
8. 缓存 cache
SRAM, DRAM, SSD
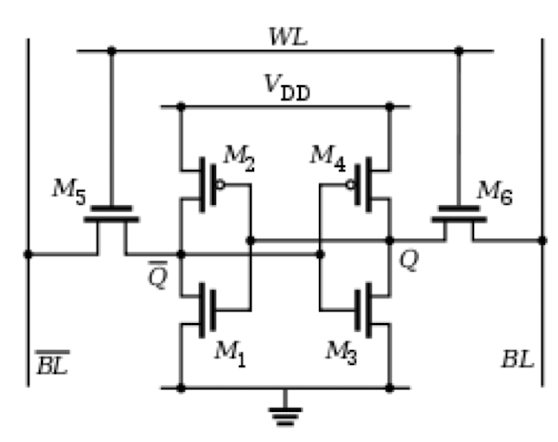
SRAM 静态随机访问内存
- 由六个三极管组成
- 脆弱volatile:需要常量的电压来保存数据
- 快速: 1ns 左右的数据访问时间
- 空间占用率低: 只能在芯片上存储 MB 大小的数据
DRAM 动态随机访问内存
- 每一个 bit 用一个 三极管和一个电容组成
- 需要常量的电压来保存数据
- 缓慢: 大约 50 ns 的访问时间
- 便宜,可以提供 GB 单位的内存空间
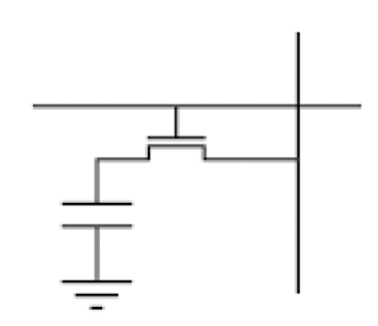
现代硬件结构中这个往往被用作是主要内存硬盘
Disk 光盘
硬件将数据存储在 磁电,通过光盘的旋转来进行数据获取
数据获取非常缓慢,约 3ms 的访问时间
不脆弱:即使没有电压也可以保存数据
固态硬盘 solid-state disk, SSD
相比光盘,访问时间快很多,大约 0.1 ms 的时间
十分便宜
总结
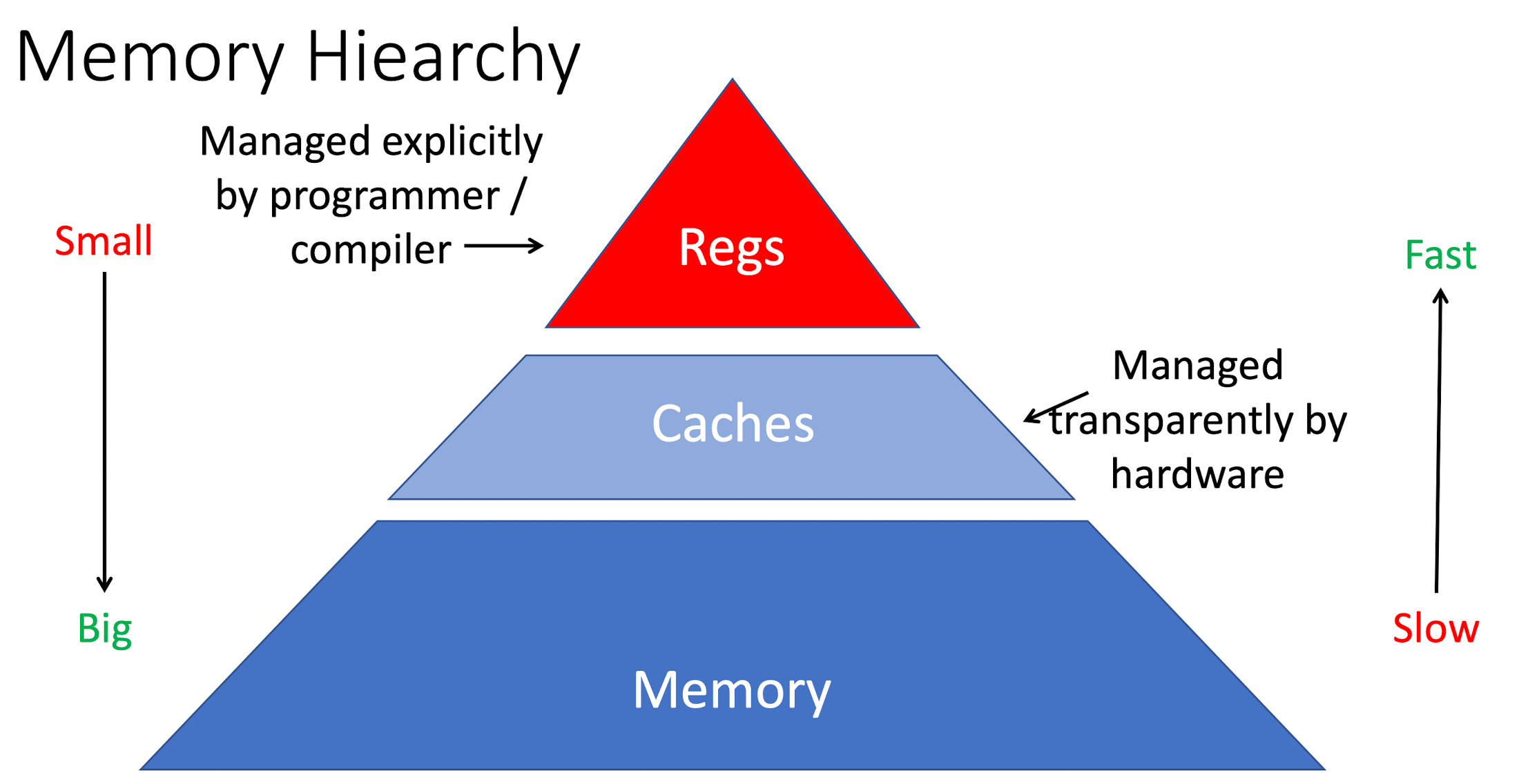
reg, cache, memory 的速度和内存大小的关系如下图:
缓存 Caches
功能
缓存存储了我们认为最有可能会被使用的数据, 从时间和空间维度,共有两种可能:
- 空间(spatial locality):最近被调用的数据的附近更有可能会被调用
- 时间(temporal locality):最近调用的数据可能会被再次调用, 例如 for 循环的迭代器
- 采取 least recently used value (LRU) 即最近调用的元素
存储结构
一般按照 tag + data + status bit 三个部分
tag 标签
一般存储地址, 用于从指令快速定位, 因为指令中往往带有目标内存的地址
这里一般认为是 O(1) 复杂度用硬件并行判断在 1 个 cycle 内找到是否有匹配
双层结构 金拱门双层吉士汉堡
将一个 tag 能存储的数据量乘2, 同时保证其寻址范围不变, 那么可以将每 2 位进行存储, 并用 /2 和 %2 来分别计算 tag 和 tag 内相对位移 offset 的大小
优点
- 提高了 hit 的概率, 因为存入 tag = 1 的数值可以覆盖两个数据
- 这一步侧面也解决了 spatial locality 的问题,对于数组的情况下非常好用
预测结果评价
加入缓存之后数据从内存中读取到寄存器分为两个步骤: memory -> cache -> reg
定义 hit 为调用数据处于缓存内部,时间花费较小
miss 为调用数据来自内存,时间花费较大
hit rate = hit / total
在硬件水平不变的情况下提高 hit rate 可以让运行速度快很多
例题
一个缓存的总容量是 8B, 其中 block 尺寸为 2B 使用 LRU 逻辑存储, 设地址的尺寸是 16b 且是 byte addressable
地址尺寸:指 tag + offset 占用的长度, 由于是 byte 寻址且 block 的尺寸是 2B 因此每个 block 有 2 个数据段, 因此 offset 占长度为 1b
tag 长度:为 地址长度 - offset = 15b
block 数量:总共 8B 一个 2B 因此有 4 个
注:data 长度和tag/地址长度无关
overhead 大小:首先 地址本身是 16 位, 其中 tag 占据 15 位; 其次有 LRU 计数表示远近, 从而在选取哪个寄存器替换的时候可以明确更换目标, 占据尺寸 由于这里有 4 个 block 因此 n=4 所以 LRU 占据尺寸 2b,共 17b
考虑 valid 1b; 考虑 dirty 1b
写回优化 writeback optimization
write-through
在遇到 sw 指令的时候,首先从 reg 更新数据到 cache 然后通过再写入到 memory 中实现更改
write-back
在数据标注部分额外用一位的 dirty (d) 标识符进行标注,当数据从 mem load 到 cache 的时候初始化为 0, 每次 sw 只将新数据写入 cache 而不写入 mem 从而加快运行速度,只有当需要依照 lru 原则 pop 出最老元素的时候若 d == 1 则将数据写入 memory (这里一般默认 block 内所有数据段共用一个 d 位, 因此写入是整个 block 一起写入而不是单个更换元素写入)
注: 二者性能不具有绝对优势
write-back 并不一定会比 write-through 拥有更小的写入内存次数, 只有在需要多次更换一个变量的数值的时候其性能会明显更好 (例如 counter)
cache-mem 查找速度
由于在原来的情况下,可能需要线性查 cache 的 tag 表格中是否有对应 tag 的存在,时间复杂度可能会较大,但是联系 unoredered_map 的方法思路可以优化查找速度
将 memory 分块成几个内存块, 那么所有表示查找的数据段可以拆分成三部分:
| tag | line | offset |
|---|
首先 tag 表示的是第 # 个代码块, line 表示的是代码块内第 # 个 block, offset 仍然表示 block 内部的偏移
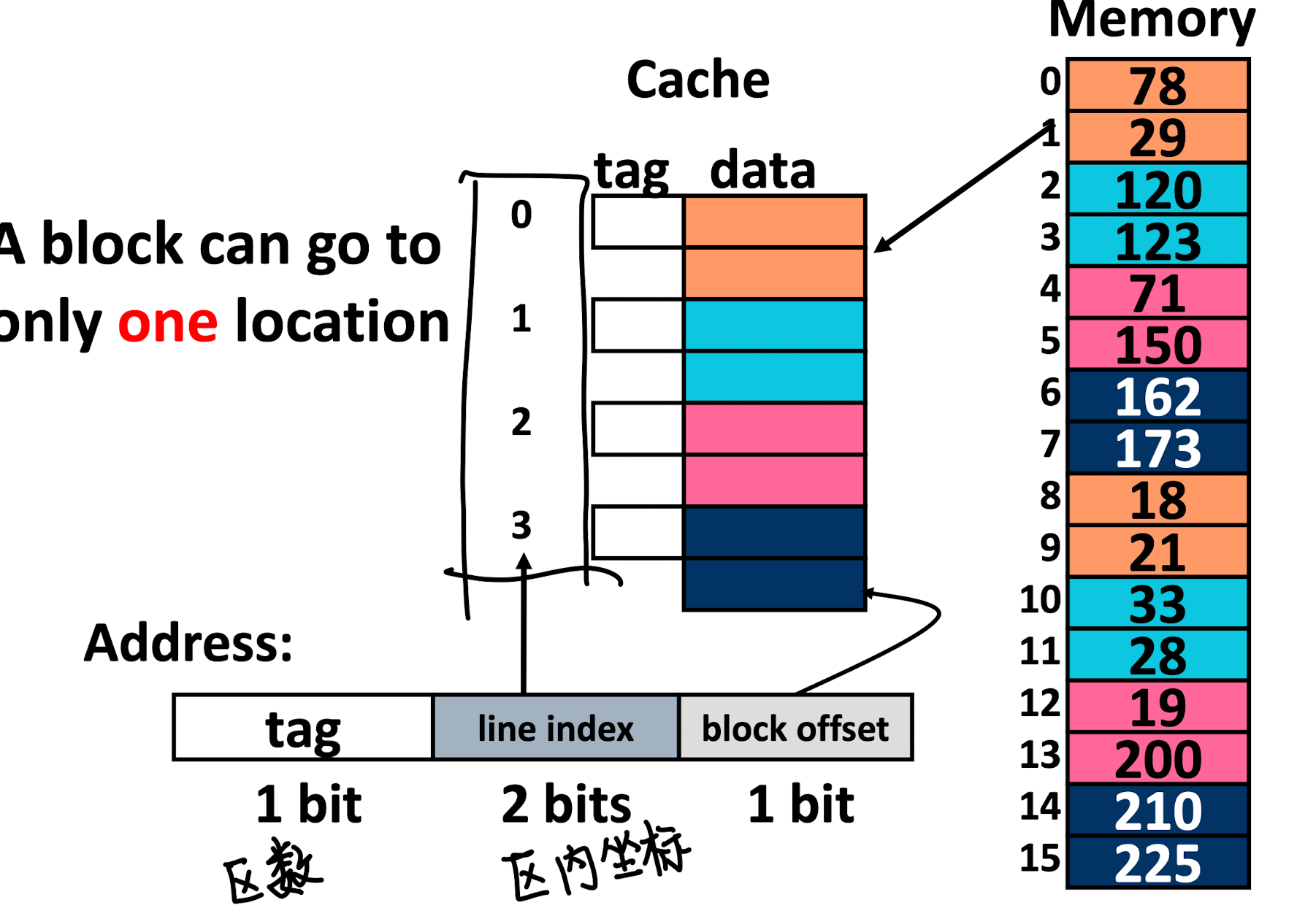
在这张图片中,不同颜色就表示了一个对应的 line index, 注意 cache 和 memory 中都有对应的颜色,也就是说即使 cache 没有满,前后两次来自同一个颜色的 line 的数据也只能覆盖掉 (这可能会导致频繁替换同一块缓存而导致数据吞吐速度下降)
这相比 “并行标签查找” 的方法速度更快且时间复杂度唯一