
9. 基本 GPU 架构
Data-Level Parallelism (DLP)
在前面的工作中我们主要学习的 并行架构 就是 pipelining
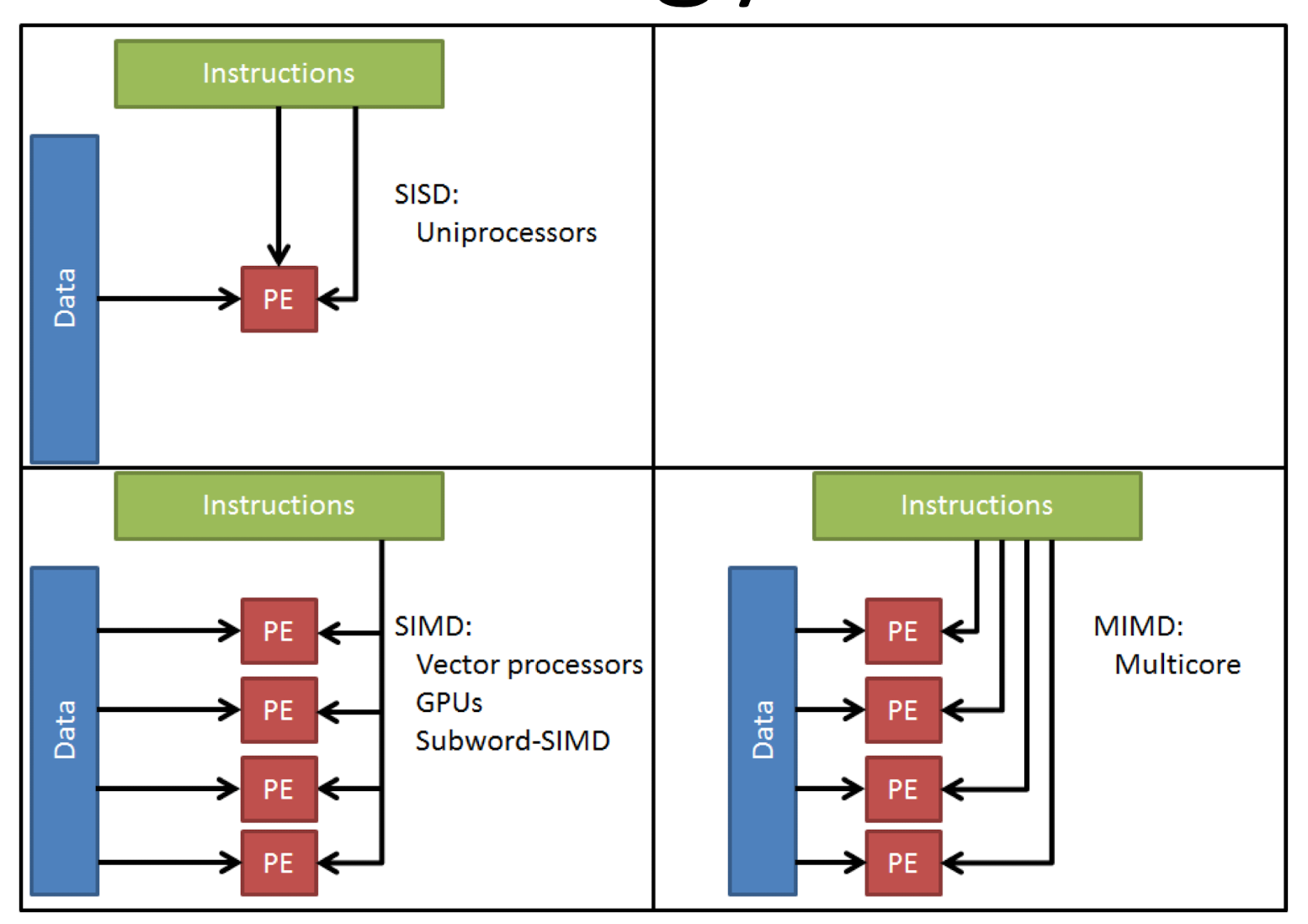
简单的做法就是并行使用多个 核 core 或者使用多个硬件结构实现并行,但是这里要讨论的是 数据层面的并行
在固有的处理器中,我们计算如下公式
1 | for(i = 0; i < 100; i++) |
很显然这一步可以用矩阵和向量等式进行优化
即表达式
那么接下来的问题就是如何用硬件快速计算向量
SIMD 方法论
基础方法称为 single insturction single data 处理,即每个指令获取一个对应的 data 部分,但是事实上我们可以从一个指令调用多个 变量(来自一个 vector 的多个相关变量) 这就是 simd (可以在单核处理器上面有出色表现)
当然也可以 多个指令调用多个变量, 这个取决于多核同时工作
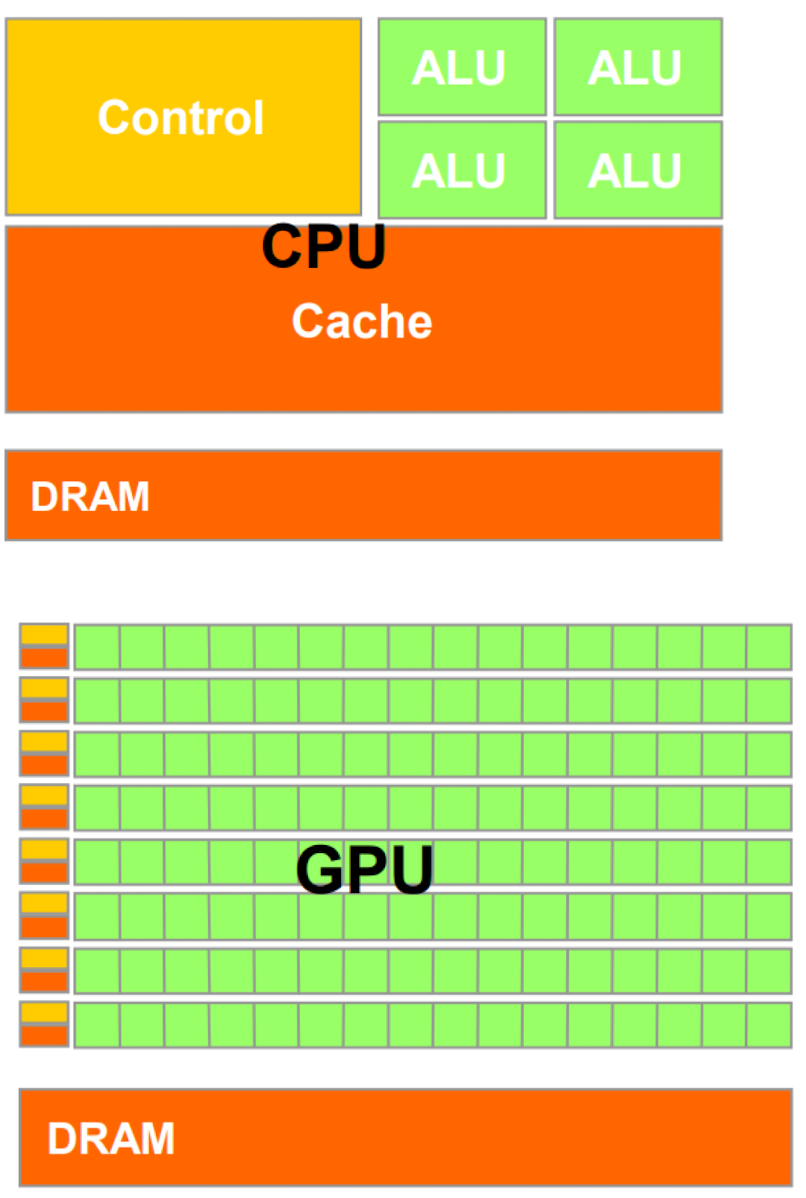
对比 cpu 和 gpu, 我们会发现当我们要处理大量相同类型的数据的时候 (例如图片的像素处理) gpu 会使用小 control 元件和小 cache 来实现同时 load 大量的数据 (这里不大会有 hazard 因为只是同时处理一个向量,其之间的相关关系非常少)
在 gpu 中会存在一个叫做 threadBlock 的结构,每个结构代表多个线程的集合
__global__ 关键字用于定义一个内核函数(kernel function),该函数将在 GPU 上执行,返回类型必须是 void
调用 global 函数时需要使用 CUDA 特有的语法,即在函数名后面使用三重尖括号 <<<...>>> 指定线程的布局
每个线程有各自的 private therad local memory, 每个 thread block 有各自的 block share memory , 总的 app 也会有一整个 global memory
cuda: Compute Unified Device Architecture
SIMT Model
single instruction multiple thread
assumption: 有超大量的元素在一个 vector 中需要执行类似的操作
认为每个 element 是一个 thread, 每个指令一次处理 10 - 100 个elements (类似 simd) 同时利用 pipline 的特点在下一个cycle 直接处理下一个 instruction. 这里读取指令可能会来自于其他的 thread (这样 cache miss 不会stall program, 因为 anyway 下一个指令已经开始执行了。当某个线程组 (warp) 在访问内存时遇到缓存未命中时,该 warp 不会停下来等待数据加载,而是会被搁置(suspended),并由调度器选择另一个准备好执行的 warp 来继续进行计算)
大概拥有 100 个 simd 内核来执行不同的 tread block
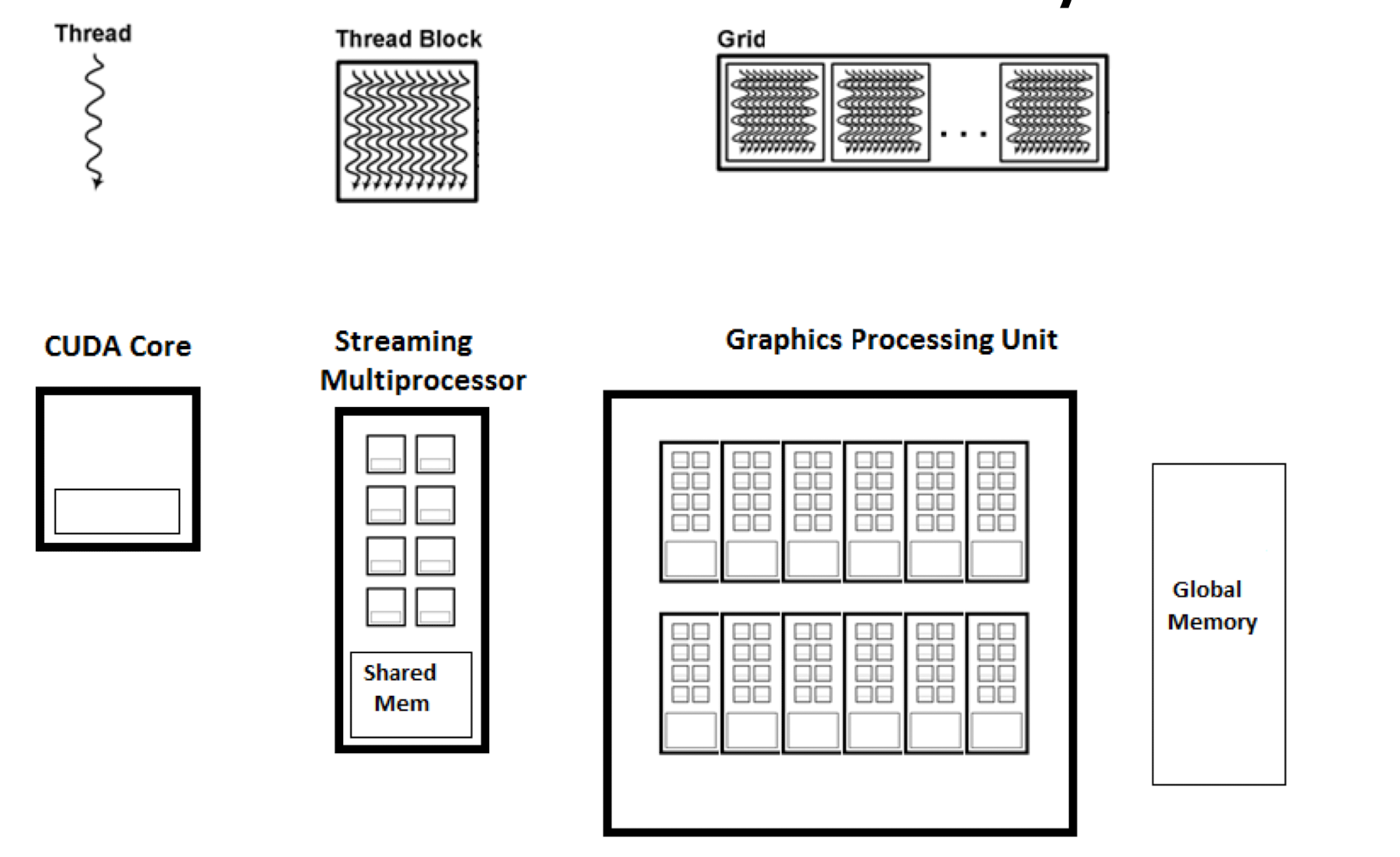
如图为 cuda 的基本架构,其中每个 core 可以处理一个线程,然后多个 core 组成了一个 streaming multiprocessor, 在这个内部的 share 内存的交换速度非常快,可以在 1 cycle 内进行数据的互换,因此遇到 miss 的时候可以快速换到另一个线程的指令进行执行而不是等待当前的解决
英伟达 isa
英伟达的汇编代码是一种 virtual assembly 因为其每一次迭代都会更换其实际的 isa 内容,因此 使用 虚拟汇编保证多代下伪代码一致可读
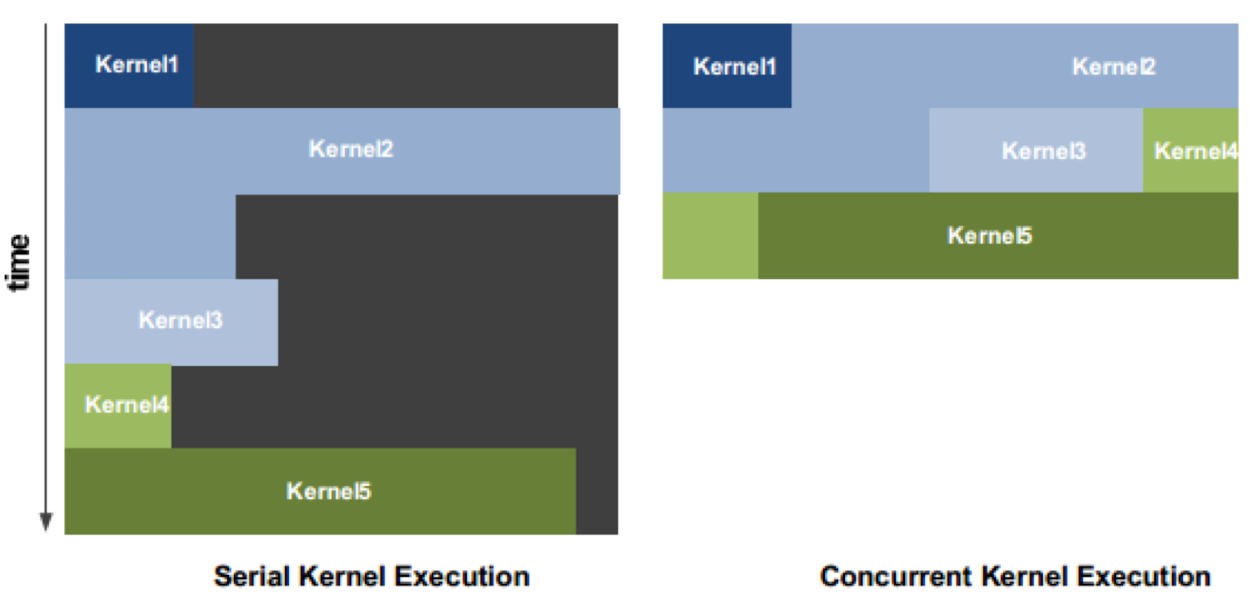
giga thread scheduler
不同于单核的调度器执行依赖于短板效应的 周期 = 最长指令用时,gpu 允许一个 cycle 内将多个 kernel 分别处理各自的内容或者处理存在依赖性的内容
双层 cache 结构
gpu 会使用两层 cache 结构 L1 和 L2 并且
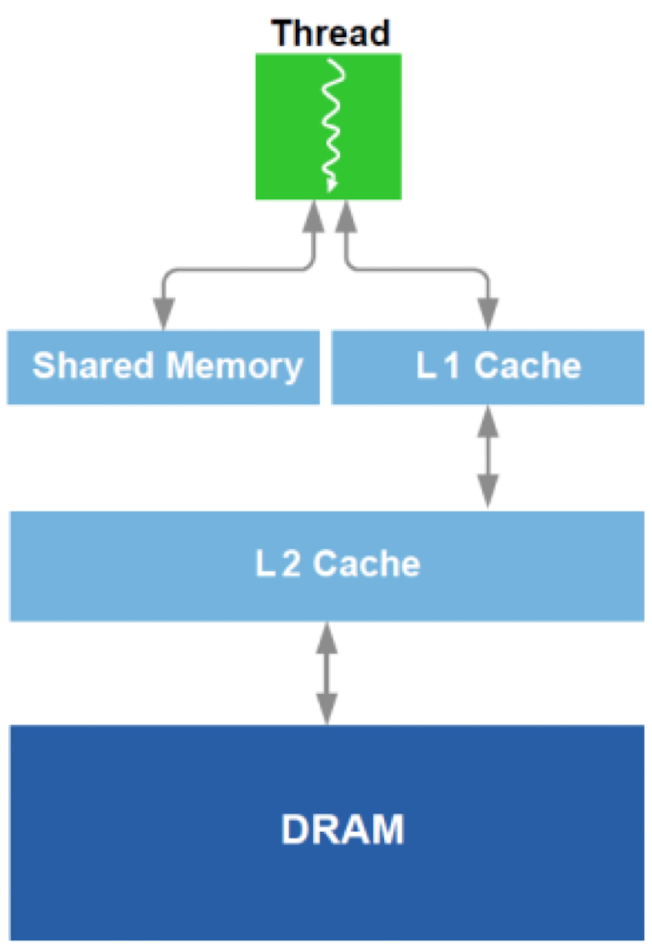
scratch pad
图像处理
由于显示屏可以看做上百万个 独立vertex 的组合,各个vertex 的计算方式独立
因此可以利用 gpu 进行并行处理运算
不规则并行
由于世界上常见的数据集逐渐变得稀疏(体量变大之后相关之间的 connection 逐渐减少) 例如随着 facebook 用户增加,人均好友量增大,但是 社交网图的稠密度是减少的
解决方案
拓扑法
cryptomining 加密货币挖矿
通过计算机的计算能力来验证并记录加密货币网络中的交易,从而获得加密货币奖励的过程
因为一个 gpu 可以同时猜测多个逆哈希过程的结果, 速度很快
缺点
过于耗电