顶层的服务器称为 core, 中间层称为聚合层 aggretation, 底层称为 rack 机架层
南北流量:数据中心内的服务器与外部网络(如用户设备、互联网)之间的流量
例如浏览器和中心服务器的交流
东西流量:数据中心内部的服务器之间的数据交换
数据中心网络抽象
可以将数据中心整体看作一个大的交换机,
大带宽的实现
采用二分带宽方法,将一个小的 aggregator 连接 2 个 rack 服务器
这样的拓扑结构可以实现较大的总带宽
但是传统的树状结构可能会存在问题:左子树对右子树的通信困难
解决方案:
- over-subscription: 上 link 小于下 link bw之和,这样会导致满负载的带宽小于底层 bw 之和
- o-s ratio: bw_under / bw_above
- better topology (clos topology): 将每一层 aggregation 都添加额外的一层 1/2 switch 数量的全连接层,用来持续映射
- 可以用到所有的path(link)
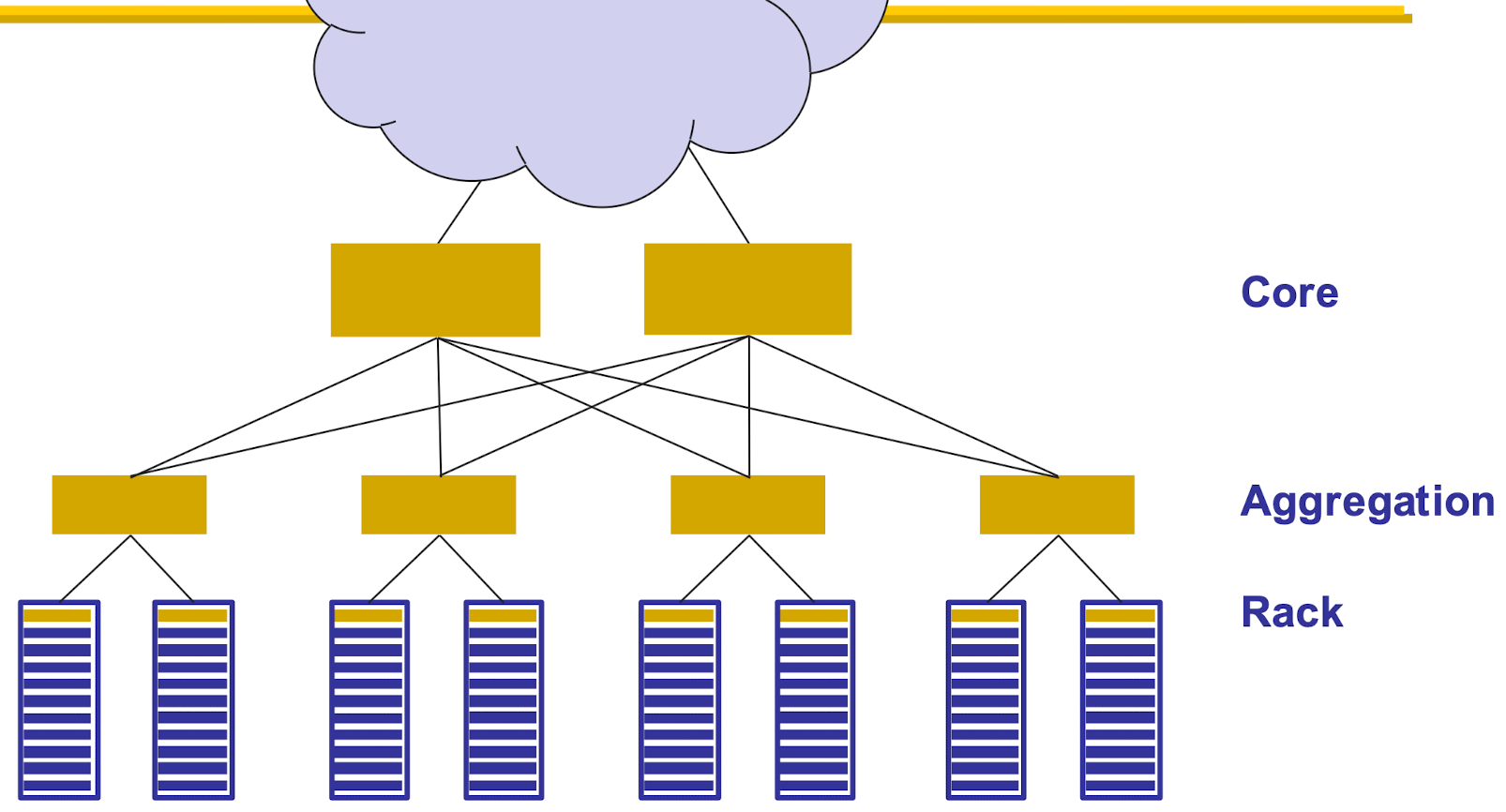
- 可以用到所有的path(link)
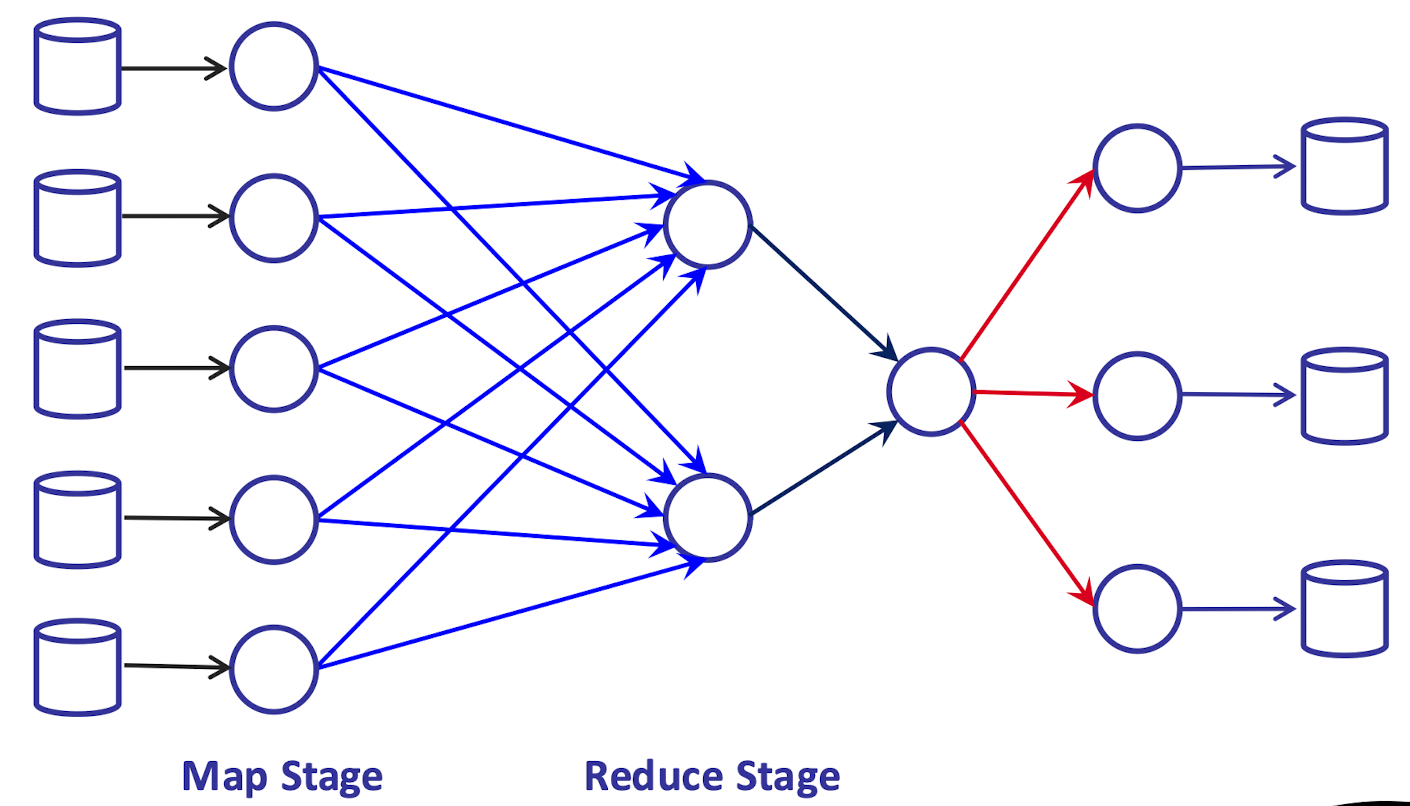
映射-归约模型 Map-Reduce
该方法常用来处理大量的数据集,首先将数据拆分成较小的部分,每个部分对应一个 mapper 经过映射之后进行中间键值重新分组 (分类聚集), 最后进行归约 reduce 得出最终结果