
7. 流水线指令 pipeline
目的
可以压缩执行时间,从单循环的长周期短cpi和多循环的短周期长cpi结合得到
短周期 + 短 cpi (等于 多循环的cpi)
特点
在 multi-cycle 的电路基础上,添加一个 对应每个 stage 的寄存器, 一共四个
最大同时执行指令的次数: 5 (即 if, id, ex, mem, wb 各一个同时进行)
总 cycle 数
instr 数 + pipeline_stage 数 - 1
pipeline 问题
data hazard
- data dependency: 指令依赖于前面某个指令的结果
- data hazard: 一个指令如果不进行额外处理就会遇到错误情况
解决方案
- 代码主动避免 avoid
- 检测与贮存 (处理器主动等待) detect and stall
- 自动修复为标准值 detect and forward
1. 代码主动避免
加入 noop 轮空 cycle
问题
- 硬件版本不同需要的 noop 数量不同 (新的硬件可能 pipeline 更长,需要的noop会变)
- 程序体变大很多
- 执行速度变慢
2. 检测与贮存 Detect and Stall
detect
比较 regA 和 regB 与先前的 destReg 是否相同,如果相同说明存在先写入后读取的过程
stall
- 将当前步骤留在 fetch/decode (在 execute 之前,且二者应该保持一致停止否则会有 pc 经过但是没有写入 decode 流程的指令)
- 处理器插入 noop
对应硬件结构
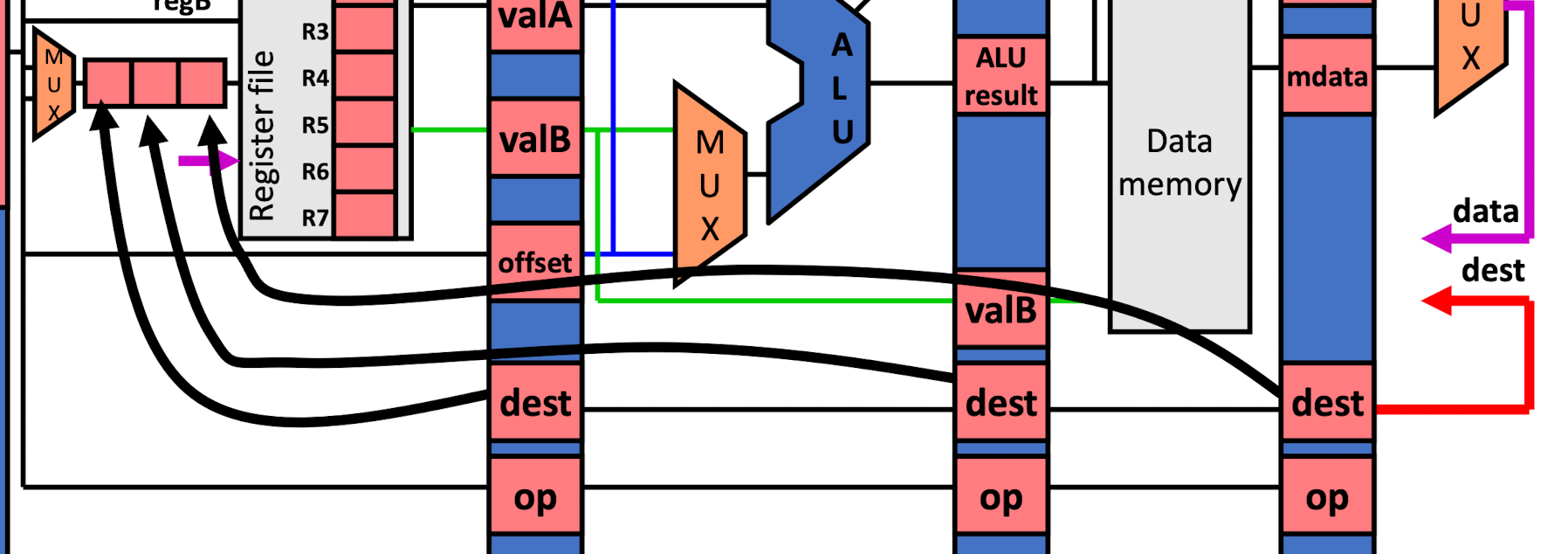
也就是将前三个 destReg 都先存储在 reg 里面,然后利用一个 compare module 进行等号比较,硬件结构如下
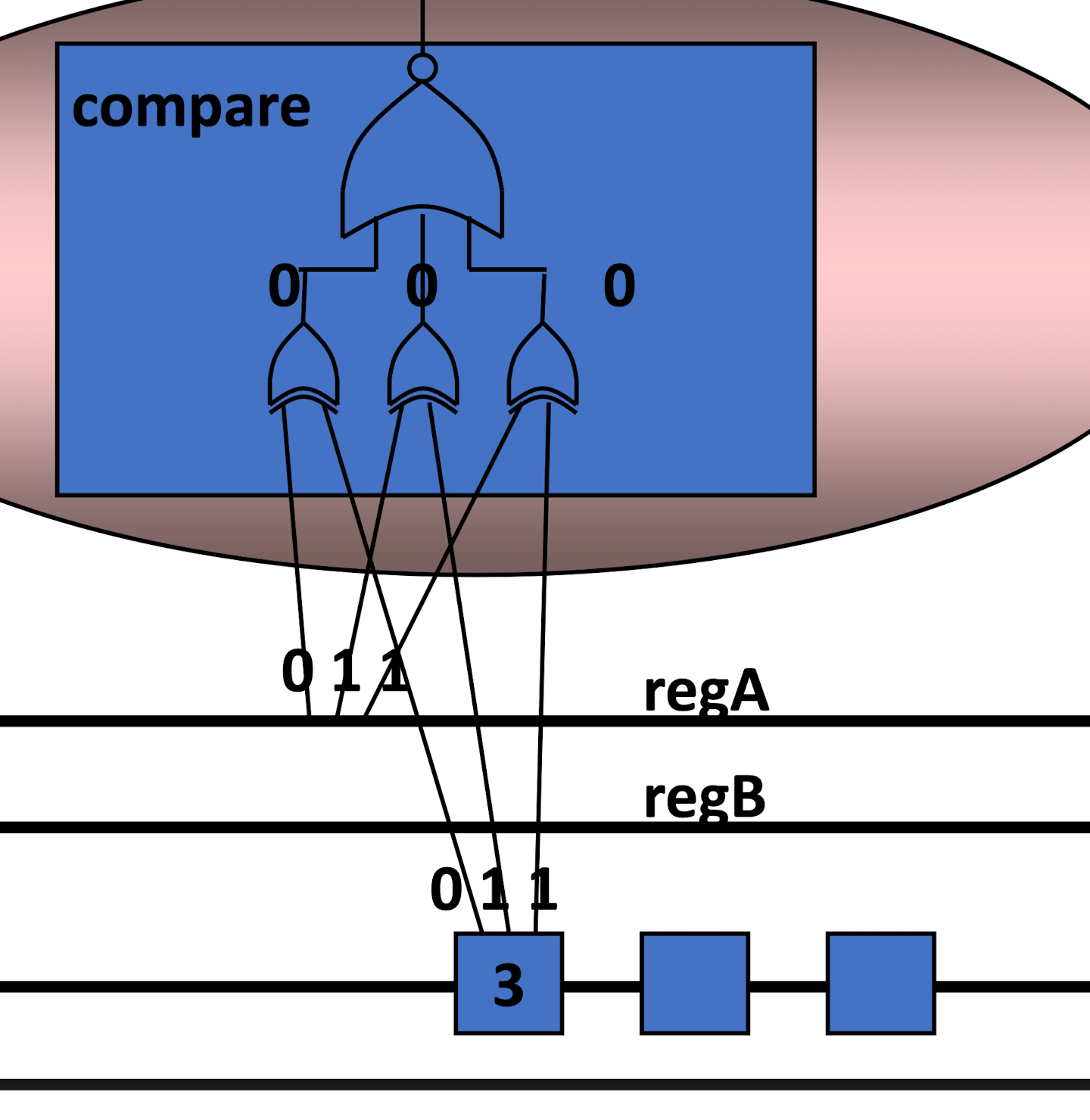
再将结构得到的逻辑值取反传入 pc 的 counter 以及 fetch (实现上述 stall 的第一条要求) 得到被动 noop 指令的执行 (指令轮空)
注: 默认 wb 和 id 同时执行 (即同时写入和阅读) 不会造成任何问题, 那么 DAS 步骤下我们会将 add/nor/lw 后面的步骤延后直到当前指令达到了 wb
terminology
以下五个表示 pipeline 的五个状态
- IF: instruction fetch
- ID: instruction decode
- EX: excution
- WB: write back
- Mem: 写入内存
相邻状态之间会存在一个状态寄存器
DAS 方法的问题
- cpi 在每次检测到 hazard 的时候都会变大
- 优化方向: 或许可以将上一步计算出来的值用另一个线路返回从而可以不写入而直接利用
3. 检测与勇往直前 Detect and Forward
从 alu 计算结果,memory 输出分别连一根线到 alu 的输入 (两个引脚各自连接) 这样我们就可以跳过 wb 这一步 (指将数据流直接返回到 mux 层, 标准写入 reg 的流程不变),从而直接在计算结果的时候返回写入到 reg 里,即 add / nor 指令不延后; lw / sw 延后1帧
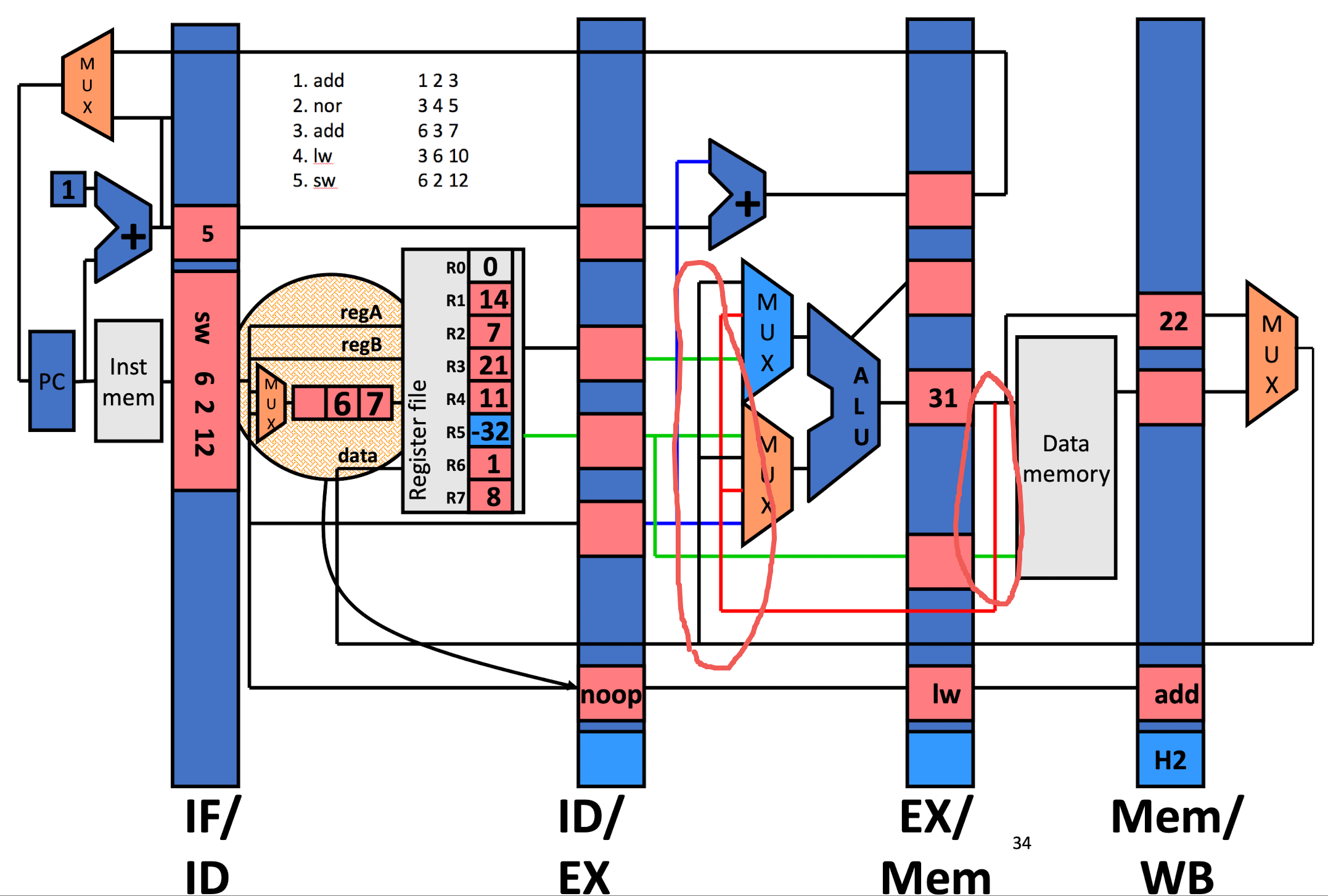
这里并不是延后两帧或者类似 DAS 的三帧,因为这里的后一个指令遵循 forward 准则向前进,并且及时利用后面的数据流填补当前的数据需求从而实现无延后
DAF 时间计算
lw 指令 需要将 cpi 变成 2
add/nor/sw/beq 本身并不需要增加 cpi
control hazard
对于 beq 和 jalr 的指令的跳转问题: 下一行指令如何执行?
branch 的判断在 mem 步骤执行其数据控制结果 (不会到 wb 这一步)
分类
- avoid
- detect and stall
- speculate and squash-if-wrong
1. avoid 主动避免
要么没有 beq 指令,要么加入 noop
2. Detect and Stall
detect
检查是否有 beq 和 jalr 指令
stall
将当前指令停留在 fetch 插入 noop
对于一个 beq 指令需要插入三个 noop
这个和 data hazard 的区别是,DH 会将程序卡在 decode 阶段,但是 CH 会将程序卡在 fetch 阶段从而会多一个 noop
优化思路
- branch 的方向性可以 guess
- 如果不 branch 那么可以让后面的指令先一步执行起来并且存储在新的 path 里面
3. Speculate and Squash 猜测与压制
将 pipeline 中原本用于存储指令的中间状态寄存器的输入端添加一个 mux 如果 alu 返回输入相等,表示要 branch 则用 mux 将后来的指令写成 noop
not-taken 速率提升
beq 的 cpi : not-taken 的步长 1; taken 的步长 4 (增加3个noop)
长 pipeline 的时间损耗
- control hazard 的复杂度是看什么时候 branch 被 resolved
- data hazard 的复杂度是看 memory 结束到 execute 步骤开始的 stage 跨度
猜的艺术 – 目标预测
最常用的 branch 指令往往出现在 loop 中,因此大多情况下其 是否接受的逻辑在多次判断中是保持一致的
这个方法称为 分枝目标缓冲器 BTB (branch target buffer)
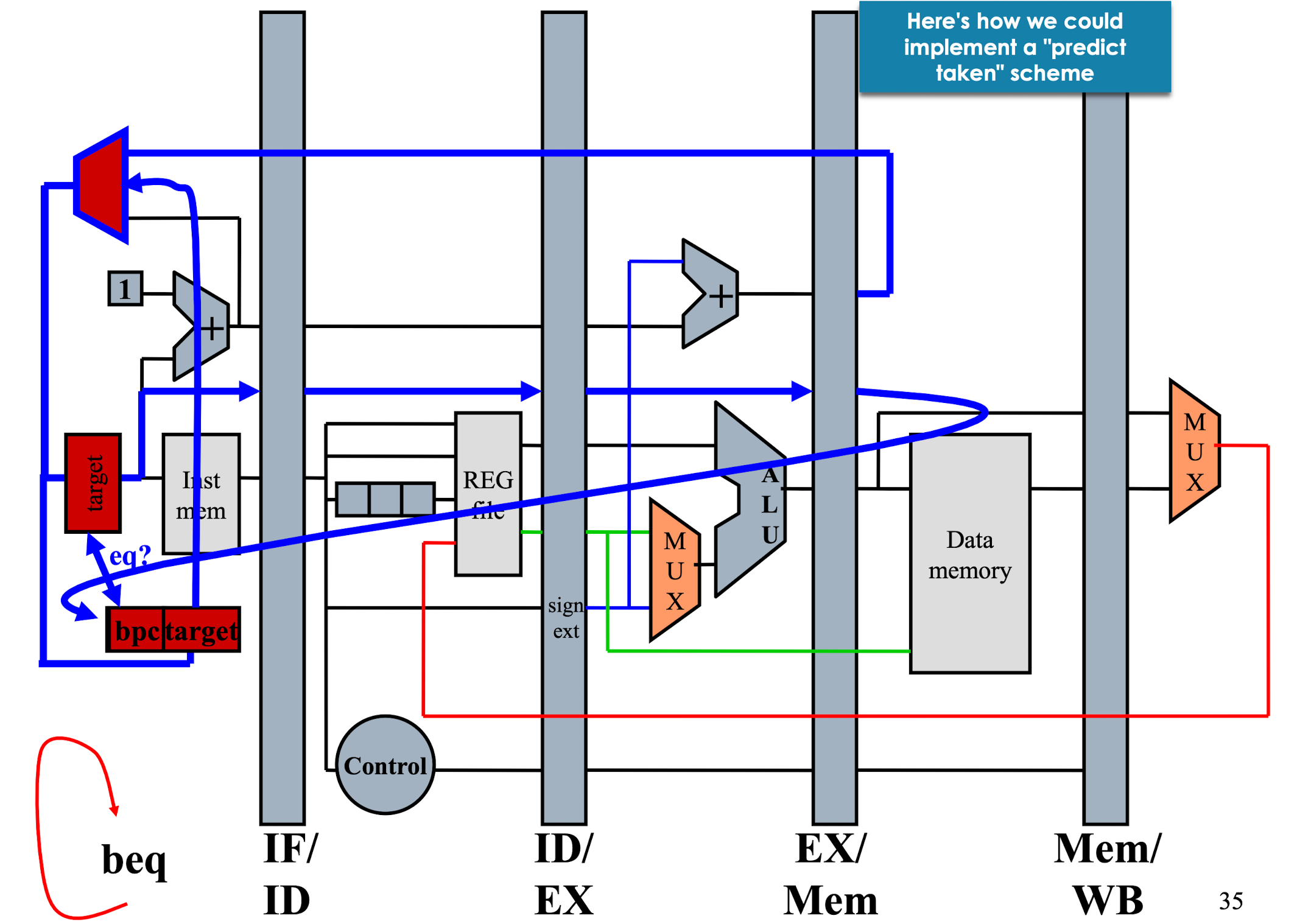
如上图所示,每次 branch 会将结果存储到 bpc 和 target 寄存器中,bpc 存储 branch 的 pc; target 存储目标值.
如果 bpc 的数值等于上次判断的 pc 以及 target 确定那么可以先执行 target 存储的地址
赌神的最爱 – 方向预测
定义 beq 两个输入的相等性为 方向,分为 静态预测 static 和动态预测 dynamic
静态预测 static
假设某一次执行中 prediction 永远不变
即要么 always-taken,要么 always-not-taken 要么 forward not taken, backward taken (BTFN, 因为 loop 是 backward 的往往会执行)
但是当输入是 TNTNTNTNTNTNTN… (T = Taken; N = Not-Taken) 那么精确度会非常低
预测时间对比
对于占比 p 的指令会进行 branch 的情况下, 对比不同静态预测指令的快慢, 额外步长公式为:
- predict taken: (1-p) * 3
- predict not taken: p * 3
也就是预测错误部分的时长需要 3 倍,预测正确的指令不需要延迟 (这些问题可以在 compile time 被解决即被编译器嵌入到代码层因此在执行的时候不会被认为花费额外时间, 这些地址往往会存储在 btb 中, 通过查询 btb 快速跳转到目标地址)
动态预测 dynamic
用一个状态机进行描述预测目标; 分为 strongly not taken/ strongly taken; weakly taken/ weakly not taken
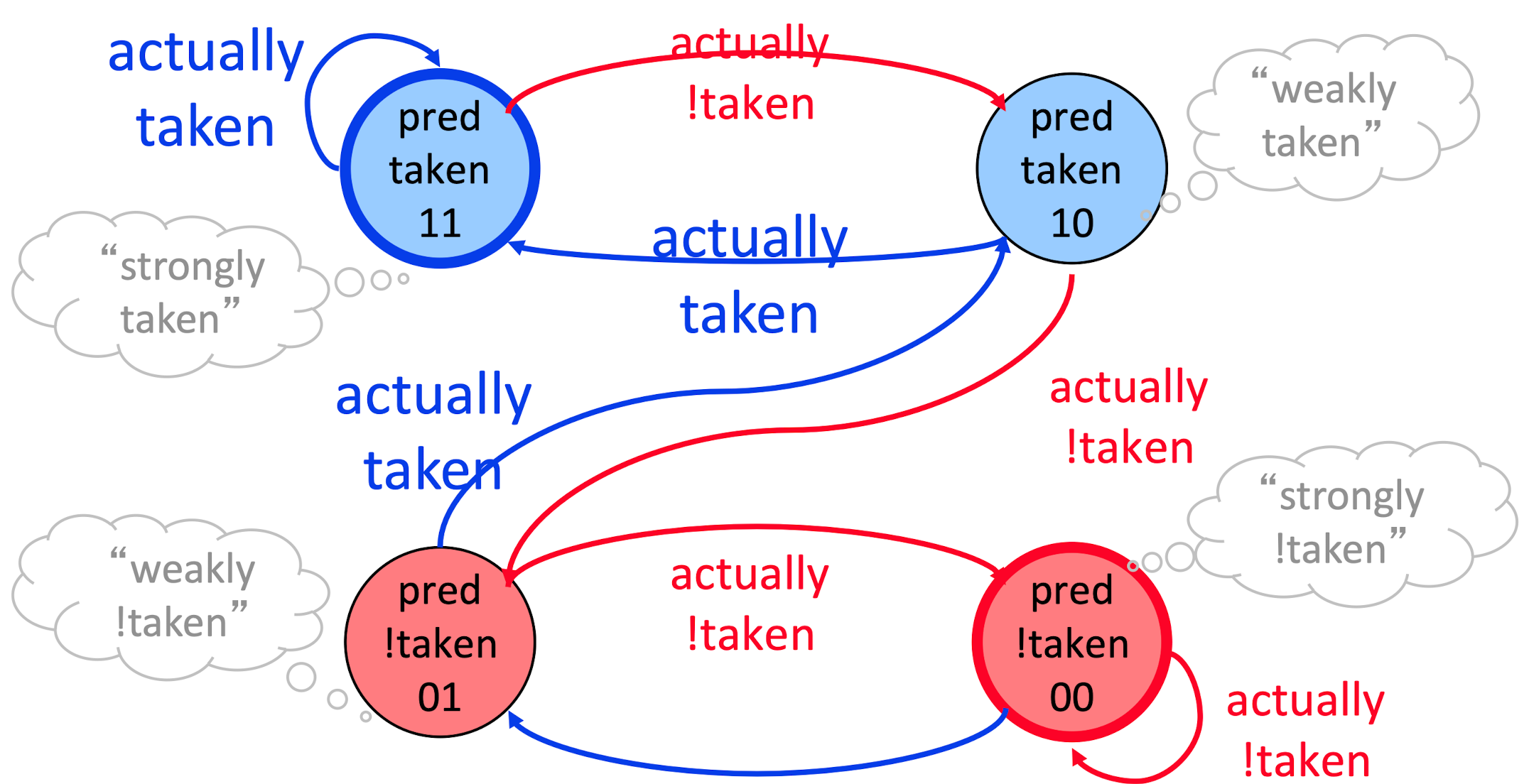
假设 两个 taken 状态的预测都是 take branch; 而两个 not taken 的状态都是 not taken; 其中strong 预测错了变成 weak; weak 预测错了变成对向的 strong (粉转路转黑)